 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataCube: A Video Retrieval Platform via Natural Language Semantic Profiling
Feb 18, 2026Large-scale video repositories are increasingly available for modern video understanding and generation tasks. However, transforming raw videos into high-quality, task-specific datasets remains costly and inefficient. We present DataCube, an intelligent platform for automatic video processing, multi-dimensional profiling, and query-driven retrieval. DataCube constructs structured semantic representations of video clips and supports hybrid retrieval with neural re-ranking and deep semantic matching. Through an interactive web interface, users can efficiently construct customized video subsets from massive repositories for training, analysis, and evaluation, and build searchable systems over their own private video collections. The system is publicly accessible at https://datacube.baai.ac.cn/. Demo Video: https://baai-data-cube.ks3-cn-beijing.ksyuncs.com/custom/Adobe%20Express%20-%202%E6%9C%8818%E6%97%A5%20%281%29%281%29%20%281%29.mp4
Scaling Towards the Information Boundary of Instruction Set: InfinityInstruct-Subject Technical Report
Jul 09, 2025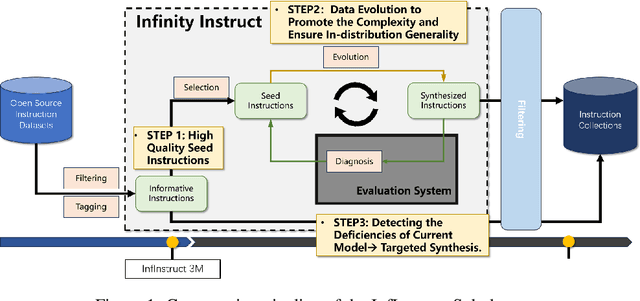
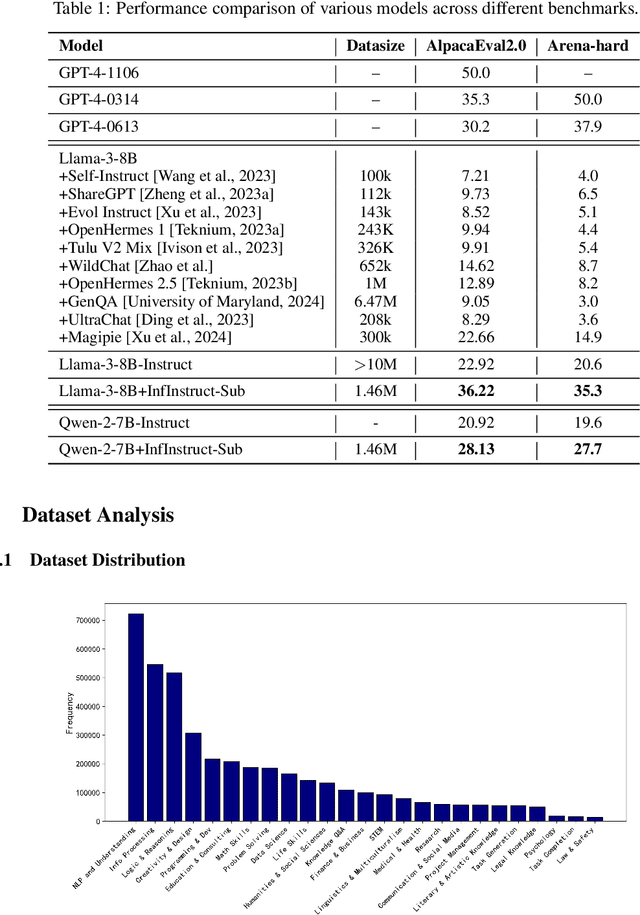

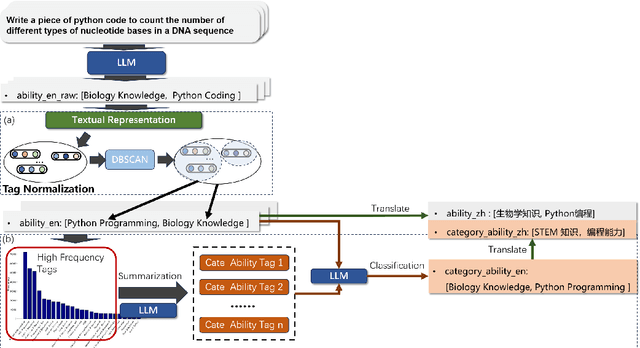
Instruction tuning has become a foundation for unlocking the capabilities of large-scale pretrained models and improving their performance on complex tasks. Thus, the construction of high-quality instruction datasets is crucial for enhancing model performance and generalizability. Although current instruction datasets have reached tens of millions of samples, models finetuned on them may still struggle with complex instruction following and tasks in rare domains. This is primarily due to limited expansion in both ``coverage'' (coverage of task types and knowledge areas) and ``depth'' (instruction complexity) of the instruction set. To address this issue, we propose a systematic instruction data construction framework, which integrates a hierarchical labeling system, an informative seed selection algorithm, an evolutionary data synthesis process, and a model deficiency diagnosis with targeted data generation. These components form an iterative closed-loop to continuously enhance the coverage and depth of instruction data. Based on this framework, we construct InfinityInstruct-Subject, a high-quality dataset containing ~1.5 million instructions. Experiments on multiple foundation models and benchmark tasks demonstrate its effectiveness in improving instruction-following capabilities. Further analyses suggest that InfinityInstruct-Subject shows enlarged coverage and depth compared to comparable synthesized instruction datasets. Our work lays a theoretical and practical foundation for the efficient, continuous evolution of instruction datasets, moving from data quantity expansion to qualitative improvement.
CI-VID: A Coherent Interleaved Text-Video Dataset
Jul 02, 2025Text-to-video (T2V) generation has recently attracted considerable attention, resulting in the development of numerous high-quality datasets that have propelled progress in this area. However, existing public datasets are primarily composed of isolated text-video (T-V) pairs and thus fail to support the modeling of coherent multi-clip video sequences. To address this limitation, we introduce CI-VID, a dataset that moves beyond isolated text-to-video (T2V) generation toward text-and-video-to-video (TV2V) generation, enabling models to produce coherent, multi-scene video sequences. CI-VID contains over 340,000 samples, each featuring a coherent sequence of video clips with text captions that capture both the individual content of each clip and the transitions between them, enabling visually and textually grounded generation. To further validate the effectiveness of CI-VID, we design a comprehensive, multi-dimensional benchmark incorporating human evaluation, VLM-based assessment, and similarity-based metrics. Experimental results demonstrate that models trained on CI-VID exhibit significant improvements in both accuracy and content consistency when generating video sequences. This facilitates the creation of story-driven content with smooth visual transitions and strong temporal coherence, underscoring the quality and practical utility of the CI-VID dataset We release the CI-VID dataset and the accompanying code for data construction and evaluation at: https://github.com/ymju-BAAI/CI-VID
Reinforced Internal-External Knowledge Synergistic Reasoning for Efficient Adaptive Search Agent
May 12, 2025Retrieval-augmented generation (RAG) is a common strategy to reduce hallucinations in Large Language Models (LLMs). While reinforcement learning (RL) can enable LLMs to act as search agents by activating retrieval capabilities, existing ones often underutilize their internal knowledge. This can lead to redundant retrievals, potential harmful knowledge conflicts, and increased inference latency. To address these limitations, an efficient and adaptive search agent capable of discerning optimal retrieval timing and synergistically integrating parametric (internal) and retrieved (external) knowledge is in urgent need. This paper introduces the Reinforced Internal-External Knowledge Synergistic Reasoning Agent (IKEA), which could indentify its own knowledge boundary and prioritize the utilization of internal knowledge, resorting to external search only when internal knowledge is deemed insufficient. This is achieved using a novel knowledge-boundary aware reward function and a knowledge-boundary aware training dataset. These are designed for internal-external knowledge synergy oriented RL, incentivizing the model to deliver accurate answers, minimize unnecessary retrievals, and encourage appropriate external searches when its own knowledge is lacking. Evaluations across multiple knowledge reasoning tasks demonstrate that IKEA significantly outperforms baseline methods, reduces retrieval frequency significantly, and exhibits robust generalization capabilities.
Exploiting Contextual Knowledge in LLMs through V-usable Information based Layer Enhancement
Apr 22, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, yet they often struggle with context-faithfulness generations that properly reflect contextual knowledge. While existing approaches focus on enhancing the decoding strategies, they ignore the fundamental mechanism of how contextual information is processed within LLMs' internal states. As a result, LLMs remain limited in their ability to fully leverage contextual knowledge. In this paper, we propose Context-aware Layer Enhancement (CaLE), a novel intervention method that enhances the utilization of contextual knowledge within LLMs' internal representations. By employing V-usable information analysis, CaLE strategically amplifies the growth of contextual information at an optimal layer, thereby enriching representations in the final layer. Our experiments demonstrate that CaLE effectively improves context-faithful generation in Question-Answering tasks, particularly in scenarios involving unknown or conflicting contextual knowledge.
Training Data for Large Language Model
Nov 12, 2024In 2022, with the release of ChatGPT, large-scale language models gained widespread attention. ChatGPT not only surpassed previous models in terms of parameters and the scale of its pretraining corpus but also achieved revolutionary performance improvements through fine-tuning on a vast amount of high-quality, human-annotated data. This progress has led enterprises and research institutions to recognize that building smarter and more powerful models relies on rich and high-quality datasets. Consequently, the construction and optimization of datasets have become a critical focus in the field of artificial intelligence. This paper summarizes the current state of pretraining and fine-tuning data for training large-scale language models, covering aspects such as data scale, collection methods, data types and characteristics, processing workflows, and provides an overview of available open-source datasets.
Beyond IID: Optimizing Instruction Learning from the Perspective of Instruction Interaction and Dependency
Sep 11, 2024



With the availability of various instruction datasets, a pivotal challenge is how to effectively select and integrate these instructions to fine-tune large language models (LLMs). Previous research mainly focuses on selecting individual high-quality instructions. However, these works overlooked the joint interactions and dependencies between different categories of instructions, leading to suboptimal selection strategies. Moreover, the nature of these interaction patterns remains largely unexplored, let alone optimize the instruction set with regard to them. To fill these gaps, in this paper, we: (1) systemically investigate interaction and dependency patterns between different categories of instructions, (2) manage to optimize the instruction set concerning the interaction patterns using a linear programming-based method, and optimize the learning schema of SFT using an instruction dependency taxonomy guided curriculum learning. Experimental results across different LLMs demonstrate improved performance over strong baselines on widely adopted benchmarks.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
SpikeLM: Towards General Spike-Driven Language Modeling via Elastic Bi-Spiking Mechanisms
Jun 05, 2024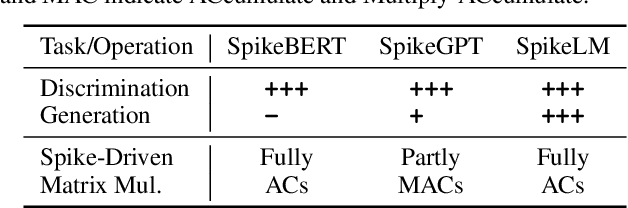
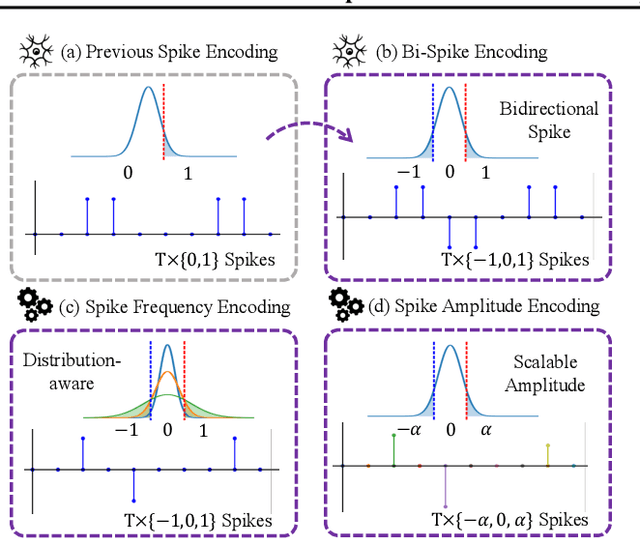
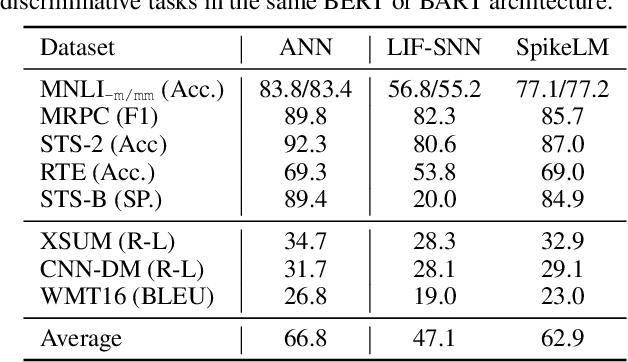
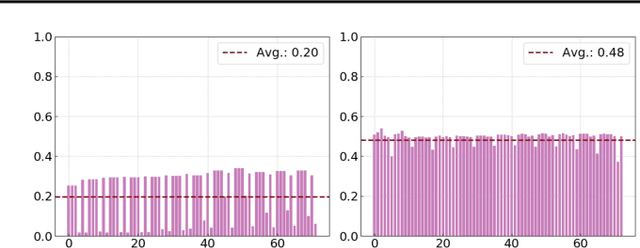
Towards energy-efficient artificial intelligence similar to the human brain, the bio-inspired spiking neural networks (SNNs) have advantages of biological plausibility, event-driven sparsity, and binary activation. Recently, large-scale language models exhibit promising generalization capability, making it a valuable issue to explore more general spike-driven models. However, the binary spikes in existing SNNs fail to encode adequate semantic information, placing technological challenges for generalization. This work proposes the first fully spiking mechanism for general language tasks, including both discriminative and generative ones. Different from previous spikes with {0,1} levels, we propose a more general spike formulation with bi-directional, elastic amplitude, and elastic frequency encoding, while still maintaining the addition nature of SNNs. In a single time step, the spike is enhanced by direction and amplitude information; in spike frequency, a strategy to control spike firing rate is well designed. We plug this elastic bi-spiking mechanism in language modeling, named SpikeLM. It is the first time to handle general language tasks with fully spike-driven models, which achieve much higher accuracy than previously possible. SpikeLM also greatly bridges the performance gap between SNNs and ANNs in language modeling. Our code is available at https://github.com/Xingrun-Xing/SpikeLM.
KLoB: a Benchmark for Assessing Knowledge Locating Methods in Language Models
Sep 28, 2023Recently, Locate-Then-Edit paradigm has emerged as one of the main approaches in changing factual knowledge stored in the Language models. However, there is a lack of research on whether present locating methods can pinpoint the exact parameters embedding the desired knowledge. Moreover, although many researchers have questioned the validity of locality hypothesis of factual knowledge, no method is provided to test the a hypothesis for more in-depth discussion and research. Therefore, we introduce KLoB, a benchmark examining three essential properties that a reliable knowledge locating method should satisfy. KLoB can serve as a benchmark for evaluating existing locating methods in language models, and can contributes a method to reassessing the validity of locality hypothesis of factual knowledge. Our is publicly available at \url{https://github.com/juyiming/KLoB}.