 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCI-VID: A Coherent Interleaved Text-Video Dataset
Jul 02, 2025Text-to-video (T2V) generation has recently attracted considerable attention, resulting in the development of numerous high-quality datasets that have propelled progress in this area. However, existing public datasets are primarily composed of isolated text-video (T-V) pairs and thus fail to support the modeling of coherent multi-clip video sequences. To address this limitation, we introduce CI-VID, a dataset that moves beyond isolated text-to-video (T2V) generation toward text-and-video-to-video (TV2V) generation, enabling models to produce coherent, multi-scene video sequences. CI-VID contains over 340,000 samples, each featuring a coherent sequence of video clips with text captions that capture both the individual content of each clip and the transitions between them, enabling visually and textually grounded generation. To further validate the effectiveness of CI-VID, we design a comprehensive, multi-dimensional benchmark incorporating human evaluation, VLM-based assessment, and similarity-based metrics. Experimental results demonstrate that models trained on CI-VID exhibit significant improvements in both accuracy and content consistency when generating video sequences. This facilitates the creation of story-driven content with smooth visual transitions and strong temporal coherence, underscoring the quality and practical utility of the CI-VID dataset We release the CI-VID dataset and the accompanying code for data construction and evaluation at: https://github.com/ymju-BAAI/CI-VID
Aqulia-Med LLM: Pioneering Full-Process Open-Source Medical Language Models
Jun 18, 2024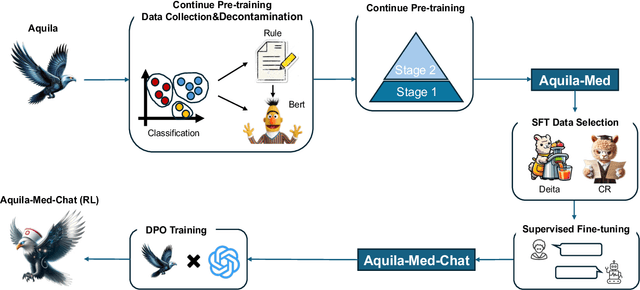

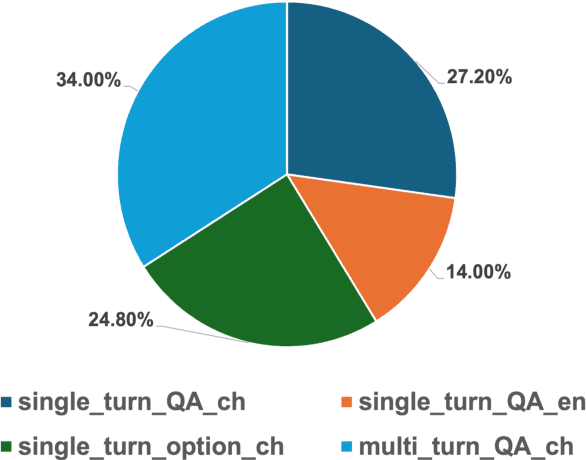
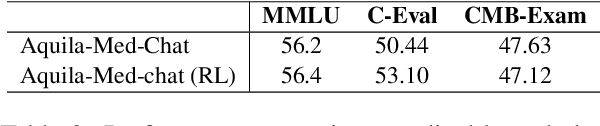
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional fields such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. We propose Aquila-Med, a bilingual medical LLM based on Aquila, addressing these challenges through continue pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). We construct a large-scale Chinese and English medical dataset for continue pre-training and a high-quality SFT dataset, covering extensive medical specialties. Additionally, we develop a high-quality Direct Preference Optimization (DPO) dataset for further alignment. Aquila-Med achieves notable results across single-turn, multi-turn dialogues, and medical multiple-choice questions, demonstrating the effectiveness of our approach. We open-source the datasets and the entire training process, contributing valuable resources to the research community. Our models and datasets will released at https://huggingface.co/BAAI/AquilaMed-RL.