 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAqulia-Med LLM: Pioneering Full-Process Open-Source Medical Language Models
Paper and Code
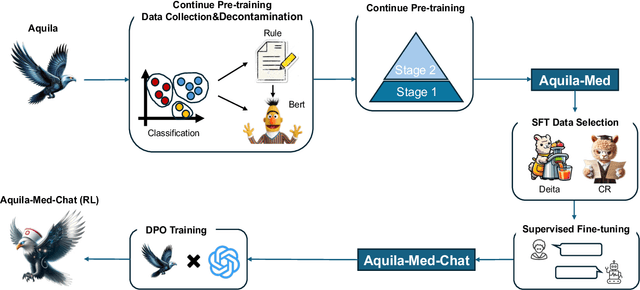

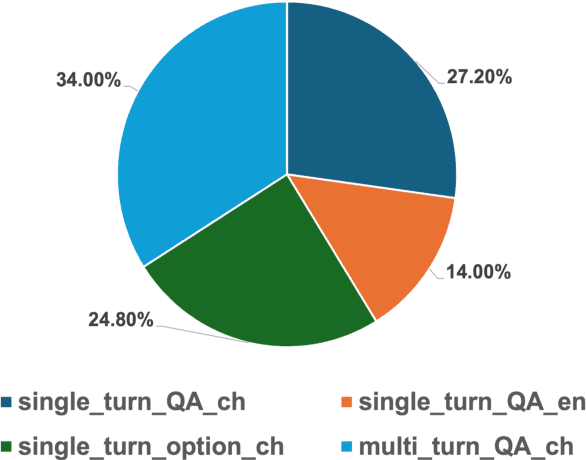
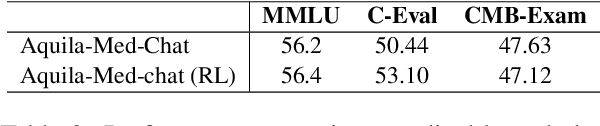
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional fields such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. We propose Aquila-Med, a bilingual medical LLM based on Aquila, addressing these challenges through continue pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). We construct a large-scale Chinese and English medical dataset for continue pre-training and a high-quality SFT dataset, covering extensive medical specialties. Additionally, we develop a high-quality Direct Preference Optimization (DPO) dataset for further alignment. Aquila-Med achieves notable results across single-turn, multi-turn dialogues, and medical multiple-choice questions, demonstrating the effectiveness of our approach. We open-source the datasets and the entire training process, contributing valuable resources to the research community. Our models and datasets will released at https://huggingface.co/BAAI/AquilaMed-RL.