 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetCCL: Enabling Collective Communication For Mixed-Vendor Heterogeneous Clusters
May 29, 2026Training Large Language Models (LLMs) on heterogeneous clusters presents significant challenges for collective communication, as hardware from multiple vendors introduces diverse network and computational characteristics. Existing collective communication frameworks (e.g., NCCL, RCCL) designed for homogeneous environments fail to address mixed-hardware setups, while communication libraries with heterogeneous support (e.g., Gloo, OpenMPI) incur heavy overhead in the data path. This paper presents HetCCL, a framework that enables heterogeneous collective communication by efficient P2P transport across heterogeneous devices (e.g., GPUs), eliminating the host-device memory copy overhead while offloading the control to the CPUs. For combining collectives (e.g., AllReduce, ReduceScatter), HetCCL introduces a border-communicator mechanism that achieves vendor independence by using the intrinsic reduction in the combining collectives in vendor collective communication libraries. With efficient heterogeneous P2P transport and portable reduction mechanism, HetCCL proposes a hierarchical topology abstraction for heterogeneous clusters, dissecting collective communication into cluster-level primitives that guarantee optimal cross-cluster data transfer volume and optimal bandwidth utilization. We implement HetCCL with 4 different vendor support and evaluate it in 4 heterogeneous settings with benchmarks and end-to-end LLM tasks. Our evaluation shows that HetCCL achieves 17-19x higher bandwidth than Gloo in heterogeneous communications, and speeds up end-to-end training by up to 16.9% in the per-step-time.
FreqCache: Accelerating Embodied VLN Models with Adaptive Frequency-Guided Token Caching
Apr 27, 2026Vision-Language-Navigation (VLN) models exhibit excellent navigation accuracy but incur high computational overhead. Token caching has emerged as a promising training-free strategy to reduce this cost by reusing token computation results; however, existing token caching approaches rely on visual domain methods for cacheable token selection, leading to challenges when adapted to VLN models. 1) Visual domain methods become invalid when there is viewpoint migration. 2) Visual domain methods neglect critical edge information without the aid of additional algorithms. 3) Visual domain methods overlook the temporal variation of scenarios and lack adjustability in cache budgets. In this paper, we develop detailed analyses and find that the impacts of these challenges exhibit invariance and analyzability in the frequency domain. Based on these, we propose a frequency-guided token caching framework, called FreqCache. Utilizing the inherent properties of the frequency domain, FreqCache achieves optimal token cache establishment, refreshment, and adaptive adjustment. Experiments show that FreqCache achieves 1.59x speedup with ignorable overhead, showing the effect of integrating frequency domain methods in VLN token caching.
Towards Automated Kernel Generation in the Era of LLMs
Jan 26, 2026The performance of modern AI systems is fundamentally constrained by the quality of their underlying kernels, which translate high-level algorithmic semantics into low-level hardware operations. Achieving near-optimal kernels requires expert-level understanding of hardware architectures and programming models, making kernel engineering a critical but notoriously time-consuming and non-scalable process. Recent advances in large language models (LLMs) and LLM-based agents have opened new possibilities for automating kernel generation and optimization. LLMs are well-suited to compress expert-level kernel knowledge that is difficult to formalize, while agentic systems further enable scalable optimization by casting kernel development as an iterative, feedback-driven loop. Rapid progress has been made in this area. However, the field remains fragmented, lacking a systematic perspective for LLM-driven kernel generation. This survey addresses this gap by providing a structured overview of existing approaches, spanning LLM-based approaches and agentic optimization workflows, and systematically compiling the datasets and benchmarks that underpin learning and evaluation in this domain. Moreover, key open challenges and future research directions are further outlined, aiming to establish a comprehensive reference for the next generation of automated kernel optimization. To keep track of this field, we maintain an open-source GitHub repository at https://github.com/flagos-ai/awesome-LLM-driven-kernel-generation.
RoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
TrimTokenator-LC: Towards Adaptive Visual Token Pruning for Large Multimodal Models with Long Contexts
Dec 31, 2025Large Multimodal Models (LMMs) have proven effective on various tasks. They typically encode visual inputs into Original Model sequences of tokens, which are then concatenated with textual tokens and jointly processed by the language model. However, the growing number of visual tokens greatly increases inference cost. Visual token pruning has emerged as a promising solution. However, existing methods often overlook scenarios involving long context inputs with multiple images. In this paper, we analyze the challenges of visual token pruning in long context, multi-image settings and introduce an adaptive pruning method tailored for such scenarios. We decompose redundancy into intra-image and inter-image components and quantify them through intra-image diversity and inter-image variation, which jointly guide dynamic budget allocation. Our approach consists of two stages. The intra-image stage allocates each image a content-aware token budget and greedily selects its most representative tokens. The inter-image stage performs global diversity filtering to form a candidate pool and then applies a Pareto selection procedure that balances diversity with text alignment. Extensive experiments show that our approach can reduce up to 80% of visual tokens while maintaining performance in long context settings.
RoboOS-NeXT: A Unified Memory-based Framework for Lifelong, Scalable, and Robust Multi-Robot Collaboration
Oct 30, 2025The proliferation of collaborative robots across diverse tasks and embodiments presents a central challenge: achieving lifelong adaptability, scalable coordination, and robust scheduling in multi-agent systems. Existing approaches, from vision-language-action (VLA) models to hierarchical frameworks, fall short due to their reliance on limited or dividual-agent memory. This fundamentally constrains their ability to learn over long horizons, scale to heterogeneous teams, or recover from failures, highlighting the need for a unified memory representation. To address these limitations, we introduce RoboOS-NeXT, a unified memory-based framework for lifelong, scalable, and robust multi-robot collaboration. At the core of RoboOS-NeXT is the novel Spatio-Temporal-Embodiment Memory (STEM), which integrates spatial scene geometry, temporal event history, and embodiment profiles into a shared representation. This memory-centric design is integrated into a brain-cerebellum framework, where a high-level brain model performs global planning by retrieving and updating STEM, while low-level controllers execute actions locally. This closed loop between cognition, memory, and execution enables dynamic task allocation, fault-tolerant collaboration, and consistent state synchronization. We conduct extensive experiments spanning complex coordination tasks in restaurants, supermarkets, and households. Our results demonstrate that RoboOS-NeXT achieves superior performance across heterogeneous embodiments, validating its effectiveness in enabling lifelong, scalable, and robust multi-robot collaboration. Project website: https://flagopen.github.io/RoboOS/
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
CCI4.0: A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models
Jun 09, 2025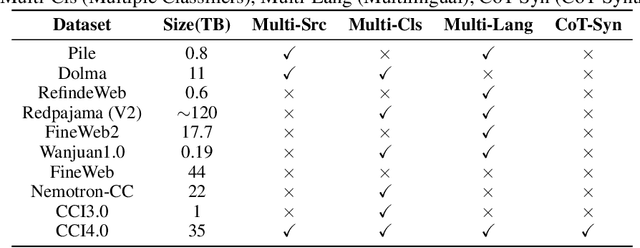
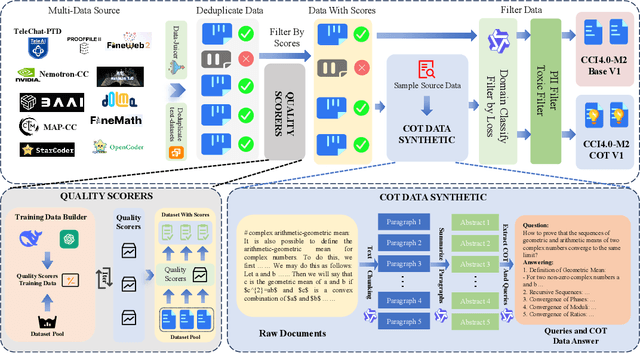
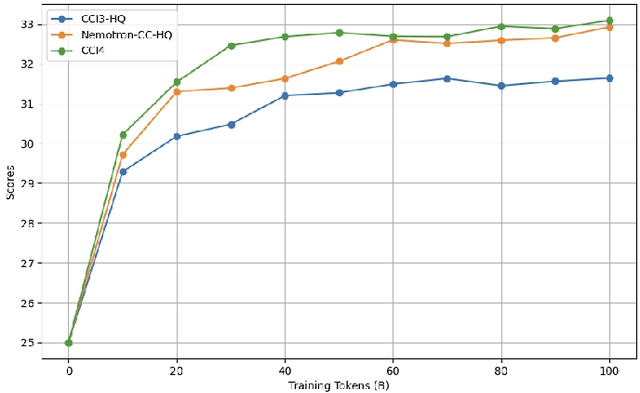
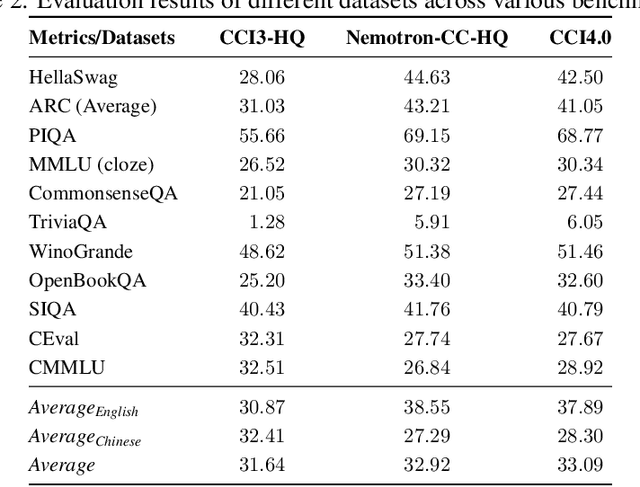
We introduce CCI4.0, a large-scale bilingual pre-training dataset engineered for superior data quality and diverse human-like reasoning trajectory. CCI4.0 occupies roughly $35$ TB of disk space and comprises two sub-datasets: CCI4.0-M2-Base and CCI4.0-M2-CoT. CCI4.0-M2-Base combines a $5.2$ TB carefully curated Chinese web corpus, a $22.5$ TB English subset from Nemotron-CC, and diverse sources from math, wiki, arxiv, and code. Although these data are mostly sourced from well-processed datasets, the quality standards of various domains are dynamic and require extensive expert experience and labor to process. So, we propose a novel pipeline justifying data quality mainly based on models through two-stage deduplication, multiclassifier quality scoring, and domain-aware fluency filtering. We extract $4.5$ billion pieces of CoT(Chain-of-Thought) templates, named CCI4.0-M2-CoT. Differing from the distillation of CoT from larger models, our proposed staged CoT extraction exemplifies diverse reasoning patterns and significantly decreases the possibility of hallucination. Empirical evaluations demonstrate that LLMs pre-trained in CCI4.0 benefit from cleaner, more reliable training signals, yielding consistent improvements in downstream tasks, especially in math and code reflection tasks. Our results underscore the critical role of rigorous data curation and human thinking templates in advancing LLM performance, shedding some light on automatically processing pretraining corpora.
SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged Seniors
Mar 20, 2025While voice technologies increasingly serve aging populations, current systems exhibit significant performance gaps due to inadequate training data capturing elderly-specific vocal characteristics like presbyphonia and dialectal variations. The limited data available on super-aged individuals in existing elderly speech datasets, coupled with overly simple recording styles and annotation dimensions, exacerbates this issue. To address the critical scarcity of speech data from individuals aged 75 and above, we introduce SeniorTalk, a carefully annotated Chinese spoken dialogue dataset. This dataset contains 55.53 hours of speech from 101 natural conversations involving 202 participants, ensuring a strategic balance across gender, region, and age. Through detailed annotation across multiple dimensions, it can support a wide range of speech tasks. We perform extensive experiments on speaker verification, speaker diarization, speech recognition, and speech editing tasks, offering crucial insights for the development of speech technologies targeting this age group.
CS-Dialogue: A 104-Hour Dataset of Spontaneous Mandarin-English Code-Switching Dialogues for Speech Recognition
Feb 26, 2025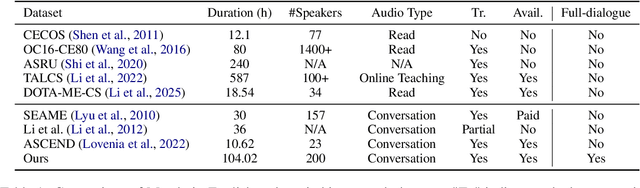



Code-switching (CS), the alternation between two or more languages within a single conversation, presents significant challenges for automatic speech recognition (ASR) systems. Existing Mandarin-English code-switching datasets often suffer from limitations in size, spontaneity, and the lack of full-length dialogue recordings with transcriptions, hindering the development of robust ASR models for real-world conversational scenarios. This paper introduces CS-Dialogue, a novel large-scale Mandarin-English code-switching speech dataset comprising 104 hours of spontaneous conversations from 200 speakers. Unlike previous datasets, CS-Dialogue provides full-length dialogue recordings with complete transcriptions, capturing naturalistic code-switching patterns in continuous speech. We describe the data collection and annotation processes, present detailed statistics of the dataset, and establish benchmark ASR performance using state-of-the-art models. Our experiments, using Transformer, Conformer, and Branchformer, demonstrate the challenges of code-switching ASR, and show that existing pre-trained models such as Whisper still have the space to improve. The CS-Dialogue dataset will be made freely available for all academic purposes.