 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cluster Resilience: LLM-agent Based Autonomous Intelligent Cluster Diagnosis System and Evaluation Framework
Nov 08, 2024Recent advancements in Large Language Models (LLMs) and related technologies such as Retrieval-Augmented Generation (RAG) and Diagram of Thought (DoT) have enabled the creation of autonomous intelligent systems capable of performing cluster diagnostics and troubleshooting. By integrating these technologies with self-play methodologies, we have developed an LLM-agent system designed to autonomously diagnose and resolve issues within AI clusters. Our innovations include a knowledge base tailored for cluster diagnostics, enhanced LLM algorithms, practical deployment strategies for agents, and a benchmark specifically designed for evaluating LLM capabilities in this domain. Through extensive experimentation across multiple dimensions, we have demonstrated the superiority of our system in addressing the challenges faced in cluster diagnostics, particularly in detecting and rectifying performance issues more efficiently and accurately than traditional methods.
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024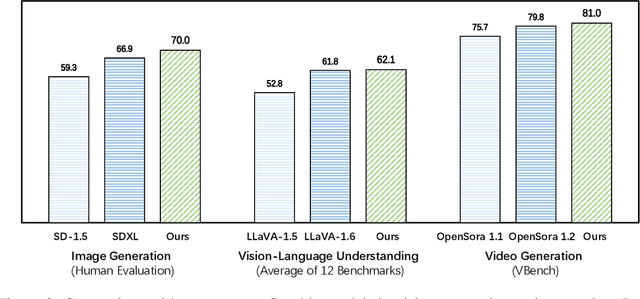


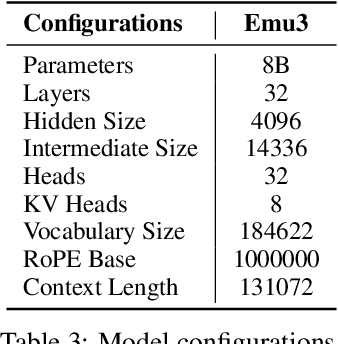
While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.