 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
GraphWalker: Agentic Knowledge Graph Question Answering via Synthetic Trajectory Curriculum
Mar 30, 2026Agentic knowledge graph question answering (KGQA) requires an agent to iteratively interact with knowledge graphs (KGs), posing challenges in both training data scarcity and reasoning generalization. Specifically, existing approaches often restrict agent exploration: prompting-based methods lack autonomous navigation training, while current training pipelines usually confine reasoning to predefined trajectories. To this end, this paper proposes \textit{GraphWalker}, a novel agentic KGQA framework that addresses these challenges through \textit{Automated Trajectory Synthesis} and \textit{Stage-wise Fine-tuning}. GraphWalker adopts a two-stage SFT training paradigm: First, the agent is trained on structurally diverse trajectories synthesized from constrained random-walk paths, establishing a broad exploration prior over the KG; Second, the agent is further fine-tuned on a small set of expert trajectories to develop reflection and error recovery capabilities. Extensive experiments demonstrate that our stage-wise SFT paradigm unlocks a higher performance ceiling for a lightweight reinforcement learning (RL) stage, enabling GraphWalker to achieve state-of-the-art performance on CWQ and WebQSP. Additional results on GrailQA and our constructed GraphWalkerBench confirm that GraphWalker enhances generalization to out-of-distribution reasoning paths. The code is publicly available at https://github.com/XuShuwenn/GraphWalker
MMOU: A Massive Multi-Task Omni Understanding and Reasoning Benchmark for Long and Complex Real-World Videos
Mar 14, 2026Multimodal Large Language Models (MLLMs) have shown strong performance in visual and audio understanding when evaluated in isolation. However, their ability to jointly reason over omni-modal (visual, audio, and textual) signals in long and complex videos remains largely unexplored. We introduce MMOU, a new benchmark designed to systematically evaluate multimodal understanding and reasoning under these challenging, real-world conditions. MMOU consists of 15,000 carefully curated questions paired with 9038 web-collected videos of varying length, spanning diverse domains and exhibiting rich, tightly coupled audio-visual content. The benchmark covers 13 fundamental skill categories, all of which require integrating evidence across modalities and time. All questions are manually annotated across multiple turns by professional annotators, ensuring high quality and reasoning fidelity. We evaluate 20+ state-of-the-art open-source and proprietary multimodal models on MMOU. The results expose substantial performance gaps: the best closed-source model achieves only 64.2% accuracy, while the strongest open-source model reaches just 46.8%. Our results highlight the challenges of long-form omni-modal understanding, revealing that current models frequently fail to apply even fundamental skills in long videos. Through detailed analysis, we further identify systematic failure modes and provide insights into where and why current models break.
Uni-Animator: Towards Unified Visual Colorization
Feb 26, 2026We propose Uni-Animator, a novel Diffusion Transformer (DiT)-based framework for unified image and video sketch colorization. Existing sketch colorization methods struggle to unify image and video tasks, suffering from imprecise color transfer with single or multiple references, inadequate preservation of high-frequency physical details, and compromised temporal coherence with motion artifacts in large-motion scenes. To tackle imprecise color transfer, we introduce visual reference enhancement via instance patch embedding, enabling precise alignment and fusion of reference color information. To resolve insufficient physical detail preservation, we design physical detail reinforcement using physical features that effectively capture and retain high-frequency textures. To mitigate motion-induced temporal inconsistency, we propose sketch-based dynamic RoPE encoding that adaptively models motion-aware spatial-temporal dependencies. Extensive experimental results demonstrate that Uni-Animator achieves competitive performance on both image and video sketch colorization, matching that of task-specific methods while unlocking unified cross-domain capabilities with high detail fidelity and robust temporal consistency.
TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents
Jan 06, 2026Long-horizon conversational agents have to manage ever-growing interaction histories that quickly exceed the finite context windows of large language models (LLMs). Existing memory frameworks provide limited support for temporally structured information across hierarchical levels, often leading to fragmented memories and unstable long-horizon personalization. We present TiMem, a temporal--hierarchical memory framework that organizes conversations through a Temporal Memory Tree (TMT), enabling systematic memory consolidation from raw conversational observations to progressively abstracted persona representations. TiMem is characterized by three core properties: (1) temporal--hierarchical organization through TMT; (2) semantic-guided consolidation that enables memory integration across hierarchical levels without fine-tuning; and (3) complexity-aware memory recall that balances precision and efficiency across queries of varying complexity. Under a consistent evaluation setup, TiMem achieves state-of-the-art accuracy on both benchmarks, reaching 75.30% on LoCoMo and 76.88% on LongMemEval-S. It outperforms all evaluated baselines while reducing the recalled memory length by 52.20% on LoCoMo. Manifold analysis indicates clear persona separation on LoCoMo and reduced dispersion on LongMemEval-S. Overall, TiMem treats temporal continuity as a first-class organizing principle for long-horizon memory in conversational agents.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Towards Agentic Self-Learning LLMs in Search Environment
Oct 16, 2025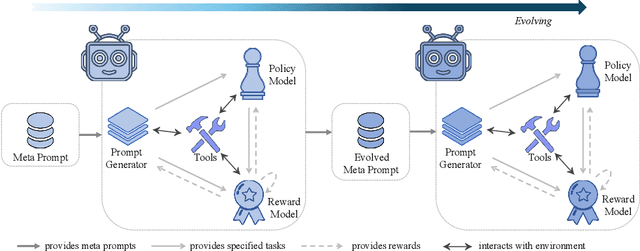
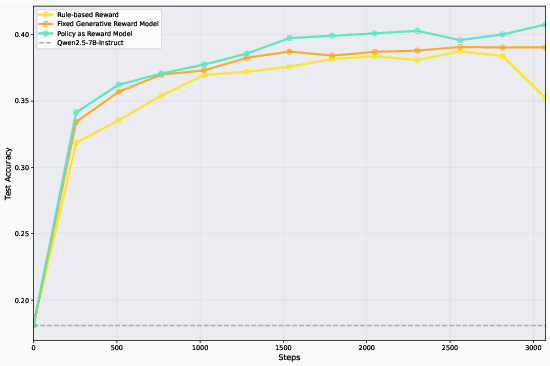
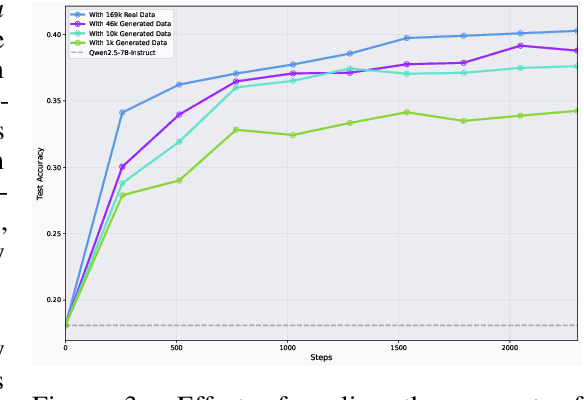
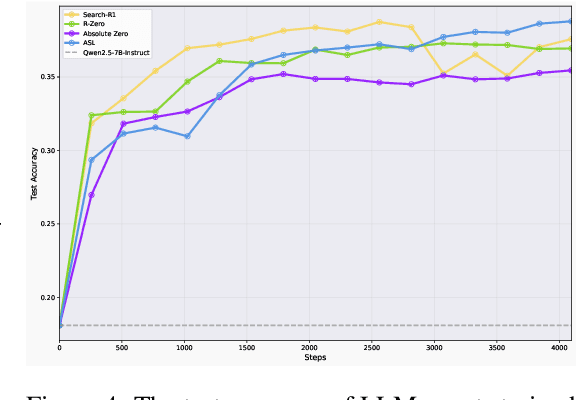
We study whether self-learning can scale LLM-based agents without relying on human-curated datasets or predefined rule-based rewards. Through controlled experiments in a search-agent setting, we identify two key determinants of scalable agent training: the source of reward signals and the scale of agent task data. We find that rewards from a Generative Reward Model (GRM) outperform rigid rule-based signals for open-domain learning, and that co-evolving the GRM with the policy further boosts performance. Increasing the volume of agent task data-even when synthetically generated-substantially enhances agentic capabilities. Building on these insights, we propose \textbf{Agentic Self-Learning} (ASL), a fully closed-loop, multi-role reinforcement learning framework that unifies task generation, policy execution, and evaluation within a shared tool environment and LLM backbone. ASL coordinates a Prompt Generator, a Policy Model, and a Generative Reward Model to form a virtuous cycle of harder task setting, sharper verification, and stronger solving. Empirically, ASL delivers steady, round-over-round gains, surpasses strong RLVR baselines (e.g., Search-R1) that plateau or degrade, and continues improving under zero-labeled-data conditions, indicating superior sample efficiency and robustness. We further show that GRM verification capacity is the main bottleneck: if frozen, it induces reward hacking and stalls progress; continual GRM training on the evolving data distribution mitigates this, and a small late-stage injection of real verification data raises the performance ceiling. This work establishes reward source and data scale as critical levers for open-domain agent learning and demonstrates the efficacy of multi-role co-evolution for scalable, self-improving agents. The data and code of this paper are released at https://github.com/forangel2014/Towards-Agentic-Self-Learning
Learning to Decide with Just Enough: Information-Theoretic Context Summarization for CDMPs
Oct 02, 2025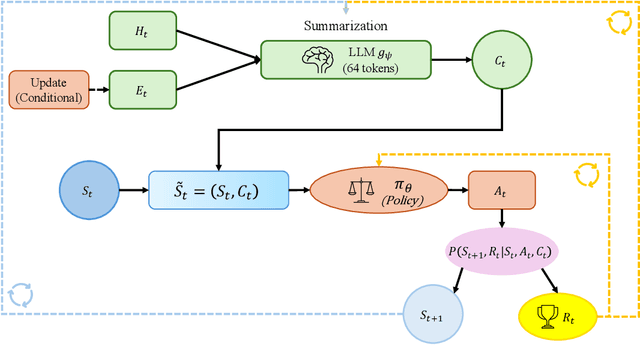

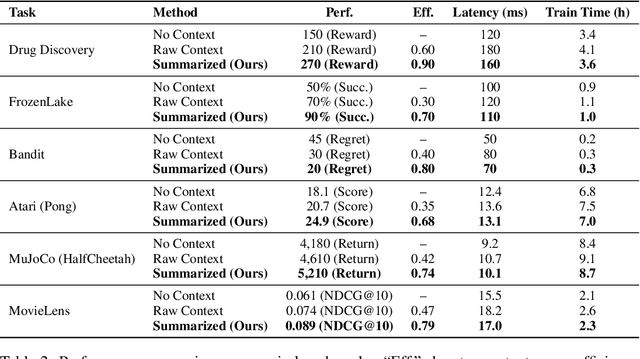
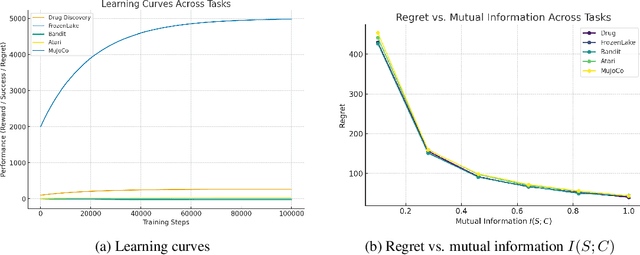
Contextual Markov Decision Processes (CMDPs) offer a framework for sequential decision-making under external signals, but existing methods often fail to generalize in high-dimensional or unstructured contexts, resulting in excessive computation and unstable performance. We propose an information-theoretic summarization approach that uses large language models (LLMs) to compress contextual inputs into low-dimensional, semantically rich summaries. These summaries augment states by preserving decision-critical cues while reducing redundancy. Building on the notion of approximate context sufficiency, we provide, to our knowledge, the first regret bounds and a latency-entropy trade-off characterization for CMDPs. Our analysis clarifies how informativeness impacts computational cost. Experiments across discrete, continuous, visual, and recommendation benchmarks show that our method outperforms raw-context and non-context baselines, improving reward, success rate, and sample efficiency, while reducing latency and memory usage. These findings demonstrate that LLM-based summarization offers a scalable and interpretable solution for efficient decision-making in context-rich, resource-constrained environments.
Self-Improvement for Audio Large Language Model using Unlabeled Speech
Jul 27, 2025Recent audio LLMs have emerged rapidly, demonstrating strong generalization across various speech tasks. However, given the inherent complexity of speech signals, these models inevitably suffer from performance degradation in specific target domains. To address this, we focus on enhancing audio LLMs in target domains without any labeled data. We propose a self-improvement method called SI-SDA, leveraging the information embedded in large-model decoding to evaluate the quality of generated pseudo labels and then perform domain adaptation based on reinforcement learning optimization. Experimental results show that our method consistently and significantly improves audio LLM performance, outperforming existing baselines in WER and BLEU across multiple public datasets of automatic speech recognition (ASR), spoken question-answering (SQA), and speech-to-text translation (S2TT). Furthermore, our approach exhibits high data efficiency, underscoring its potential for real-world deployment.