 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Layerwise Perturbation: Unifying Off-Policy Corrections for LLM RL
Mar 19, 2026Off-policy problems such as policy staleness and training-inference mismatch, has become a major bottleneck for training stability and further exploration for LLM RL. To enhance inference efficiency, the distribution gap between the inference and updated policy grows, leading to heavy-tailed importance ratios. Heavy-tailed ratios arise when the policy is locally sharp, which further inflates sharp gradients and can push updates outside the trust region. To address this, we propose Adaptive Layerwise Perturbation(ALP) by injecting small learnable perturbations into input hidden states of each layer during updates, which is used as the numerator of the importance ratio against the unchanged inference policy in the objective. Intuitively, by adding controlled noise to intermediate representations, ALP prevents the updated policy from deviating too sharply from the inference policy, and enlarges the policy family to cover the inference policy family with mismatch noises. Hence, the flattened distribution can naturally tighten the updated and inference policy gap and reduce the tail of importance ratios, thus maintaining training stability. This is further validated empirically. Experiments on single-turn math and multi-turn tool-integrated reasoning tasks show that ALP not only improves final performance, but also avoid blow up of importance ratio tail and KL spikes during iterative training, along with boosted exploration. Ablations show that representation-level perturbations across all layers are most effective, substantially outperforming partial-layer and logits-only variants.
Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
Sep 03, 2025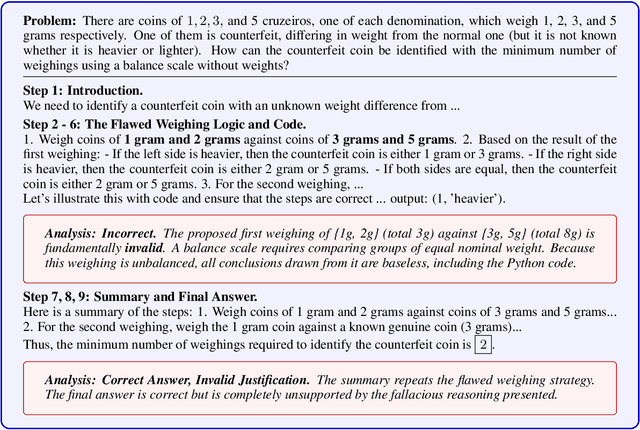
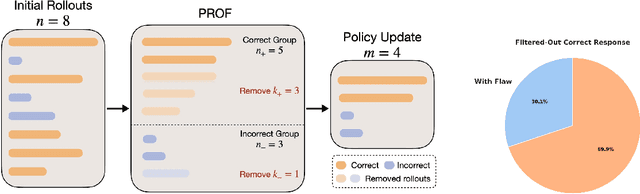
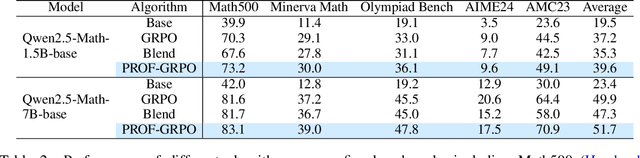
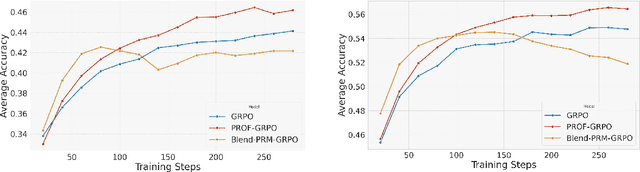
Reinforcement learning with verifiable rewards (RLVR) has emerged to be a predominant paradigm for mathematical reasoning tasks, offering stable improvements in reasoning ability. However, Outcome Reward Models (ORMs) in RLVR are too coarse-grained to distinguish flawed reasoning within correct answers or valid reasoning within incorrect answers. This lack of granularity introduces noisy and misleading gradients significantly and hinders further progress in reasoning process quality. While Process Reward Models (PRMs) offer fine-grained guidance for intermediate steps, they frequently suffer from inaccuracies and are susceptible to reward hacking. To resolve this dilemma, we introduce PRocess cOnsistency Filter (PROF), an effective data process curation method that harmonizes noisy, fine-grained process rewards with accurate, coarse-grained outcome rewards. Rather than naively blending PRM and ORM in the objective function (arXiv:archive/2506.18896), PROF leverages their complementary strengths through consistency-driven sample selection. Our approach retains correct responses with higher averaged process values and incorrect responses with lower averaged process values, while maintaining positive/negative training sample balance. Extensive experiments demonstrate that our method not only consistently improves the final accuracy over $4\%$ compared to the blending approaches, but also strengthens the quality of intermediate reasoning steps. Codes and training recipes are available at https://github.com/Chenluye99/PROF.
GR-LLMs: Recent Advances in Generative Recommendation Based on Large Language Models
Jul 09, 2025


In the past year, Generative Recommendations (GRs) have undergone substantial advancements, especially in leveraging the powerful sequence modeling and reasoning capabilities of Large Language Models (LLMs) to enhance overall recommendation performance. LLM-based GRs are forming a new paradigm that is distinctly different from discriminative recommendations, showing strong potential to replace traditional recommendation systems heavily dependent on complex hand-crafted features. In this paper, we provide a comprehensive survey aimed at facilitating further research of LLM-based GRs. Initially, we outline the general preliminaries and application cases of LLM-based GRs. Subsequently, we introduce the main considerations when LLM-based GRs are applied in real industrial scenarios. Finally, we explore promising directions for LLM-based GRs. We hope that this survey contributes to the ongoing advancement of the GR domain.
HGCL: Hierarchical Graph Contrastive Learning for User-Item Recommendation
May 25, 2025


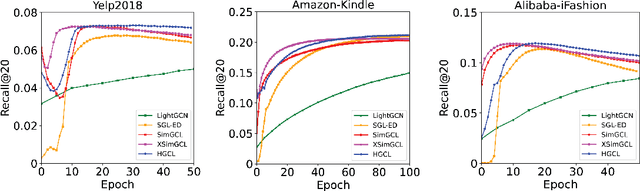
Graph Contrastive Learning (GCL), which fuses graph neural networks with contrastive learning, has evolved as a pivotal tool in user-item recommendations. While promising, existing GCL methods often lack explicit modeling of hierarchical item structures, which represent item similarities across varying resolutions. Such hierarchical item structures are ubiquitous in various items (e.g., online products and local businesses), and reflect their inherent organizational properties that serve as critical signals for enhancing recommendation accuracy. In this paper, we propose Hierarchical Graph Contrastive Learning (HGCL), a novel GCL method that incorporates hierarchical item structures for user-item recommendations. First, HGCL pre-trains a GCL module using cross-layer contrastive learning to obtain user and item representations. Second, HGCL employs a representation compression and clustering method to construct a two-hierarchy user-item bipartite graph. Ultimately, HGCL fine-tunes user and item representations by learning on the hierarchical graph, and then provides recommendations based on user-item interaction scores. Experiments on three widely adopted benchmark datasets ranging from 70K to 382K nodes confirm the superior performance of HGCL over existing baseline models, highlighting the contribution of hierarchical item structures in enhancing GCL methods for recommendation tasks.
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
May 16, 2025Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.
Semantic Volume: Quantifying and Detecting both External and Internal Uncertainty in LLMs
Feb 28, 2025Large language models (LLMs) have demonstrated remarkable performance across diverse tasks by encoding vast amounts of factual knowledge. However, they are still prone to hallucinations, generating incorrect or misleading information, often accompanied by high uncertainty. Existing methods for hallucination detection primarily focus on quantifying internal uncertainty, which arises from missing or conflicting knowledge within the model. However, hallucinations can also stem from external uncertainty, where ambiguous user queries lead to multiple possible interpretations. In this work, we introduce Semantic Volume, a novel mathematical measure for quantifying both external and internal uncertainty in LLMs. Our approach perturbs queries and responses, embeds them in a semantic space, and computes the determinant of the Gram matrix of the embedding vectors, capturing their dispersion as a measure of uncertainty. Our framework provides a generalizable and unsupervised uncertainty detection method without requiring white-box access to LLMs. We conduct extensive experiments on both external and internal uncertainty detection, demonstrating that our Semantic Volume method consistently outperforms existing baselines in both tasks. Additionally, we provide theoretical insights linking our measure to differential entropy, unifying and extending previous sampling-based uncertainty measures such as the semantic entropy. Semantic Volume is shown to be a robust and interpretable approach to improving the reliability of LLMs by systematically detecting uncertainty in both user queries and model responses.
DARD: A Multi-Agent Approach for Task-Oriented Dialog Systems
Nov 01, 2024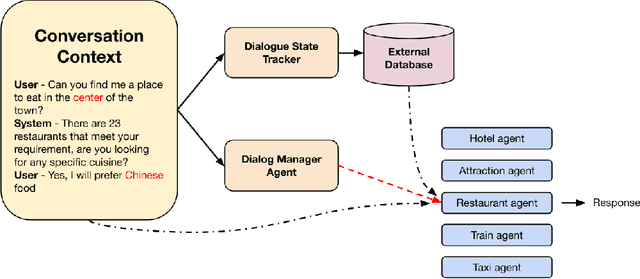
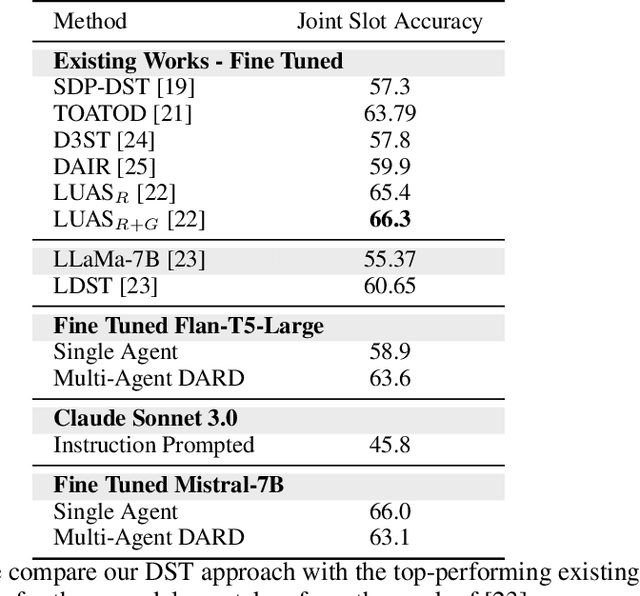
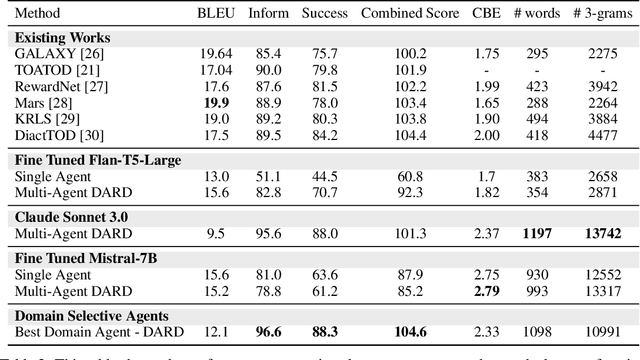

Task-oriented dialogue systems are essential for applications ranging from customer service to personal assistants and are widely used across various industries. However, developing effective multi-domain systems remains a significant challenge due to the complexity of handling diverse user intents, entity types, and domain-specific knowledge across several domains. In this work, we propose DARD (Domain Assigned Response Delegation), a multi-agent conversational system capable of successfully handling multi-domain dialogs. DARD leverages domain-specific agents, orchestrated by a central dialog manager agent. Our extensive experiments compare and utilize various agent modeling approaches, combining the strengths of smaller fine-tuned models (Flan-T5-large & Mistral-7B) with their larger counterparts, Large Language Models (LLMs) (Claude Sonnet 3.0). We provide insights into the strengths and limitations of each approach, highlighting the benefits of our multi-agent framework in terms of flexibility and composability. We evaluate DARD using the well-established MultiWOZ benchmark, achieving state-of-the-art performance by improving the dialogue inform rate by 6.6% and the success rate by 4.1% over the best-performing existing approaches. Additionally, we discuss various annotator discrepancies and issues within the MultiWOZ dataset and its evaluation system.
A Robust Ensemble Algorithm for Ischemic Stroke Lesion Segmentation: Generalizability and Clinical Utility Beyond the ISLES Challenge
Apr 03, 2024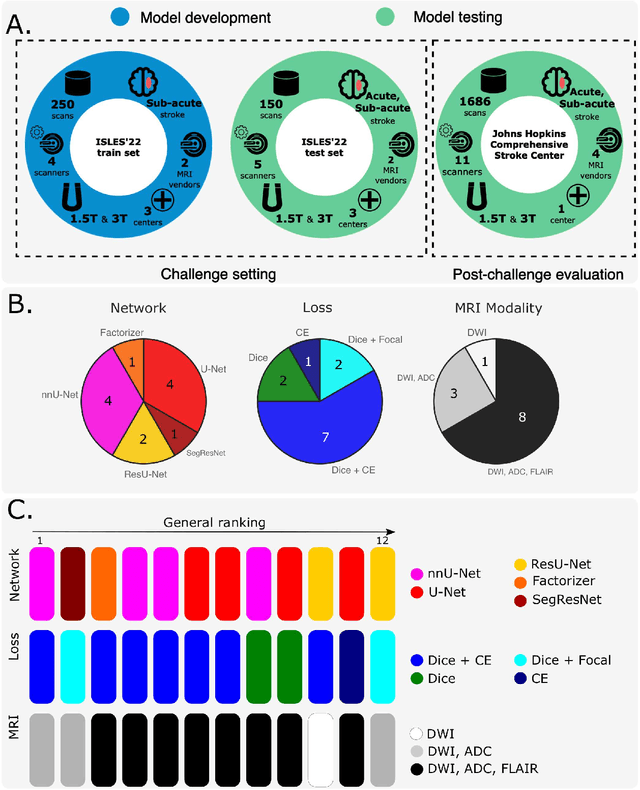
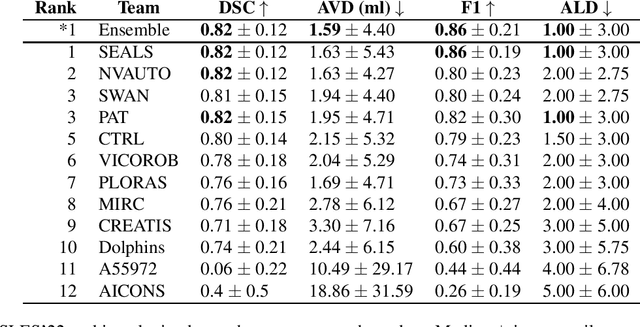
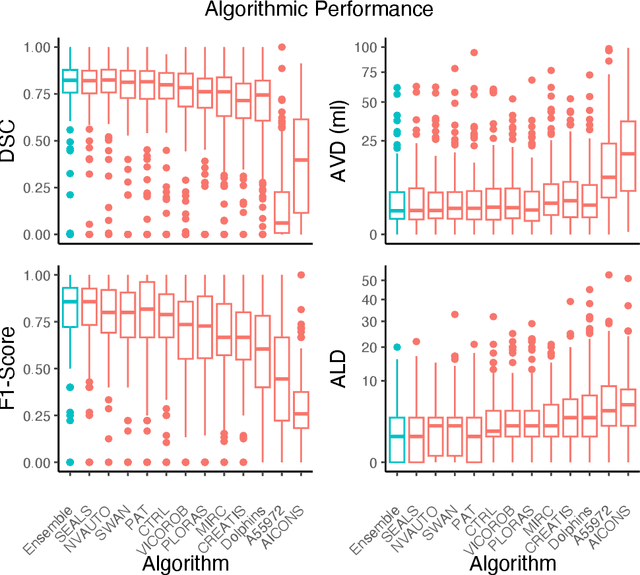
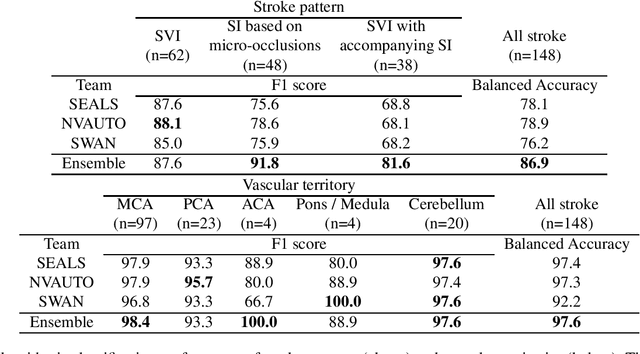
Diffusion-weighted MRI (DWI) is essential for stroke diagnosis, treatment decisions, and prognosis. However, image and disease variability hinder the development of generalizable AI algorithms with clinical value. We address this gap by presenting a novel ensemble algorithm derived from the 2022 Ischemic Stroke Lesion Segmentation (ISLES) challenge. ISLES'22 provided 400 patient scans with ischemic stroke from various medical centers, facilitating the development of a wide range of cutting-edge segmentation algorithms by the research community. Through collaboration with leading teams, we combined top-performing algorithms into an ensemble model that overcomes the limitations of individual solutions. Our ensemble model achieved superior ischemic lesion detection and segmentation accuracy on our internal test set compared to individual algorithms. This accuracy generalized well across diverse image and disease variables. Furthermore, the model excelled in extracting clinical biomarkers. Notably, in a Turing-like test, neuroradiologists consistently preferred the algorithm's segmentations over manual expert efforts, highlighting increased comprehensiveness and precision. Validation using a real-world external dataset (N=1686) confirmed the model's generalizability. The algorithm's outputs also demonstrated strong correlations with clinical scores (admission NIHSS and 90-day mRS) on par with or exceeding expert-derived results, underlining its clinical relevance. This study offers two key findings. First, we present an ensemble algorithm (https://github.com/Tabrisrei/ISLES22_Ensemble) that detects and segments ischemic stroke lesions on DWI across diverse scenarios on par with expert (neuro)radiologists. Second, we show the potential for biomedical challenge outputs to extend beyond the challenge's initial objectives, demonstrating their real-world clinical applicability.
Correlation-Aware Mutual Learning for Semi-supervised Medical Image Segmentation
Jul 12, 2023


Semi-supervised learning has become increasingly popular in medical image segmentation due to its ability to leverage large amounts of unlabeled data to extract additional information. However, most existing semi-supervised segmentation methods only focus on extracting information from unlabeled data, disregarding the potential of labeled data to further improve the performance of the model. In this paper, we propose a novel Correlation Aware Mutual Learning (CAML) framework that leverages labeled data to guide the extraction of information from unlabeled data. Our approach is based on a mutual learning strategy that incorporates two modules: the Cross-sample Mutual Attention Module (CMA) and the Omni-Correlation Consistency Module (OCC). The CMA module establishes dense cross-sample correlations among a group of samples, enabling the transfer of label prior knowledge to unlabeled data. The OCC module constructs omni-correlations between the unlabeled and labeled datasets and regularizes dual models by constraining the omni-correlation matrix of each sub-model to be consistent. Experiments on the Atrial Segmentation Challenge dataset demonstrate that our proposed approach outperforms state-of-the-art methods, highlighting the effectiveness of our framework in medical image segmentation tasks. The codes, pre-trained weights, and data are publicly available.
PATCorrect: Non-autoregressive Phoneme-augmented Transformer for ASR Error Correction
Feb 10, 2023Speech-to-text errors made by automatic speech recognition (ASR) system negatively impact downstream models relying on ASR transcriptions. Language error correction models as a post-processing text editing approach have been recently developed for refining the source sentences. However, efficient models for correcting errors in ASR transcriptions that meet the low latency requirements of industrial grade production systems have not been well studied. In this work, we propose a novel non-autoregressive (NAR) error correction approach to improve the transcription quality by reducing word error rate (WER) and achieve robust performance across different upstream ASR systems. Our approach augments the text encoding of the Transformer model with a phoneme encoder that embeds pronunciation information. The representations from phoneme encoder and text encoder are combined via multi-modal fusion before feeding into the length tagging predictor for predicting target sequence lengths. The joint encoders also provide inputs to the attention mechanism in the NAR decoder. We experiment on 3 open-source ASR systems with varying speech-to-text transcription quality and their erroneous transcriptions on 2 public English corpus datasets. Results show that our PATCorrect (Phoneme Augmented Transformer for ASR error Correction) consistently outperforms state-of-the-art NAR error correction method on English corpus across different upstream ASR systems. For example, PATCorrect achieves 11.62% WER reduction (WERR) averaged on 3 ASR systems compared to 9.46% WERR achieved by other method using text only modality and also achieves an inference latency comparable to other NAR models at tens of millisecond scale, especially on GPU hardware, while still being 4.2 - 6.7x times faster than autoregressive models on Common Voice and LibriSpeech datasets.