 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Energy-Efficient Deployment of Large Language Models on Memristor Crossbar: A Synergy of Large and Small
Oct 21, 2024Large language models (LLMs) have garnered substantial attention due to their promising applications in diverse domains. Nevertheless, the increasing size of LLMs comes with a significant surge in the computational requirements for training and deployment. Memristor crossbars have emerged as a promising solution, which demonstrated a small footprint and remarkably high energy efficiency in computer vision (CV) models. Memristors possess higher density compared to conventional memory technologies, making them highly suitable for effectively managing the extreme model size associated with LLMs. However, deploying LLMs on memristor crossbars faces three major challenges. Firstly, the size of LLMs increases rapidly, already surpassing the capabilities of state-of-the-art memristor chips. Secondly, LLMs often incorporate multi-head attention blocks, which involve non-weight stationary multiplications that traditional memristor crossbars cannot support. Third, while memristor crossbars excel at performing linear operations, they are not capable of executing complex nonlinear operations in LLM such as softmax and layer normalization. To address these challenges, we present a novel architecture for the memristor crossbar that enables the deployment of state-of-the-art LLM on a single chip or package, eliminating the energy and time inefficiencies associated with off-chip communication. Our testing on BERT_Large showed negligible accuracy loss. Compared to traditional memristor crossbars, our architecture achieves enhancements of up to 39X in area overhead and 18X in energy consumption. Compared to modern TPU/GPU systems, our architecture demonstrates at least a 68X reduction in the area-delay product and a significant 69% energy consumption reduction.
PATCorrect: Non-autoregressive Phoneme-augmented Transformer for ASR Error Correction
Feb 10, 2023Speech-to-text errors made by automatic speech recognition (ASR) system negatively impact downstream models relying on ASR transcriptions. Language error correction models as a post-processing text editing approach have been recently developed for refining the source sentences. However, efficient models for correcting errors in ASR transcriptions that meet the low latency requirements of industrial grade production systems have not been well studied. In this work, we propose a novel non-autoregressive (NAR) error correction approach to improve the transcription quality by reducing word error rate (WER) and achieve robust performance across different upstream ASR systems. Our approach augments the text encoding of the Transformer model with a phoneme encoder that embeds pronunciation information. The representations from phoneme encoder and text encoder are combined via multi-modal fusion before feeding into the length tagging predictor for predicting target sequence lengths. The joint encoders also provide inputs to the attention mechanism in the NAR decoder. We experiment on 3 open-source ASR systems with varying speech-to-text transcription quality and their erroneous transcriptions on 2 public English corpus datasets. Results show that our PATCorrect (Phoneme Augmented Transformer for ASR error Correction) consistently outperforms state-of-the-art NAR error correction method on English corpus across different upstream ASR systems. For example, PATCorrect achieves 11.62% WER reduction (WERR) averaged on 3 ASR systems compared to 9.46% WERR achieved by other method using text only modality and also achieves an inference latency comparable to other NAR models at tens of millisecond scale, especially on GPU hardware, while still being 4.2 - 6.7x times faster than autoregressive models on Common Voice and LibriSpeech datasets.
Ultrafast CMOS image sensors and data-enabled super-resolution for multimodal radiographic imaging and tomography
Jan 27, 2023
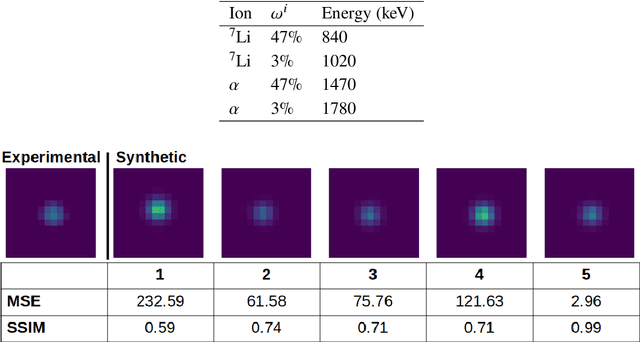
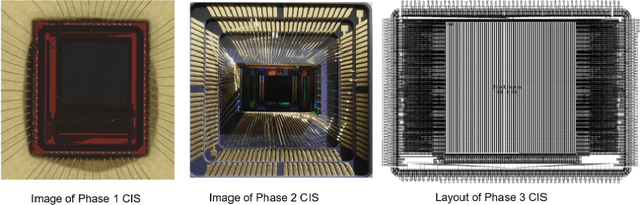
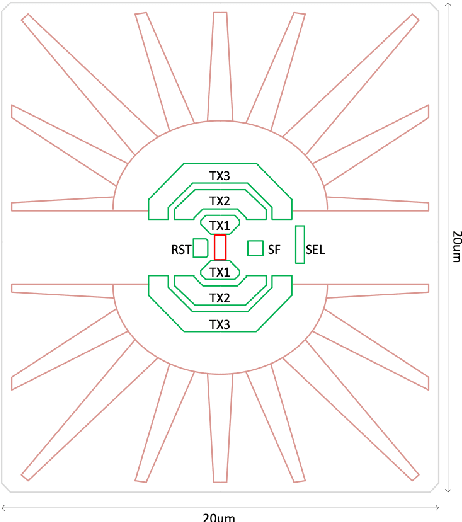
We summarize recent progress in ultrafast Complementary Metal Oxide Semiconductor (CMOS) image sensor development and the application of neural networks for post-processing of CMOS and charge-coupled device (CCD) image data to achieve sub-pixel resolution (thus $super$-$resolution$). The combination of novel CMOS pixel designs and data-enabled image post-processing provides a promising path towards ultrafast high-resolution multi-modal radiographic imaging and tomography applications.
A Resource-efficient Spiking Neural Network Accelerator Supporting Emerging Neural Encoding
Jun 06, 2022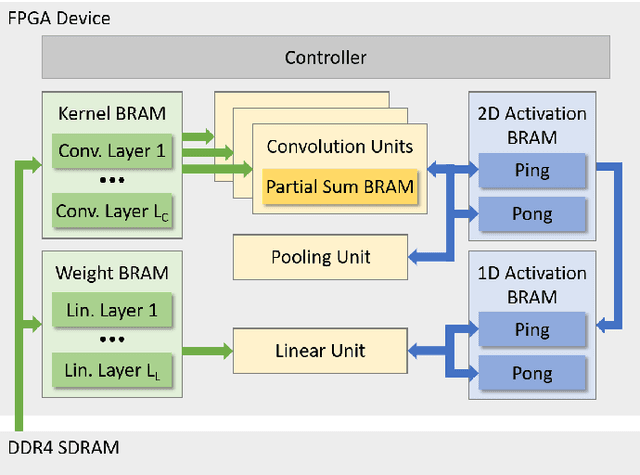
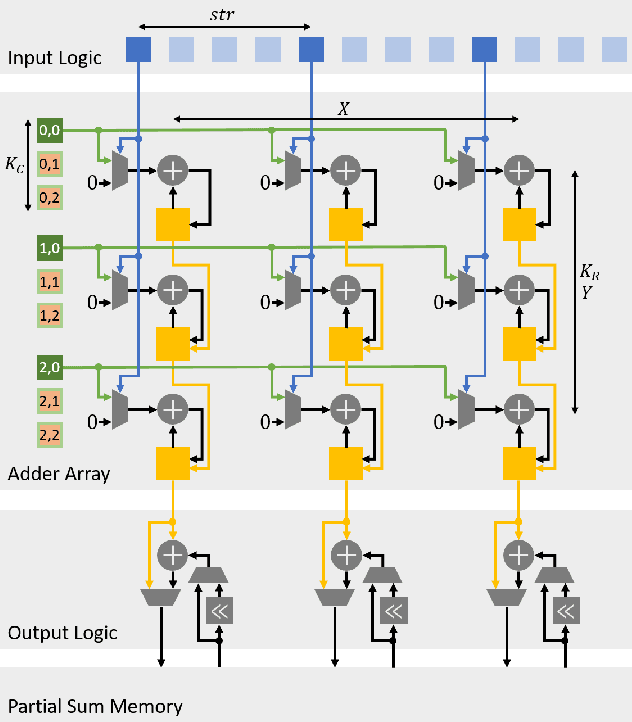
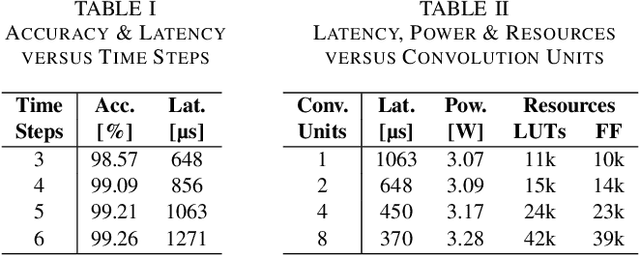
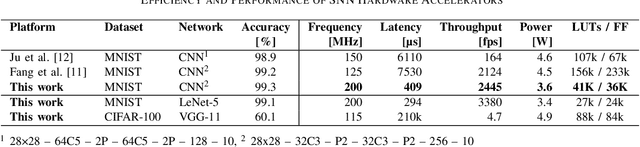
Spiking neural networks (SNNs) recently gained momentum due to their low-power multiplication-free computing and the closer resemblance of biological processes in the nervous system of humans. However, SNNs require very long spike trains (up to 1000) to reach an accuracy similar to their artificial neural network (ANN) counterparts for large models, which offsets efficiency and inhibits its application to low-power systems for real-world use cases. To alleviate this problem, emerging neural encoding schemes are proposed to shorten the spike train while maintaining the high accuracy. However, current accelerators for SNN cannot well support the emerging encoding schemes. In this work, we present a novel hardware architecture that can efficiently support SNN with emerging neural encoding. Our implementation features energy and area efficient processing units with increased parallelism and reduced memory accesses. We verified the accelerator on FPGA and achieve 25% and 90% improvement over previous work in power consumption and latency, respectively. At the same time, high area efficiency allows us to scale for large neural network models. To the best of our knowledge, this is the first work to deploy the large neural network model VGG on physical FPGA-based neuromorphic hardware.
Machine Learning for Detection of 3D Features using sparse X-ray data
Jun 02, 2022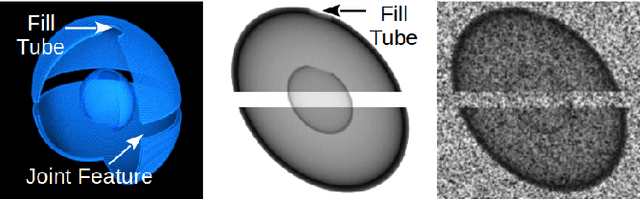
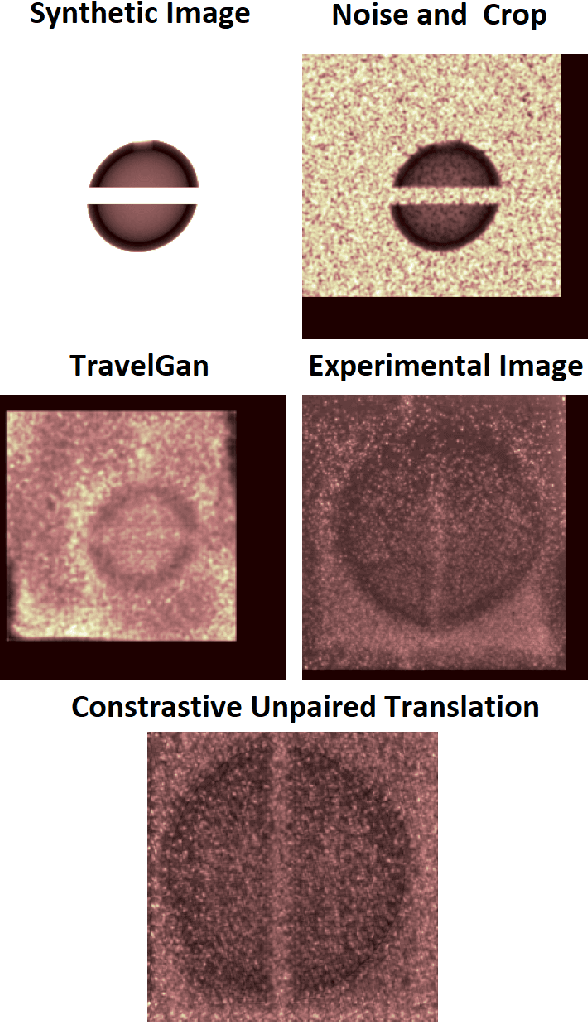
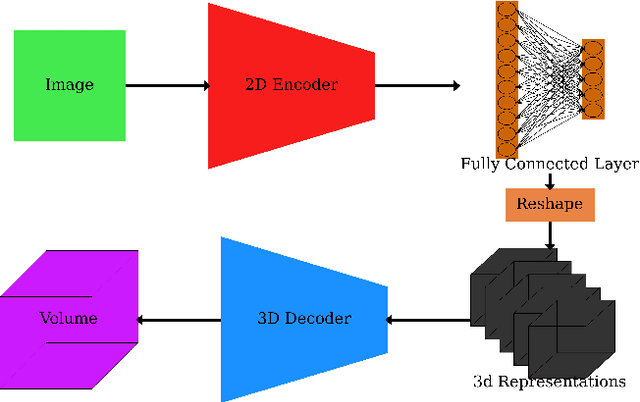
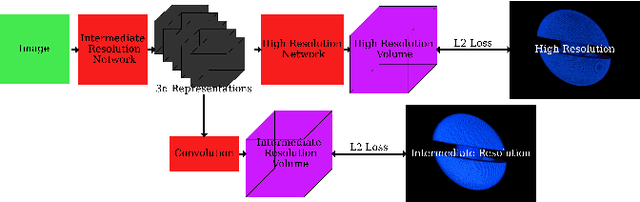
In many inertial confinement fusion experiments, the neutron yield and other parameters cannot be completely accounted for with one and two dimensional models. This discrepancy suggests that there are three dimensional effects which may be significant. Sources of these effects include defects in the shells and shell interfaces, the fill tube of the capsule, and the joint feature in double shell targets. Due to their ability to penetrate materials, X-rays are used to capture the internal structure of objects. Methods such as Computational Tomography use X-ray radiographs from hundreds of projections in order to reconstruct a three dimensional model of the object. In experimental environments, such as the National Ignition Facility and Omega-60, the availability of these views is scarce and in many cases only consist of a single line of sight. Mathematical reconstruction of a 3D object from sparse views is an ill-posed inverse problem. These types of problems are typically solved by utilizing prior information. Neural networks have been used for the task of 3D reconstruction as they are capable of encoding and leveraging this prior information. We utilize half a dozen different convolutional neural networks to produce different 3D representations of ICF implosions from the experimental data. We utilize deep supervision to train a neural network to produce high resolution reconstructions. We use these representations to track 3D features of the capsules such as the ablator, inner shell, and the joint between shell hemispheres. Machine learning, supplemented by different priors, is a promising method for 3D reconstructions in ICF and X-ray radiography in general.
Optimizing for In-memory Deep Learning with Emerging Memory Technology
Dec 01, 2021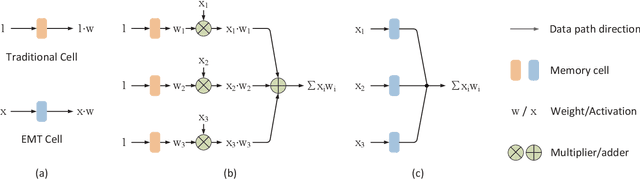
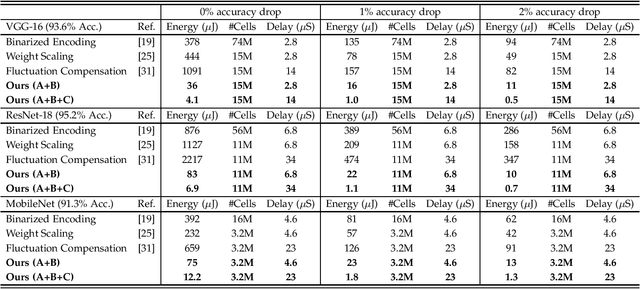
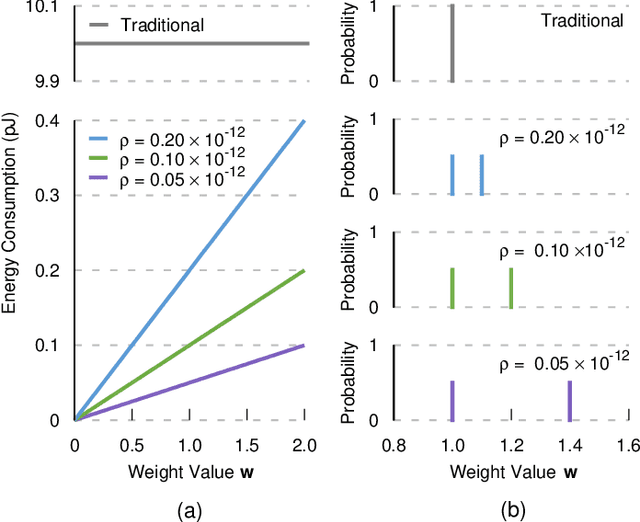
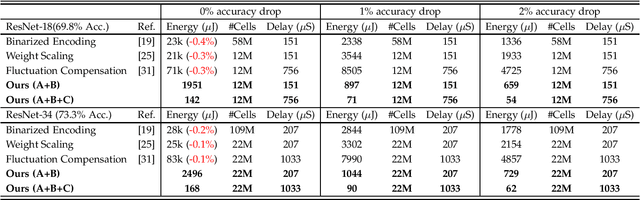
In-memory deep learning computes neural network models where they are stored, thus avoiding long distance communication between memory and computation units, resulting in considerable savings in energy and time. In-memory deep learning has already demonstrated orders of magnitude higher performance density and energy efficiency. The use of emerging memory technology promises to increase the gains in density, energy, and performance even further. However, emerging memory technology is intrinsically unstable, resulting in random fluctuations of data reads. This can translate to non-negligible accuracy loss, potentially nullifying the gains. In this paper, we propose three optimization techniques that can mathematically overcome the instability problem of emerging memory technology. They can improve the accuracy of the in-memory deep learning model while maximizing its energy efficiency. Experiments show that our solution can fully recover most models' state-of-the-art accuracy, and achieves at least an order of magnitude higher energy efficiency than the state-of-the-art.
E3NE: An End-to-End Framework for Accelerating Spiking Neural Networks with Emerging Neural Encoding on FPGAs
Nov 19, 2021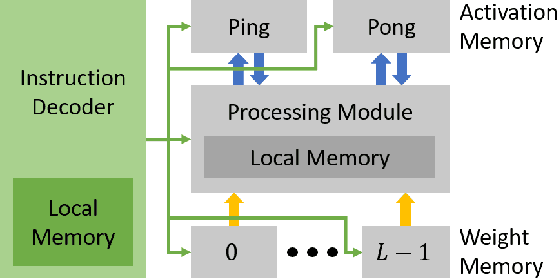

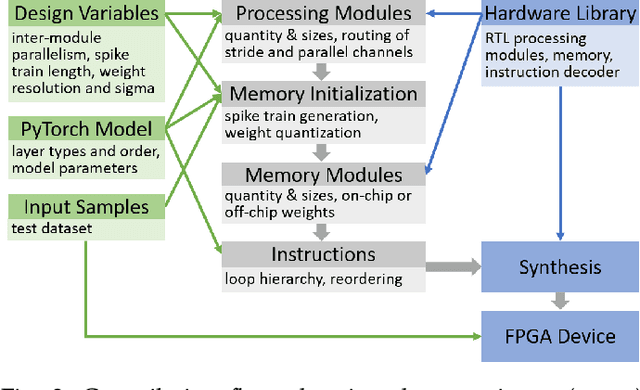
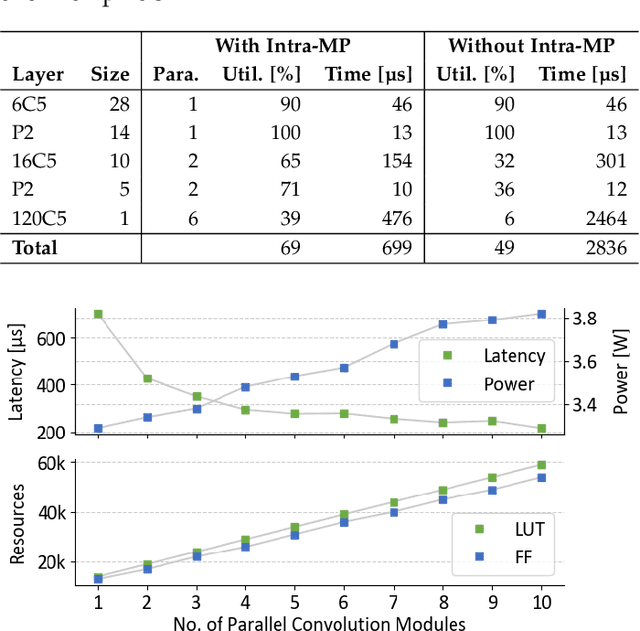
Compiler frameworks are crucial for the widespread use of FPGA-based deep learning accelerators. They allow researchers and developers, who are not familiar with hardware engineering, to harness the performance attained by domain-specific logic. There exists a variety of frameworks for conventional artificial neural networks. However, not much research effort has been put into the creation of frameworks optimized for spiking neural networks (SNNs). This new generation of neural networks becomes increasingly interesting for the deployment of AI on edge devices, which have tight power and resource constraints. Our end-to-end framework E3NE automates the generation of efficient SNN inference logic for FPGAs. Based on a PyTorch model and user parameters, it applies various optimizations and assesses trade-offs inherent to spike-based accelerators. Multiple levels of parallelism and the use of an emerging neural encoding scheme result in an efficiency superior to previous SNN hardware implementations. For a similar model, E3NE uses less than 50% of hardware resources and 20% less power, while reducing the latency by an order of magnitude. Furthermore, scalability and generality allowed the deployment of the large-scale SNN models AlexNet and VGG.
Efficient Spiking Neural Networks with Radix Encoding
May 14, 2021
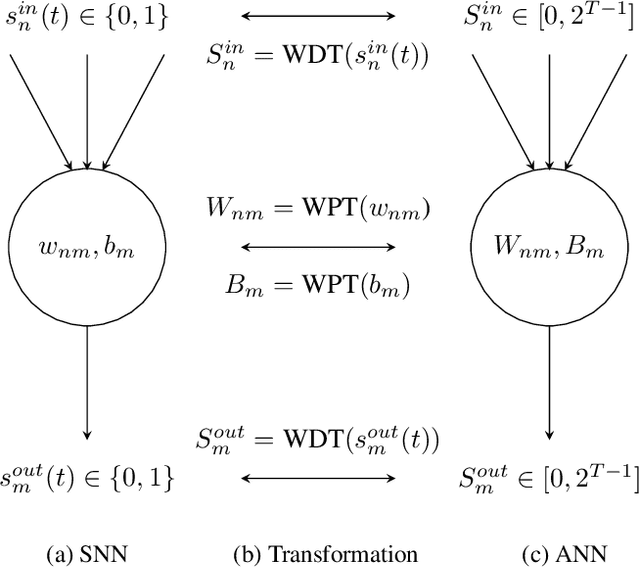
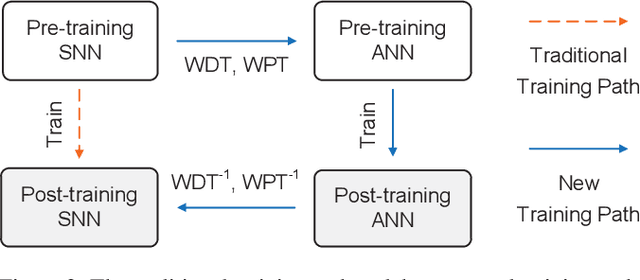
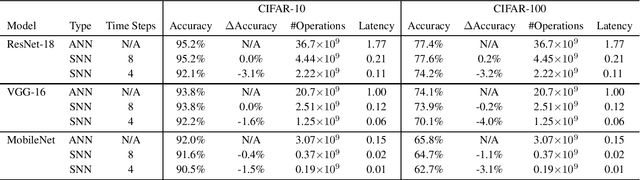
Spiking neural networks (SNNs) have advantages in latency and energy efficiency over traditional artificial neural networks (ANNs) due to its event-driven computation mechanism and replacement of energy-consuming weight multiplications with additions. However, in order to reach accuracy of its ANN counterpart, it usually requires long spike trains to ensure the accuracy. Traditionally, a spike train needs around one thousand time steps to approach similar accuracy as its ANN counterpart. This offsets the computation efficiency brought by SNNs because longer spike trains mean a larger number of operations and longer latency. In this paper, we propose a radix encoded SNN with ultra-short spike trains. In the new model, the spike train takes less than ten time steps. Experiments show that our method demonstrates 25X speedup and 1.1% increment on accuracy, compared with the state-of-the-art work on VGG-16 network architecture and CIFAR-10 dataset.
EDCompress: Energy-Aware Model Compression with Dataflow
Jun 08, 2020

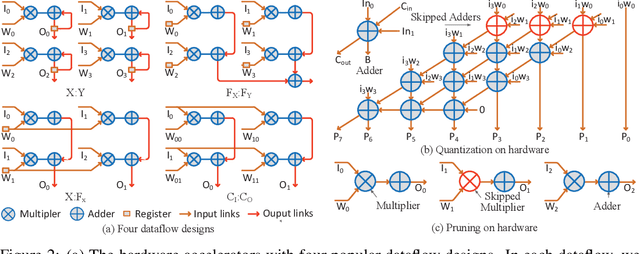
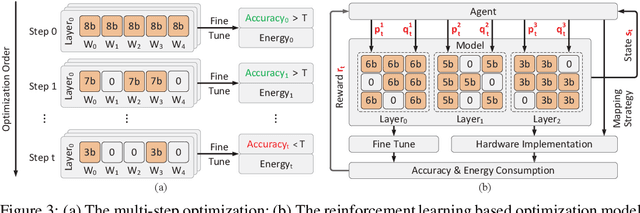
Edge devices demand low energy consumption, cost and small form factor. To efficiently deploy convolutional neural network (CNN) models on edge device, energy-aware model compression becomes extremely important. However, existing work did not study this problem well because the lack of considering the diversity of dataflow in hardware architectures. In this paper, we propose EDCompress, an Energy-aware model compression method, which can effectively reduce the energy consumption and area overhead of hardware accelerators, with different Dataflows. Considering the very nature of model compression procedures, we recast the optimization process to a multi-step problem, and solve it by reinforcement learning algorithms. Experiments show that EDCompress could improve 20X, 17X, 37X energy efficiency in VGG-16, MobileNet, LeNet-5 networks, respectively, with negligible loss of accuracy. EDCompress could also find the optimal dataflow type for specific neural networks in terms of energy consumption and area overhead, which can guide the deployment of CNN models on hardware systems.
The ISTI Rapid Response on Exploring Cloud Computing 2018
Jan 04, 2019
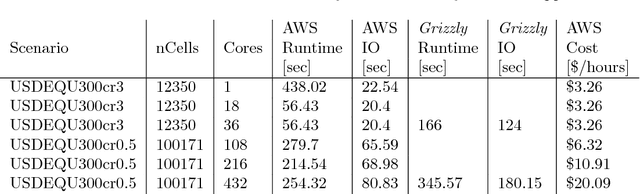
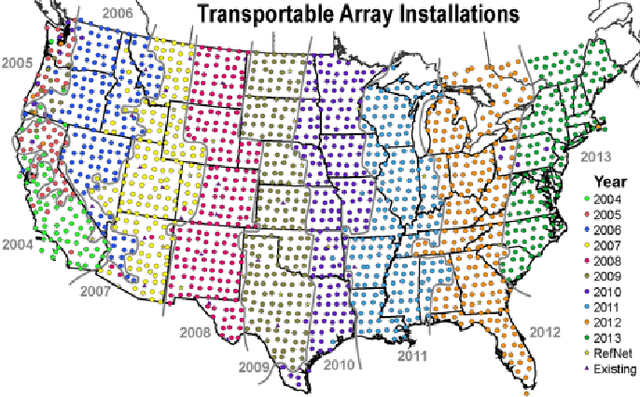

This report describes eighteen projects that explored how commercial cloud computing services can be utilized for scientific computation at national laboratories. These demonstrations ranged from deploying proprietary software in a cloud environment to leveraging established cloud-based analytics workflows for processing scientific datasets. By and large, the projects were successful and collectively they suggest that cloud computing can be a valuable computational resource for scientific computation at national laboratories.