 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFKAN: A KAN-Integrated Neural Operator For Efficient Magnetotelluric Forward Modeling
Feb 04, 2025



Magnetotelluric (MT) forward modeling is fundamental for improving the accuracy and efficiency of MT inversion. Neural operators (NOs) have been effectively used for rapid MT forward modeling, demonstrating their promising performance in solving the MT forward modeling-related partial differential equations (PDEs). Particularly, they can obtain the electromagnetic field at arbitrary locations and frequencies. In these NOs, the projection layers have been dominated by multi-layer perceptrons (MLPs), which may potentially reduce the accuracy of solution due to they usually suffer from the disadvantages of MLPs, such as lack of interpretability, overfitting, and so on. Therefore, to improve the accuracy of MT forward modeling with NOs and explore the potential alternatives to MLPs, we propose a novel neural operator by extending the Fourier neural operator (FNO) with Kolmogorov-Arnold network (EFKAN). Within the EFKAN framework, the FNO serves as the branch network to calculate the apparent resistivity and phase from the resistivity model in the frequency domain. Meanwhile, the KAN acts as the trunk network to project the resistivity and phase, determined by the FNO, to the desired locations and frequencies. Experimental results demonstrate that the proposed method not only achieves higher accuracy in obtaining apparent resistivity and phase compared to the NO equipped with MLPs at the desired frequencies and locations but also outperforms traditional numerical methods in terms of computational speed.
Hierarchical Weight Averaging for Deep Neural Networks
Apr 23, 2023



Despite the simplicity, stochastic gradient descent (SGD)-like algorithms are successful in training deep neural networks (DNNs). Among various attempts to improve SGD, weight averaging (WA), which averages the weights of multiple models, has recently received much attention in the literature. Broadly, WA falls into two categories: 1) online WA, which averages the weights of multiple models trained in parallel, is designed for reducing the gradient communication overhead of parallel mini-batch SGD, and 2) offline WA, which averages the weights of one model at different checkpoints, is typically used to improve the generalization ability of DNNs. Though online and offline WA are similar in form, they are seldom associated with each other. Besides, these methods typically perform either offline parameter averaging or online parameter averaging, but not both. In this work, we firstly attempt to incorporate online and offline WA into a general training framework termed Hierarchical Weight Averaging (HWA). By leveraging both the online and offline averaging manners, HWA is able to achieve both faster convergence speed and superior generalization performance without any fancy learning rate adjustment. Besides, we also analyze the issues faced by existing WA methods, and how our HWA address them, empirically. Finally, extensive experiments verify that HWA outperforms the state-of-the-art methods significantly.
A Resource-efficient Spiking Neural Network Accelerator Supporting Emerging Neural Encoding
Jun 06, 2022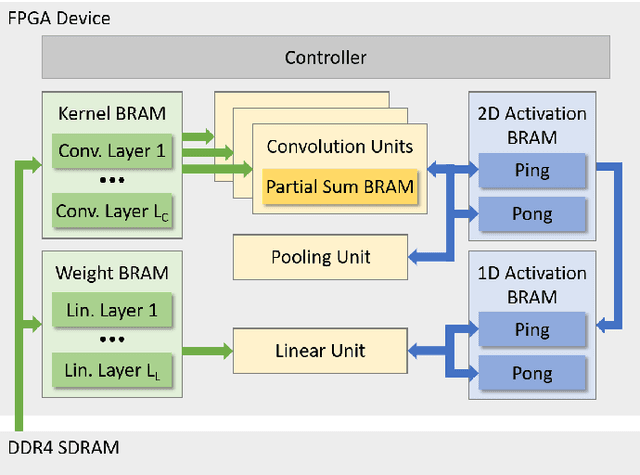
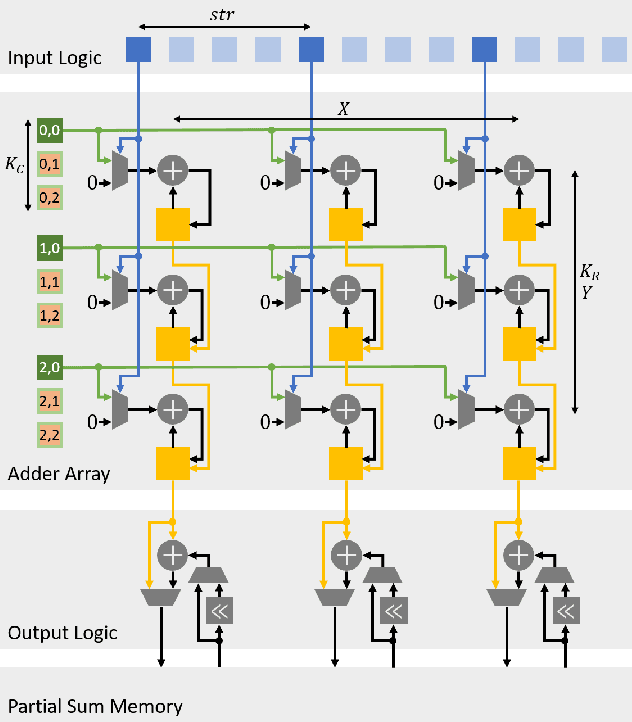
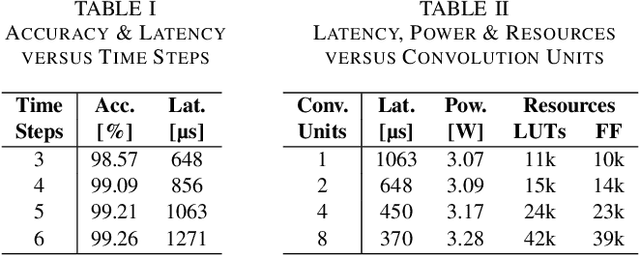
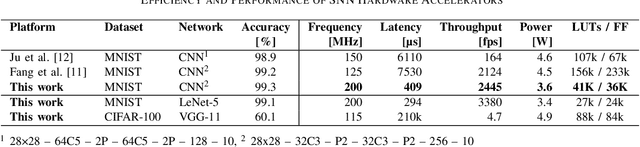
Spiking neural networks (SNNs) recently gained momentum due to their low-power multiplication-free computing and the closer resemblance of biological processes in the nervous system of humans. However, SNNs require very long spike trains (up to 1000) to reach an accuracy similar to their artificial neural network (ANN) counterparts for large models, which offsets efficiency and inhibits its application to low-power systems for real-world use cases. To alleviate this problem, emerging neural encoding schemes are proposed to shorten the spike train while maintaining the high accuracy. However, current accelerators for SNN cannot well support the emerging encoding schemes. In this work, we present a novel hardware architecture that can efficiently support SNN with emerging neural encoding. Our implementation features energy and area efficient processing units with increased parallelism and reduced memory accesses. We verified the accelerator on FPGA and achieve 25% and 90% improvement over previous work in power consumption and latency, respectively. At the same time, high area efficiency allows us to scale for large neural network models. To the best of our knowledge, this is the first work to deploy the large neural network model VGG on physical FPGA-based neuromorphic hardware.
E3NE: An End-to-End Framework for Accelerating Spiking Neural Networks with Emerging Neural Encoding on FPGAs
Nov 19, 2021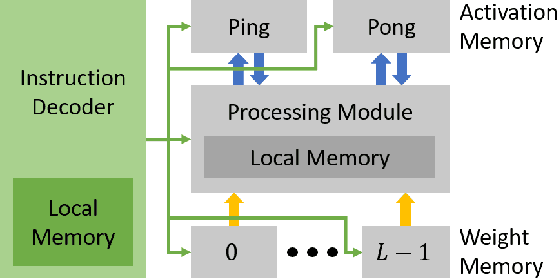

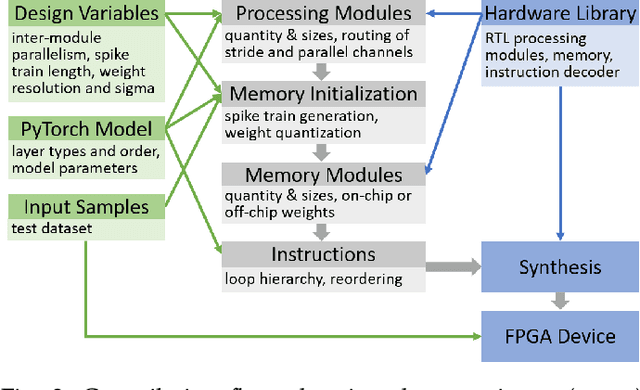
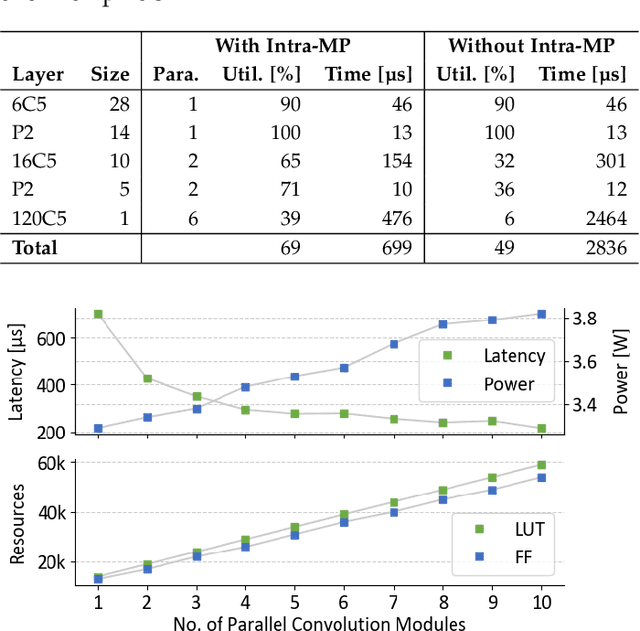
Compiler frameworks are crucial for the widespread use of FPGA-based deep learning accelerators. They allow researchers and developers, who are not familiar with hardware engineering, to harness the performance attained by domain-specific logic. There exists a variety of frameworks for conventional artificial neural networks. However, not much research effort has been put into the creation of frameworks optimized for spiking neural networks (SNNs). This new generation of neural networks becomes increasingly interesting for the deployment of AI on edge devices, which have tight power and resource constraints. Our end-to-end framework E3NE automates the generation of efficient SNN inference logic for FPGAs. Based on a PyTorch model and user parameters, it applies various optimizations and assesses trade-offs inherent to spike-based accelerators. Multiple levels of parallelism and the use of an emerging neural encoding scheme result in an efficiency superior to previous SNN hardware implementations. For a similar model, E3NE uses less than 50% of hardware resources and 20% less power, while reducing the latency by an order of magnitude. Furthermore, scalability and generality allowed the deployment of the large-scale SNN models AlexNet and VGG.
Efficient Spiking Neural Networks with Radix Encoding
May 14, 2021
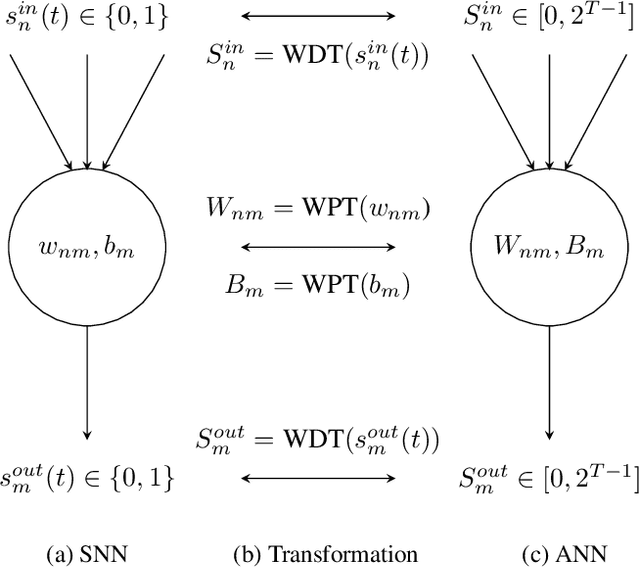
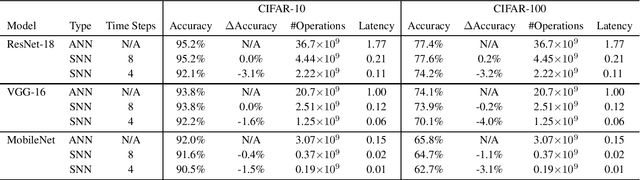
Spiking neural networks (SNNs) have advantages in latency and energy efficiency over traditional artificial neural networks (ANNs) due to its event-driven computation mechanism and replacement of energy-consuming weight multiplications with additions. However, in order to reach accuracy of its ANN counterpart, it usually requires long spike trains to ensure the accuracy. Traditionally, a spike train needs around one thousand time steps to approach similar accuracy as its ANN counterpart. This offsets the computation efficiency brought by SNNs because longer spike trains mean a larger number of operations and longer latency. In this paper, we propose a radix encoded SNN with ultra-short spike trains. In the new model, the spike train takes less than ten time steps. Experiments show that our method demonstrates 25X speedup and 1.1% increment on accuracy, compared with the state-of-the-art work on VGG-16 network architecture and CIFAR-10 dataset.
Towards Safe Machine Learning for CPS: Infer Uncertainty from Training Data
Sep 11, 2019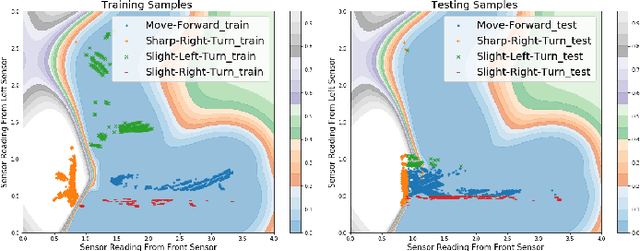
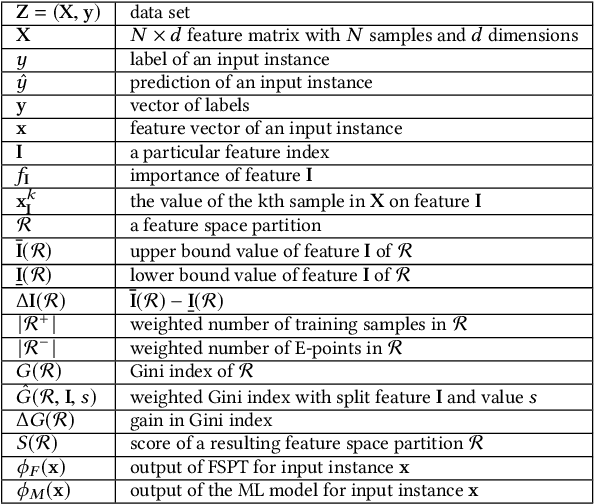
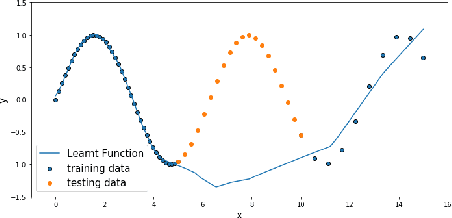

Machine learning (ML) techniques are increasingly applied to decision-making and control problems in Cyber-Physical Systems among which many are safety-critical, e.g., chemical plants, robotics, autonomous vehicles. Despite the significant benefits brought by ML techniques, they also raise additional safety issues because 1) most expressive and powerful ML models are not transparent and behave as a black box and 2) the training data which plays a crucial role in ML safety is usually incomplete. An important technique to achieve safety for ML models is "Safe Fail", i.e., a model selects a reject option and applies the backup solution, a traditional controller or a human operator for example, when it has low confidence in a prediction. Data-driven models produced by ML algorithms learn from training data, and hence they are only as good as the examples they have learnt. As pointed in [17], ML models work well in the "training space" (i.e., feature space with sufficient training data), but they could not extrapolate beyond the training space. As observed in many previous studies, a feature space that lacks training data generally has a much higher error rate than the one that contains sufficient training samples [31]. Therefore, it is essential to identify the training space and avoid extrapolating beyond the training space. In this paper, we propose an efficient Feature Space Partitioning Tree (FSPT) to address this problem. Using experiments, we also show that, a strong relationship exists between model performance and FSPT score.
* Publication rights licensed to ACM