 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: Cross-Attentional Flow Transformer for Robust Optical Flow
Mar 31, 2022
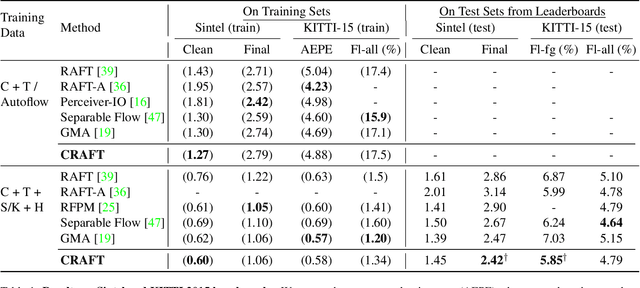
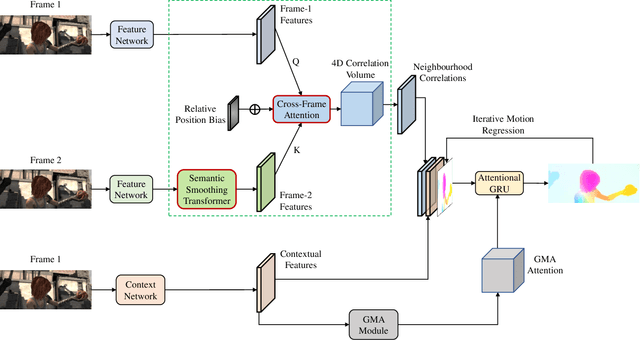
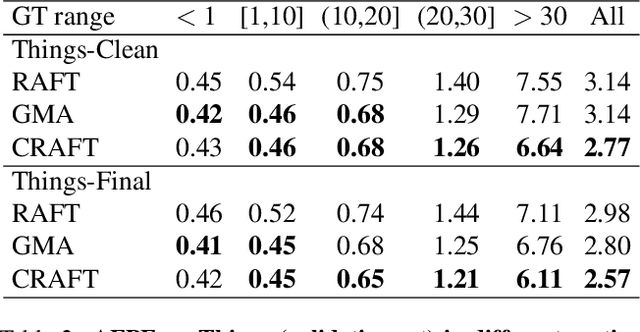
Optical flow estimation aims to find the 2D motion field by identifying corresponding pixels between two images. Despite the tremendous progress of deep learning-based optical flow methods, it remains a challenge to accurately estimate large displacements with motion blur. This is mainly because the correlation volume, the basis of pixel matching, is computed as the dot product of the convolutional features of the two images. The locality of convolutional features makes the computed correlations susceptible to various noises. On large displacements with motion blur, noisy correlations could cause severe errors in the estimated flow. To overcome this challenge, we propose a new architecture "CRoss-Attentional Flow Transformer" (CRAFT), aiming to revitalize the correlation volume computation. In CRAFT, a Semantic Smoothing Transformer layer transforms the features of one frame, making them more global and semantically stable. In addition, the dot-product correlations are replaced with transformer Cross-Frame Attention. This layer filters out feature noises through the Query and Key projections, and computes more accurate correlations. On Sintel (Final) and KITTI (foreground) benchmarks, CRAFT has achieved new state-of-the-art performance. Moreover, to test the robustness of different models on large motions, we designed an image shifting attack that shifts input images to generate large artificial motions. Under this attack, CRAFT performs much more robustly than two representative methods, RAFT and GMA. The code of CRAFT is is available at https://github.com/askerlee/craft.
Medical Image Segmentation Using Squeeze-and-Expansion Transformers
Jun 02, 2021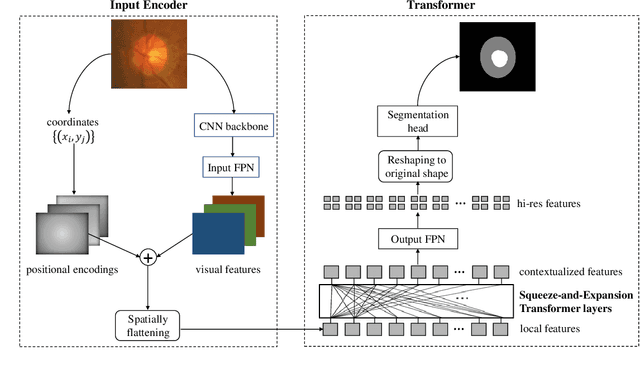

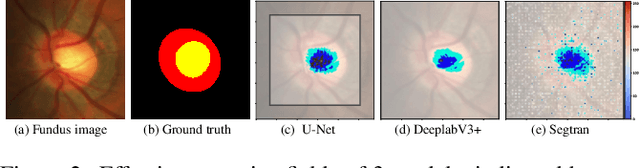
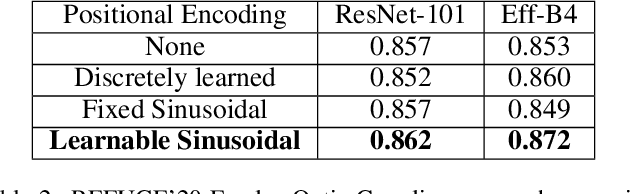
Medical image segmentation is important for computer-aided diagnosis. Good segmentation demands the model to see the big picture and fine details simultaneously, i.e., to learn image features that incorporate large context while keep high spatial resolutions. To approach this goal, the most widely used methods -- U-Net and variants, extract and fuse multi-scale features. However, the fused features still have small "effective receptive fields" with a focus on local image cues, limiting their performance. In this work, we propose Segtran, an alternative segmentation framework based on transformers, which have unlimited "effective receptive fields" even at high feature resolutions. The core of Segtran is a novel Squeeze-and-Expansion transformer: a squeezed attention block regularizes the self attention of transformers, and an expansion block learns diversified representations. Additionally, we propose a new positional encoding scheme for transformers, imposing a continuity inductive bias for images. Experiments were performed on 2D and 3D medical image segmentation tasks: optic disc/cup segmentation in fundus images (REFUGE'20 challenge), polyp segmentation in colonoscopy images, and brain tumor segmentation in MRI scans (BraTS'19 challenge). Compared with representative existing methods, Segtran consistently achieved the highest segmentation accuracy, and exhibited good cross-domain generalization capabilities. The source code of Segtran is released at https://github.com/askerlee/segtran.
DTNN: Energy-efficient Inference with Dendrite Tree Inspired Neural Networks for Edge Vision Applications
May 25, 2021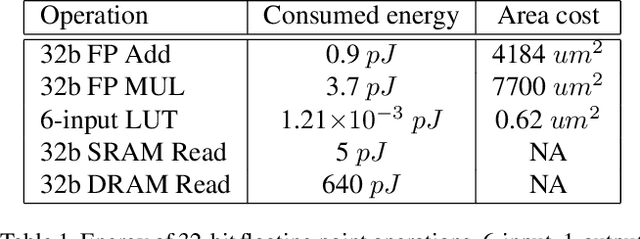
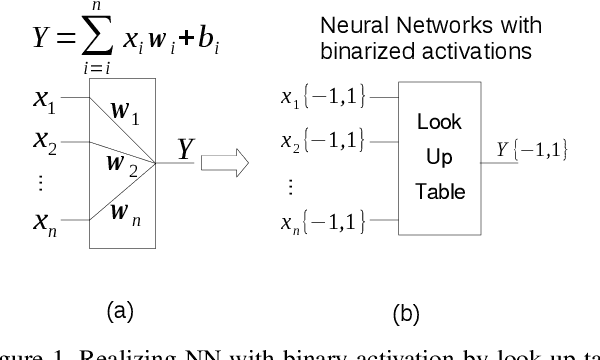

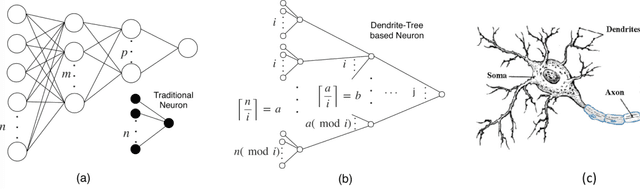
Deep neural networks (DNN) have achieved remarkable success in computer vision (CV). However, training and inference of DNN models are both memory and computation intensive, incurring significant overhead in terms of energy consumption and silicon area. In particular, inference is much more cost-sensitive than training because training can be done offline with powerful platforms, while inference may have to be done on battery powered devices with constrained form factors, especially for mobile or edge vision applications. In order to accelerate DNN inference, model quantization was proposed. However previous works only focus on the quantization rate without considering the efficiency of operations. In this paper, we propose Dendrite-Tree based Neural Network (DTNN) for energy-efficient inference with table lookup operations enabled by activation quantization. In DTNN both costly weight access and arithmetic computations are eliminated for inference. We conducted experiments on various kinds of DNN models such as LeNet-5, MobileNet, VGG, and ResNet with different datasets, including MNIST, Cifar10/Cifar100, SVHN, and ImageNet. DTNN achieved significant energy saving (19.4X and 64.9X improvement on ResNet-18 and VGG-11 with ImageNet, respectively) with negligible loss of accuracy. To further validate the effectiveness of DTNN and compare with state-of-the-art low energy implementation for edge vision, we design and implement DTNN based MLP image classifiers using off-the-shelf FPGAs. The results show that DTNN on the FPGA, with higher accuracy, could achieve orders of magnitude better energy consumption and latency compared with the state-of-the-art low energy approaches reported that use ASIC chips.
Efficient Spiking Neural Networks with Radix Encoding
May 14, 2021
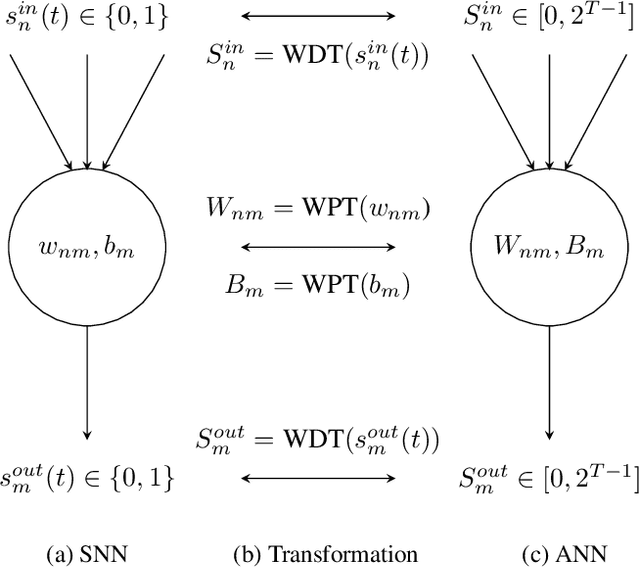
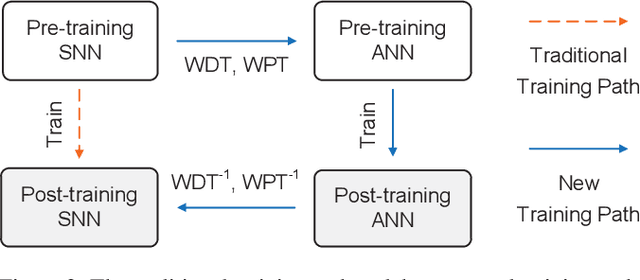
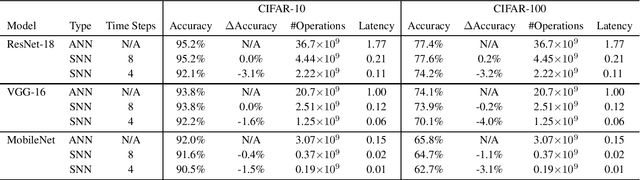
Spiking neural networks (SNNs) have advantages in latency and energy efficiency over traditional artificial neural networks (ANNs) due to its event-driven computation mechanism and replacement of energy-consuming weight multiplications with additions. However, in order to reach accuracy of its ANN counterpart, it usually requires long spike trains to ensure the accuracy. Traditionally, a spike train needs around one thousand time steps to approach similar accuracy as its ANN counterpart. This offsets the computation efficiency brought by SNNs because longer spike trains mean a larger number of operations and longer latency. In this paper, we propose a radix encoded SNN with ultra-short spike trains. In the new model, the spike train takes less than ten time steps. Experiments show that our method demonstrates 25X speedup and 1.1% increment on accuracy, compared with the state-of-the-art work on VGG-16 network architecture and CIFAR-10 dataset.
RCT: Resource Constrained Training for Edge AI
Mar 26, 2021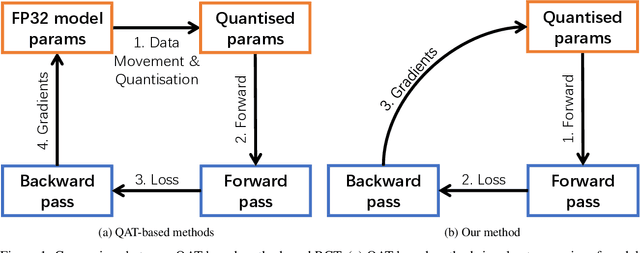
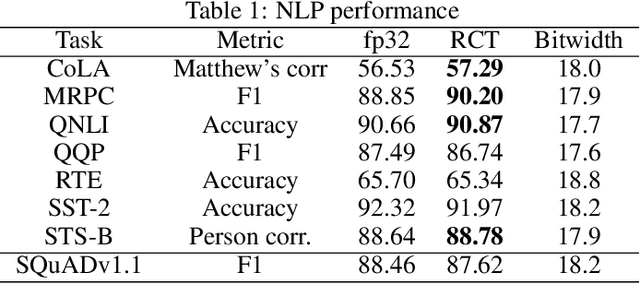
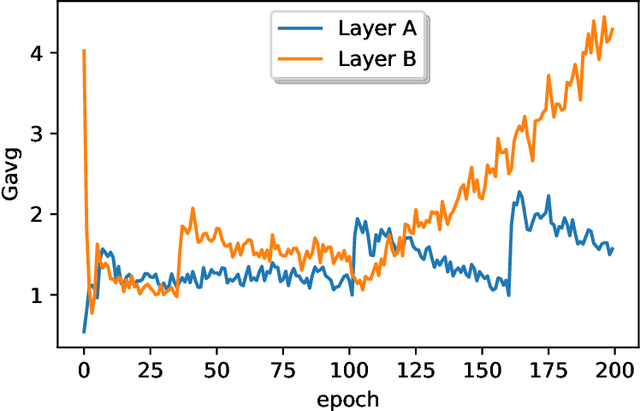
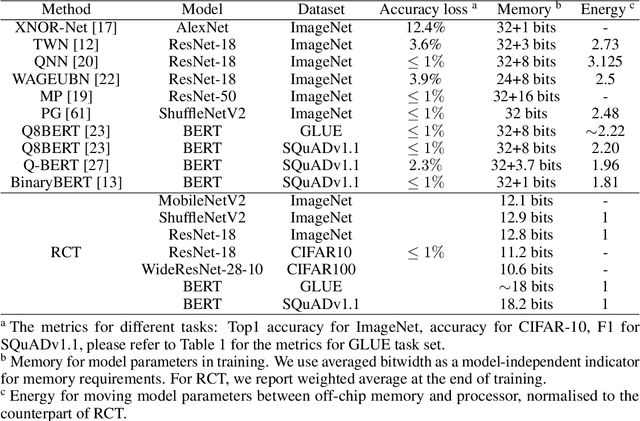
Neural networks training on edge terminals is essential for edge AI computing, which needs to be adaptive to evolving environment. Quantised models can efficiently run on edge devices, but existing training methods for these compact models are designed to run on powerful servers with abundant memory and energy budget. For example, quantisation-aware training (QAT) method involves two copies of model parameters, which is usually beyond the capacity of on-chip memory in edge devices. Data movement between off-chip and on-chip memory is energy demanding as well. The resource requirements are trivial for powerful servers, but critical for edge devices. To mitigate these issues, We propose Resource Constrained Training (RCT). RCT only keeps a quantised model throughout the training, so that the memory requirements for model parameters in training is reduced. It adjusts per-layer bitwidth dynamically in order to save energy when a model can learn effectively with lower precision. We carry out experiments with representative models and tasks in image application and natural language processing. Experiments show that RCT saves more than 86\% energy for General Matrix Multiply (GEMM) and saves more than 46\% memory for model parameters, with limited accuracy loss. Comparing with QAT-based method, RCT saves about half of energy on moving model parameters.