 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Grounding to Manipulation: Case Studies of Foundation Model Integration in Embodied Robotic Systems
May 21, 2025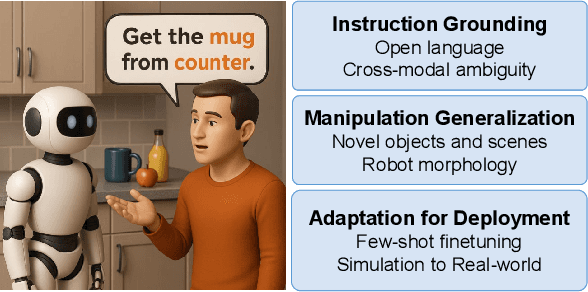



Foundation models (FMs) are increasingly used to bridge language and action in embodied agents, yet the operational characteristics of different FM integration strategies remain under-explored -- particularly for complex instruction following and versatile action generation in changing environments. This paper examines three paradigms for building robotic systems: end-to-end vision-language-action (VLA) models that implicitly integrate perception and planning, and modular pipelines incorporating either vision-language models (VLMs) or multimodal large language models (LLMs). We evaluate these paradigms through two focused case studies: a complex instruction grounding task assessing fine-grained instruction understanding and cross-modal disambiguation, and an object manipulation task targeting skill transfer via VLA finetuning. Our experiments in zero-shot and few-shot settings reveal trade-offs in generalization and data efficiency. By exploring performance limits, we distill design implications for developing language-driven physical agents and outline emerging challenges and opportunities for FM-powered robotics in real-world conditions.
CRAFT: Cross-Attentional Flow Transformer for Robust Optical Flow
Mar 31, 2022
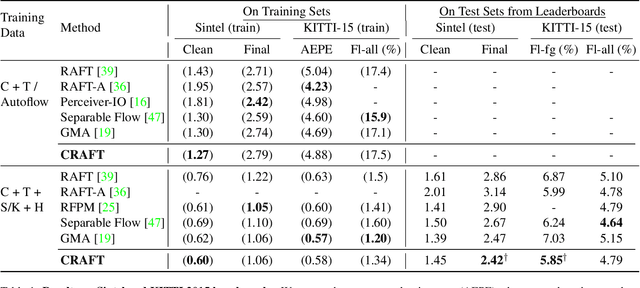
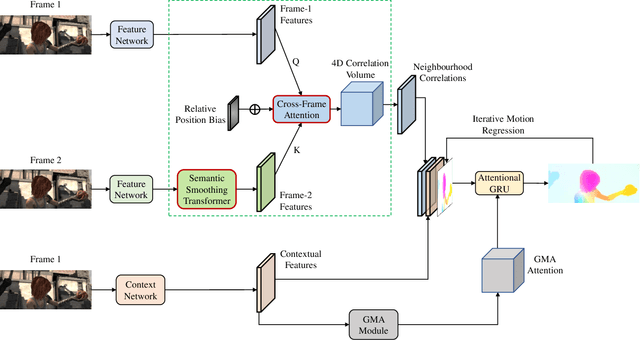
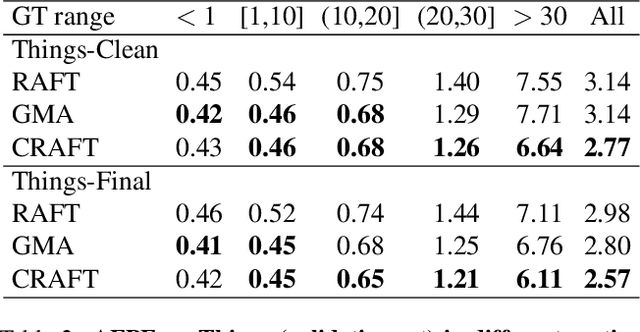
Optical flow estimation aims to find the 2D motion field by identifying corresponding pixels between two images. Despite the tremendous progress of deep learning-based optical flow methods, it remains a challenge to accurately estimate large displacements with motion blur. This is mainly because the correlation volume, the basis of pixel matching, is computed as the dot product of the convolutional features of the two images. The locality of convolutional features makes the computed correlations susceptible to various noises. On large displacements with motion blur, noisy correlations could cause severe errors in the estimated flow. To overcome this challenge, we propose a new architecture "CRoss-Attentional Flow Transformer" (CRAFT), aiming to revitalize the correlation volume computation. In CRAFT, a Semantic Smoothing Transformer layer transforms the features of one frame, making them more global and semantically stable. In addition, the dot-product correlations are replaced with transformer Cross-Frame Attention. This layer filters out feature noises through the Query and Key projections, and computes more accurate correlations. On Sintel (Final) and KITTI (foreground) benchmarks, CRAFT has achieved new state-of-the-art performance. Moreover, to test the robustness of different models on large motions, we designed an image shifting attack that shifts input images to generate large artificial motions. Under this attack, CRAFT performs much more robustly than two representative methods, RAFT and GMA. The code of CRAFT is is available at https://github.com/askerlee/craft.
Few-Shot Domain Adaptation with Polymorphic Transformers
Jul 10, 2021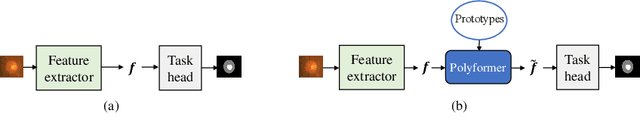

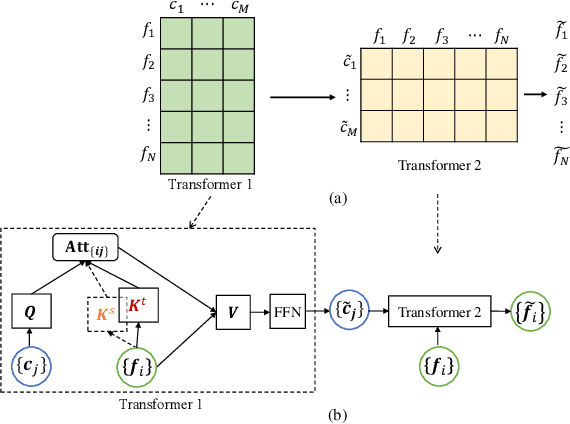
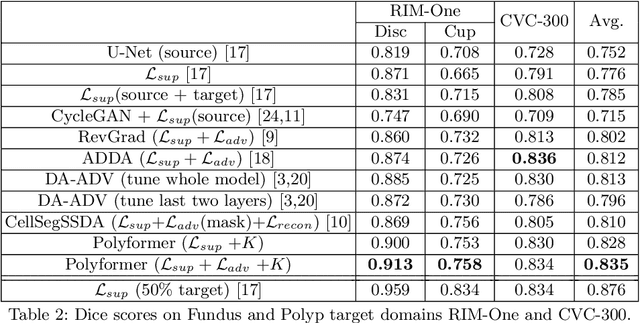
Deep neural networks (DNNs) trained on one set of medical images often experience severe performance drop on unseen test images, due to various domain discrepancy between the training images (source domain) and the test images (target domain), which raises a domain adaptation issue. In clinical settings, it is difficult to collect enough annotated target domain data in a short period. Few-shot domain adaptation, i.e., adapting a trained model with a handful of annotations, is highly practical and useful in this case. In this paper, we propose a Polymorphic Transformer (Polyformer), which can be incorporated into any DNN backbones for few-shot domain adaptation. Specifically, after the polyformer layer is inserted into a model trained on the source domain, it extracts a set of prototype embeddings, which can be viewed as a "basis" of the source-domain features. On the target domain, the polyformer layer adapts by only updating a projection layer which controls the interactions between image features and the prototype embeddings. All other model weights (except BatchNorm parameters) are frozen during adaptation. Thus, the chance of overfitting the annotations is greatly reduced, and the model can perform robustly on the target domain after being trained on a few annotated images. We demonstrate the effectiveness of Polyformer on two medical segmentation tasks (i.e., optic disc/cup segmentation, and polyp segmentation). The source code of Polyformer is released at https://github.com/askerlee/segtran.
Medical Image Segmentation Using Squeeze-and-Expansion Transformers
Jun 02, 2021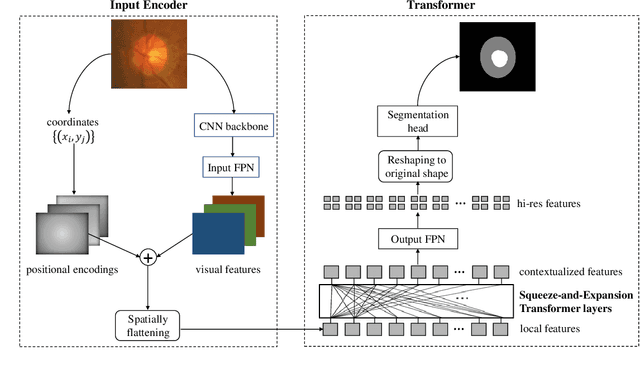

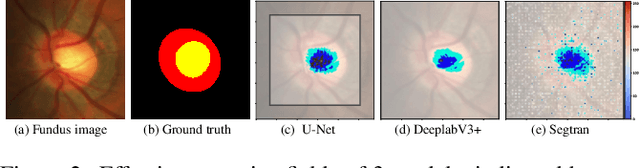
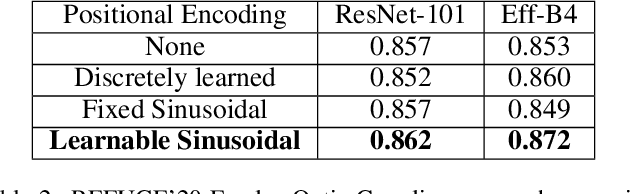
Medical image segmentation is important for computer-aided diagnosis. Good segmentation demands the model to see the big picture and fine details simultaneously, i.e., to learn image features that incorporate large context while keep high spatial resolutions. To approach this goal, the most widely used methods -- U-Net and variants, extract and fuse multi-scale features. However, the fused features still have small "effective receptive fields" with a focus on local image cues, limiting their performance. In this work, we propose Segtran, an alternative segmentation framework based on transformers, which have unlimited "effective receptive fields" even at high feature resolutions. The core of Segtran is a novel Squeeze-and-Expansion transformer: a squeezed attention block regularizes the self attention of transformers, and an expansion block learns diversified representations. Additionally, we propose a new positional encoding scheme for transformers, imposing a continuity inductive bias for images. Experiments were performed on 2D and 3D medical image segmentation tasks: optic disc/cup segmentation in fundus images (REFUGE'20 challenge), polyp segmentation in colonoscopy images, and brain tumor segmentation in MRI scans (BraTS'19 challenge). Compared with representative existing methods, Segtran consistently achieved the highest segmentation accuracy, and exhibited good cross-domain generalization capabilities. The source code of Segtran is released at https://github.com/askerlee/segtran.
Feature Lenses: Plug-and-play Neural Modules for Transformation-Invariant Visual Representations
Apr 12, 2020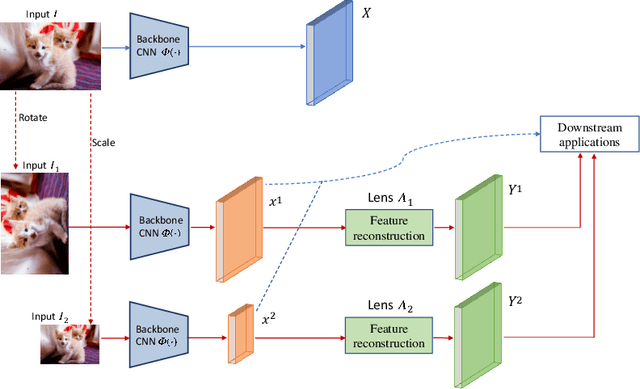
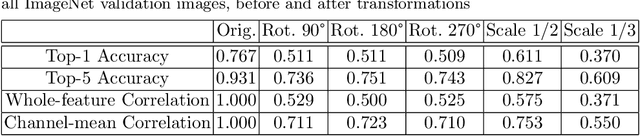
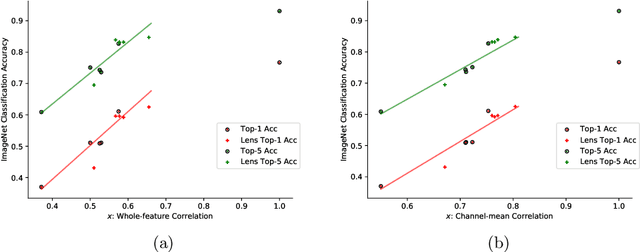
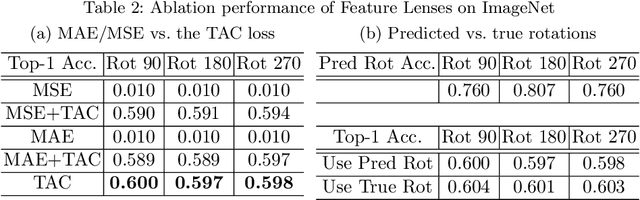
Convolutional Neural Networks (CNNs) are known to be brittle under various image transformations, including rotations, scalings, and changes of lighting conditions. We observe that the features of a transformed image are drastically different from the ones of the original image. To make CNNs more invariant to transformations, we propose "Feature Lenses", a set of ad-hoc modules that can be easily plugged into a trained model (referred to as the "host model"). Each individual lens reconstructs the original features given the features of a transformed image under a particular transformation. These lenses jointly counteract feature distortions caused by various transformations, thus making the host model more robust without retraining. By only updating lenses, the host model is freed from iterative updating when facing new transformations absent in the training data; as feature semantics are preserved, downstream applications, such as classifiers and detectors, automatically gain robustness without retraining. Lenses are trained in a self-supervised fashion with no annotations, by minimizing a novel "Top-K Activation Contrast Loss" between lens-transformed features and original features. Evaluated on ImageNet, MNIST-rot, and CIFAR-10, Feature Lenses show clear advantages over baseline methods.
RoboCoDraw: Robotic Avatar Drawing with GAN-based Style Transfer and Time-efficient Path Optimization
Dec 11, 2019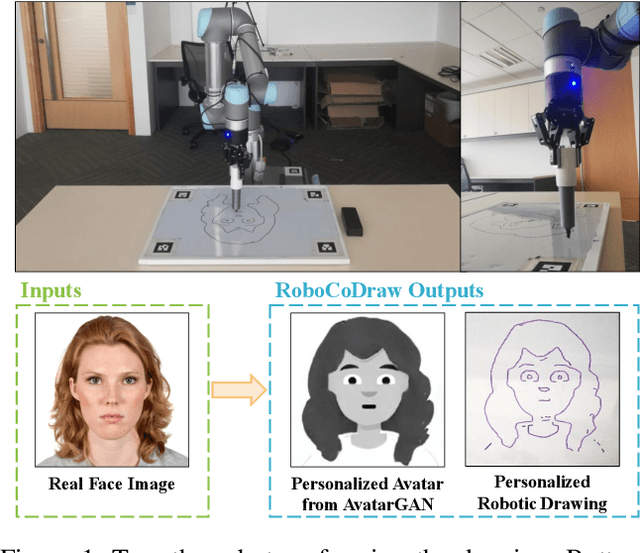
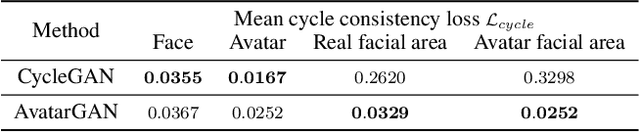

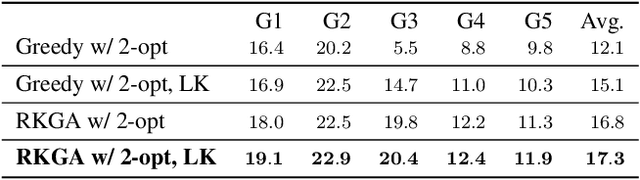
Robotic drawing has become increasingly popular as an entertainment and interactive tool. In this paper we present RoboCoDraw, a real-time collaborative robot-based drawing system that draws stylized human face sketches interactively in front of human users, by using the Generative Adversarial Network (GAN)-based style transfer and a Random-Key Genetic Algorithm (RKGA)-based path optimization. The proposed RoboCoDraw system takes a real human face image as input, converts it to a stylized avatar, then draws it with a robotic arm. A core component in this system is the Avatar-GAN proposed by us, which generates a cartoon avatar face image from a real human face. AvatarGAN is trained with unpaired face and avatar images only and can generate avatar images of much better likeness with human face images in comparison with the vanilla CycleGAN. After the avatar image is generated, it is fed to a line extraction algorithm and converted to sketches. An RKGA-based path optimization algorithm is applied to find a time-efficient robotic drawing path to be executed by the robotic arm. We demonstrate the capability of RoboCoDraw on various face images using a lightweight, safe collaborative robot UR5.
Multi-Instance Multi-Scale CNN for Medical Image Classification
Jul 31, 2019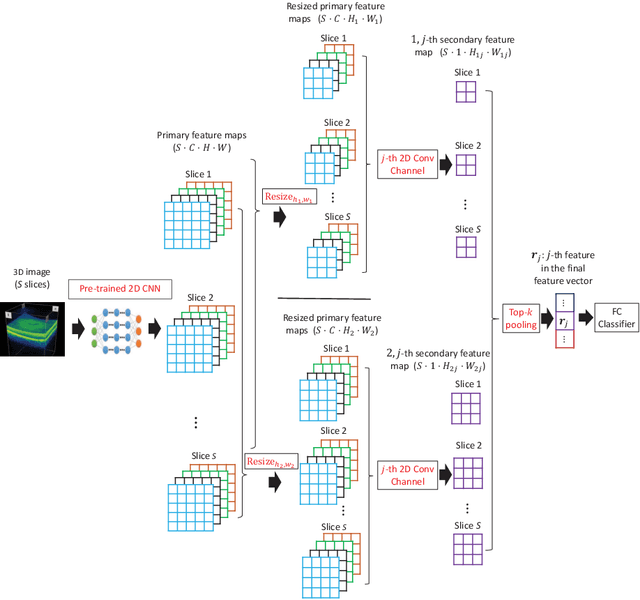
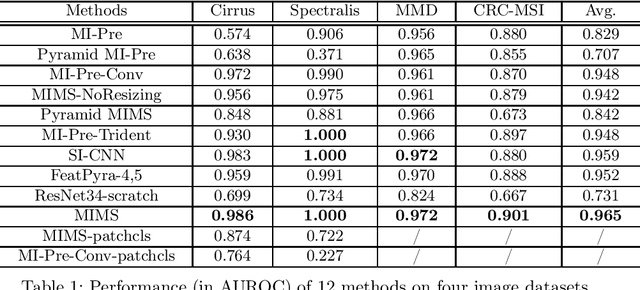
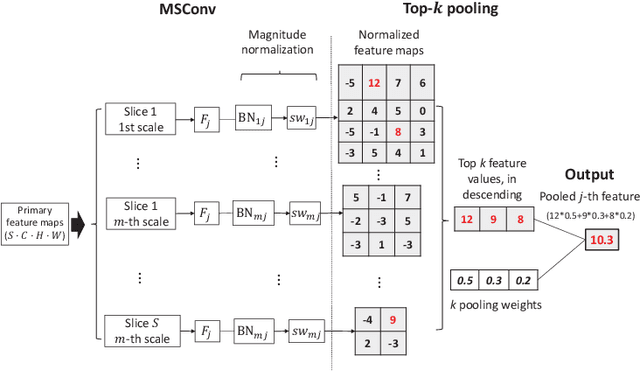

Deep learning for medical image classification faces three major challenges: 1) the number of annotated medical images for training are usually small; 2) regions of interest (ROIs) are relatively small with unclear boundaries in the whole medical images, and may appear in arbitrary positions across the x,y (and also z in 3D images) dimensions. However often only labels of the whole images are annotated, and localized ROIs are unavailable; and 3) ROIs in medical images often appear in varying sizes (scales). We approach these three challenges with a Multi-Instance Multi-Scale (MIMS) CNN: 1) We propose a multi-scale convolutional layer, which extracts patterns of different receptive fields with a shared set of convolutional kernels, so that scale-invariant patterns are captured by this compact set of kernels. As this layer contains only a small number of parameters, training on small datasets becomes feasible; 2) We propose a "top-k pooling" to aggregate the feature maps in varying scales from multiple spatial dimensions, allowing the model to be trained using weak annotations within the multiple instance learning (MIL) framework. Our method is shown to perform well on three classification tasks involving two 3D and two 2D medical image datasets.