 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit World Models for Reliable Human-Robot Collaboration
Jan 05, 2026This paper addresses the topic of robustness under sensing noise, ambiguous instructions, and human-robot interaction. We take a radically different tack to the issue of reliable embodied AI: instead of focusing on formal verification methods aimed at achieving model predictability and robustness, we emphasise the dynamic, ambiguous and subjective nature of human-robot interactions that requires embodied AI systems to perceive, interpret, and respond to human intentions in a manner that is consistent, comprehensible and aligned with human expectations. We argue that when embodied agents operate in human environments that are inherently social, multimodal, and fluid, reliability is contextually determined and only has meaning in relation to the goals and expectations of humans involved in the interaction. This calls for a fundamentally different approach to achieving reliable embodied AI that is centred on building and updating an accessible "explicit world model" representing the common ground between human and AI, that is used to align robot behaviours with human expectations.
From Grounding to Manipulation: Case Studies of Foundation Model Integration in Embodied Robotic Systems
May 21, 2025Foundation models (FMs) are increasingly used to bridge language and action in embodied agents, yet the operational characteristics of different FM integration strategies remain under-explored -- particularly for complex instruction following and versatile action generation in changing environments. This paper examines three paradigms for building robotic systems: end-to-end vision-language-action (VLA) models that implicitly integrate perception and planning, and modular pipelines incorporating either vision-language models (VLMs) or multimodal large language models (LLMs). We evaluate these paradigms through two focused case studies: a complex instruction grounding task assessing fine-grained instruction understanding and cross-modal disambiguation, and an object manipulation task targeting skill transfer via VLA finetuning. Our experiments in zero-shot and few-shot settings reveal trade-offs in generalization and data efficiency. By exploring performance limits, we distill design implications for developing language-driven physical agents and outline emerging challenges and opportunities for FM-powered robotics in real-world conditions.
LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving Environments
Aug 28, 2024



The rapid obsolescence of information in Large Language Models (LLMs) has driven the development of various techniques to incorporate new facts. However, existing methods for knowledge editing still face difficulties with multi-hop questions that require accurate fact identification and sequential logical reasoning, particularly among numerous fact updates. To tackle these challenges, this paper introduces Graph Memory-based Editing for Large Language Models (GMeLLo), a straitforward and effective method that merges the explicit knowledge representation of Knowledge Graphs (KGs) with the linguistic flexibility of LLMs. Beyond merely leveraging LLMs for question answering, GMeLLo employs these models to convert free-form language into structured queries and fact triples, facilitating seamless interaction with KGs for rapid updates and precise multi-hop reasoning. Our results show that GMeLLo significantly surpasses current state-of-the-art knowledge editing methods in the multi-hop question answering benchmark, MQuAKE, especially in scenarios with extensive knowledge edits.
A Probabilistic-Logic based Commonsense Representation Framework for Modelling Inferences with Multiple Antecedents and Varying Likelihoods
Dec 15, 2022



Commonsense knowledge-graphs (CKGs) are important resources towards building machines that can 'reason' on text or environmental inputs and make inferences beyond perception. While current CKGs encode world knowledge for a large number of concepts and have been effectively utilized for incorporating commonsense in neural models, they primarily encode declarative or single-condition inferential knowledge and assume all conceptual beliefs to have the same likelihood. Further, these CKGs utilize a limited set of relations shared across concepts and lack a coherent knowledge organization structure resulting in redundancies as well as sparsity across the larger knowledge graph. Consequently, today's CKGs, while useful for a first level of reasoning, do not adequately capture deeper human-level commonsense inferences which can be more nuanced and influenced by multiple contextual or situational factors. Accordingly, in this work, we study how commonsense knowledge can be better represented by -- (i) utilizing a probabilistic logic representation scheme to model composite inferential knowledge and represent conceptual beliefs with varying likelihoods and (ii) incorporating a hierarchical conceptual ontology to identify salient concept-relevant relations and organize beliefs at different conceptual levels. Our resulting knowledge representation framework can encode a wider variety of world knowledge and represent beliefs flexibly using grounded concepts as well as free-text phrases. As a result, the framework can be utilized as both a traditional free-text knowledge graph and a grounded logic-based inference system more suitable for neuro-symbolic applications. We describe how we extend the PrimeNet knowledge base with our framework through crowd-sourcing and expert-annotation, and demonstrate its application for more interpretable passage-based semantic parsing and question answering.
Improving Object Permanence using Agent Actions and Reasoning
Oct 01, 2021

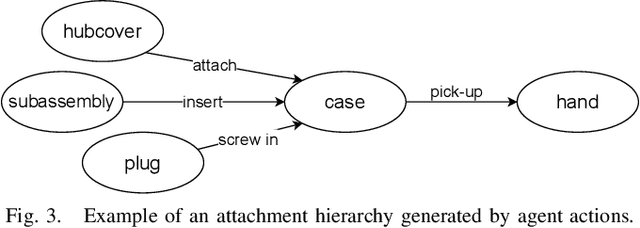
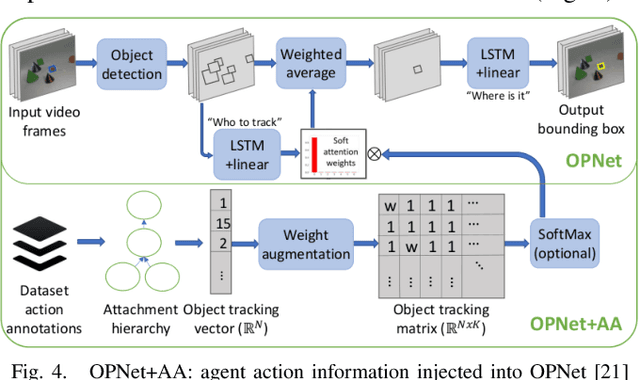
Object permanence in psychology means knowing that objects still exist even if they are no longer visible. It is a crucial concept for robots to operate autonomously in uncontrolled environments. Existing approaches learn object permanence from low-level perception, but perform poorly on more complex scenarios, like when objects are contained and carried by others. Knowledge about manipulation actions performed on an object prior to its disappearance allows us to reason about its location, e.g., that the object has been placed in a carrier. In this paper we argue that object permanence can be improved when the robot uses knowledge about executed actions and describe an approach to infer hidden object states from agent actions. We show that considering agent actions not only improves rule-based reasoning models but also purely neural approaches, showing its general applicability. Then, we conduct quantitative experiments on a snitch localization task using a dataset of 1,371 synthesized videos, where we compare the performance of different object permanence models with and without action annotations. We demonstrate that models with action annotations can significantly increase performance of both neural and rule-based approaches. Finally, we evaluate the usability of our approach in real-world applications by conducting qualitative experiments with two Universal Robots (UR5 and UR16e) in both lab and industrial settings. The robots complete benchmark tasks for a gearbox assembly and demonstrate the object permanence capabilities with real sensor data in an industrial environment.
Maintaining a Reliable World Model using Action-aware Perceptual Anchoring
Jul 07, 2021

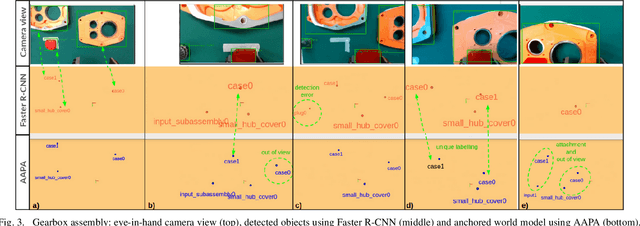
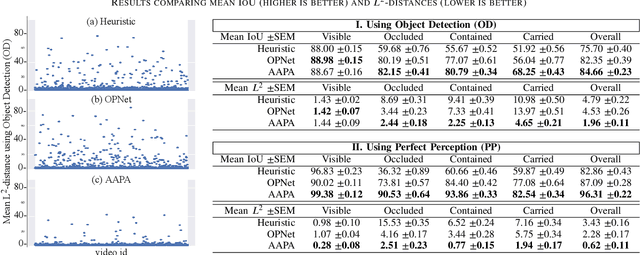
Reliable perception is essential for robots that interact with the world. But sensors alone are often insufficient to provide this capability, and they are prone to errors due to various conditions in the environment. Furthermore, there is a need for robots to maintain a model of its surroundings even when objects go out of view and are no longer visible. This requires anchoring perceptual information onto symbols that represent the objects in the environment. In this paper, we present a model for action-aware perceptual anchoring that enables robots to track objects in a persistent manner. Our rule-based approach considers inductive biases to perform high-level reasoning over the results from low-level object detection, and it improves the robot's perceptual capability for complex tasks. We evaluate our model against existing baseline models for object permanence and show that it outperforms these on a snitch localisation task using a dataset of 1,371 videos. We also integrate our action-aware perceptual anchoring in the context of a cognitive architecture and demonstrate its benefits in a realistic gearbox assembly task on a Universal Robot.
* 7 pages, 3 figures
Direct Visual-Inertial Odometry with Semi-Dense Mapping
Oct 04, 2019



The paper presents a direct visual-inertial odometry system. In particular, a tightly coupled nonlinear optimization based method is proposed by integrating the recent advances in direct dense tracking and Inertial Measurement Unit (IMU) pre-integration, and a factor graph optimization is adapted to estimate the pose of the camera and rebuild a semi-dense map. Two sliding windows are maintained in the proposed approach. The first one, based on Direct Sparse Odometry (DSO), is to estimate the depths of candidate points for mapping and dense visual tracking. In the second one, measurements from the IMU pre-integration and dense visual tracking are fused probabilistically using a tightly-coupled, optimization-based sensor fusion framework. As a result, the IMU pre-integration provides additional constraints to suppress the scale drift induced by the visual odometry. Evaluations on real-world benchmark datasets show that the proposed method achieves competitive results in indoor scenes.