 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Diffusion Models Are Inherently Skipped-Step Samplers
Aug 21, 2025



Diffusion models have been achieving state-of-the-art results across various generation tasks. However, a notable drawback is their sequential generation process, requiring long-sequence step-by-step generation. Existing methods, such as DDIM, attempt to reduce sampling steps by constructing a class of non-Markovian diffusion processes that maintain the same training objective. However, there remains a gap in understanding whether the original diffusion process can achieve the same efficiency without resorting to non-Markovian processes. In this paper, we provide a confirmative answer and introduce skipped-step sampling, a mechanism that bypasses multiple intermediate denoising steps in the iterative generation process, in contrast with the traditional step-by-step refinement of standard diffusion inference. Crucially, we demonstrate that this skipped-step sampling mechanism is derived from the same training objective as the standard diffusion model, indicating that accelerated sampling via skipped-step sampling via a Markovian way is an intrinsic property of pretrained diffusion models. Additionally, we propose an enhanced generation method by integrating our accelerated sampling technique with DDIM. Extensive experiments on popular pretrained diffusion models, including the OpenAI ADM, Stable Diffusion, and Open Sora models, show that our method achieves high-quality generation with significantly reduced sampling steps.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Depth-Wise Convolutions in Vision Transformers for Efficient Training on Small Datasets
Jul 28, 2024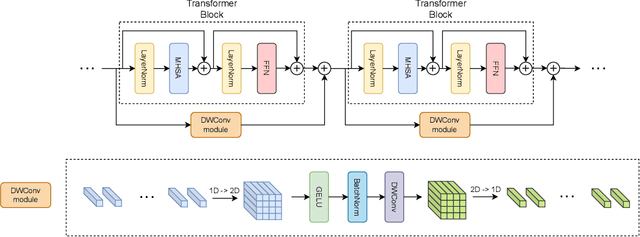
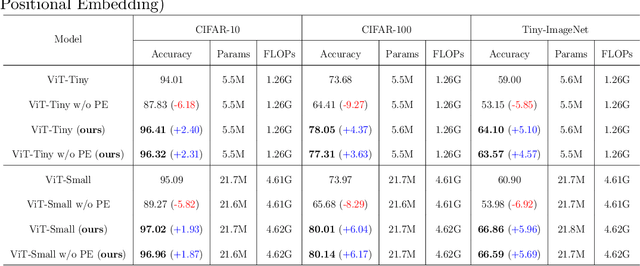
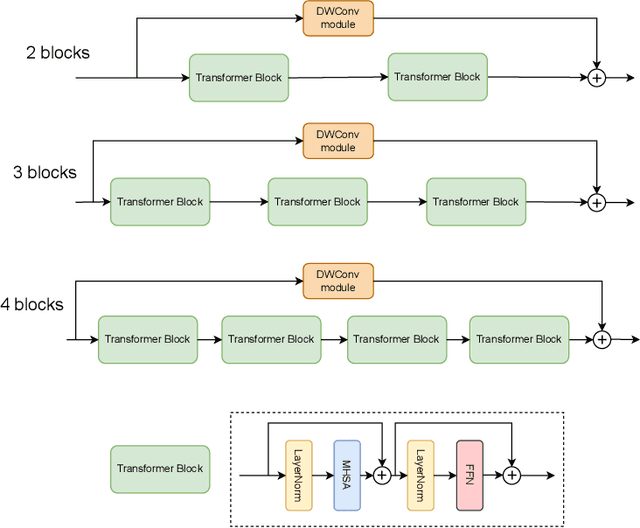
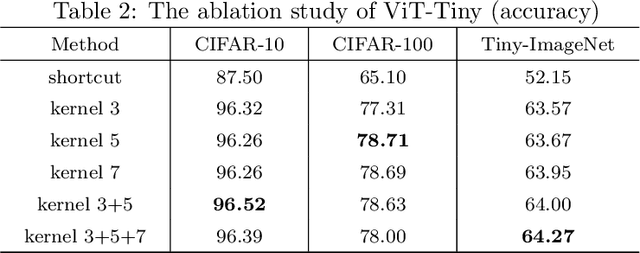
The Vision Transformer (ViT) leverages the Transformer's encoder to capture global information by dividing images into patches and achieves superior performance across various computer vision tasks. However, the self-attention mechanism of ViT captures the global context from the outset, overlooking the inherent relationships between neighboring pixels in images or videos. Transformers mainly focus on global information while ignoring the fine-grained local details. Consequently, ViT lacks inductive bias during image or video dataset training. In contrast, convolutional neural networks (CNNs), with their reliance on local filters, possess an inherent inductive bias, making them more efficient and quicker to converge than ViT with less data. In this paper, we present a lightweight Depth-Wise Convolution module as a shortcut in ViT models, bypassing entire Transformer blocks to ensure the models capture both local and global information with minimal overhead. Additionally, we introduce two architecture variants, allowing the Depth-Wise Convolution modules to be applied to multiple Transformer blocks for parameter savings, and incorporating independent parallel Depth-Wise Convolution modules with different kernels to enhance the acquisition of local information. The proposed approach significantly boosts the performance of ViT models on image classification, object detection and instance segmentation by a large margin, especially on small datasets, as evaluated on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet for image classification, and COCO for object detection and instance segmentation. The source code can be accessed at https://github.com/ZTX-100/Efficient_ViT_with_DW.
Disentangled Representation Learning for Controllable Person Image Generation
Dec 10, 2023In this paper, we propose a novel framework named DRL-CPG to learn disentangled latent representation for controllable person image generation, which can produce realistic person images with desired poses and human attributes (e.g., pose, head, upper clothes, and pants) provided by various source persons. Unlike the existing works leveraging the semantic masks to obtain the representation of each component, we propose to generate disentangled latent code via a novel attribute encoder with transformers trained in a manner of curriculum learning from a relatively easy step to a gradually hard one. A random component mask-agnostic strategy is introduced to randomly remove component masks from the person segmentation masks, which aims at increasing the difficulty of training and promoting the transformer encoder to recognize the underlying boundaries between each component. This enables the model to transfer both the shape and texture of the components. Furthermore, we propose a novel attribute decoder network to integrate multi-level attributes (e.g., the structure feature and the attribute representation) with well-designed Dual Adaptive Denormalization (DAD) residual blocks. Extensive experiments strongly demonstrate that the proposed approach is able to transfer both the texture and shape of different human parts and yield realistic results. To our knowledge, we are the first to learn disentangled latent representations with transformers for person image generation.
Learning Dynamic Style Kernels for Artistic Style Transfer
Apr 14, 2023



Arbitrary style transfer has been demonstrated to be efficient in artistic image generation. Previous methods either globally modulate the content feature ignoring local details, or overly focus on the local structure details leading to style leakage. In contrast to the literature, we propose a new scheme \textit{``style kernel"} that learns {\em spatially adaptive kernels} for per-pixel stylization, where the convolutional kernels are dynamically generated from the global style-content aligned feature and then the learned kernels are applied to modulate the content feature at each spatial position. This new scheme allows flexible both global and local interactions between the content and style features such that the wanted styles can be easily transferred to the content image while at the same time the content structure can be easily preserved. To further enhance the flexibility of our style transfer method, we propose a Style Alignment Encoding (SAE) module complemented with a Content-based Gating Modulation (CGM) module for learning the dynamic style kernels in focusing regions. Extensive experiments strongly demonstrate that our proposed method outperforms state-of-the-art methods and exhibits superior performance in terms of visual quality and efficiency.
Feature Representation Learning with Adaptive Displacement Generation and Transformer Fusion for Micro-Expression Recognition
Apr 10, 2023



Micro-expressions are spontaneous, rapid and subtle facial movements that can neither be forged nor suppressed. They are very important nonverbal communication clues, but are transient and of low intensity thus difficult to recognize. Recently deep learning based methods have been developed for micro-expression (ME) recognition using feature extraction and fusion techniques, however, targeted feature learning and efficient feature fusion still lack further study according to the ME characteristics. To address these issues, we propose a novel framework Feature Representation Learning with adaptive Displacement Generation and Transformer fusion (FRL-DGT), in which a convolutional Displacement Generation Module (DGM) with self-supervised learning is used to extract dynamic features from onset/apex frames targeted to the subsequent ME recognition task, and a well-designed Transformer Fusion mechanism composed of three Transformer-based fusion modules (local, global fusions based on AU regions and full-face fusion) is applied to extract the multi-level informative features after DGM for the final ME prediction. The extensive experiments with solid leave-one-subject-out (LOSO) evaluation results have demonstrated the superiority of our proposed FRL-DGT to state-of-the-art methods.
Explicitly Increasing Input Information Density for Vision Transformers on Small Datasets
Oct 25, 2022Vision Transformers have attracted a lot of attention recently since the successful implementation of Vision Transformer (ViT) on vision tasks. With vision Transformers, specifically the multi-head self-attention modules, networks can capture long-term dependencies inherently. However, these attention modules normally need to be trained on large datasets, and vision Transformers show inferior performance on small datasets when training from scratch compared with widely dominant backbones like ResNets. Note that the Transformer model was first proposed for natural language processing, which carries denser information than natural images. To boost the performance of vision Transformers on small datasets, this paper proposes to explicitly increase the input information density in the frequency domain. Specifically, we introduce selecting channels by calculating the channel-wise heatmaps in the frequency domain using Discrete Cosine Transform (DCT), reducing the size of input while keeping most information and hence increasing the information density. As a result, 25% fewer channels are kept while better performance is achieved compared with previous work. Extensive experiments demonstrate the effectiveness of the proposed approach on five small-scale datasets, including CIFAR-10/100, SVHN, Flowers-102, and Tiny ImageNet. The accuracy has been boosted up to 17.05% with Swin and Focal Transformers. Codes are available at https://github.com/xiangyu8/DenseVT.
Dual-Flattening Transformers through Decomposed Row and Column Queries for Semantic Segmentation
Jan 22, 2022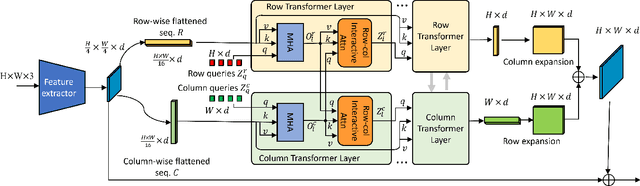

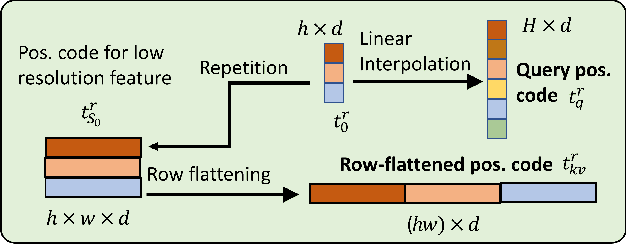
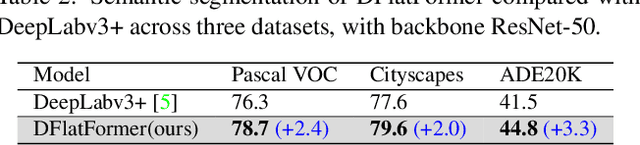
It is critical to obtain high resolution features with long range dependency for dense prediction tasks such as semantic segmentation. To generate high-resolution output of size $H\times W$ from a low-resolution feature map of size $h\times w$ ($hw\ll HW$), a naive dense transformer incurs an intractable complexity of $\mathcal{O}(hwHW)$, limiting its application on high-resolution dense prediction. We propose a Dual-Flattening Transformer (DFlatFormer) to enable high-resolution output by reducing complexity to $\mathcal{O}(hw(H+W))$ that is multiple orders of magnitude smaller than the naive dense transformer. Decomposed queries are presented to retrieve row and column attentions tractably through separate transformers, and their outputs are combined to form a dense feature map at high resolution. To this end, the input sequence fed from an encoder is row-wise and column-wise flattened to align with decomposed queries by preserving their row and column structures, respectively. Row and column transformers also interact with each other to capture their mutual attentions with the spatial crossings between rows and columns. We also propose to perform attentions through efficient grouping and pooling to further reduce the model complexity. Extensive experiments on ADE20K and Cityscapes datasets demonstrate the superiority of the proposed dual-flattening transformer architecture with higher mIoUs.
A Domain Gap Aware Generative Adversarial Network for Multi-domain Image Translation
Oct 21, 2021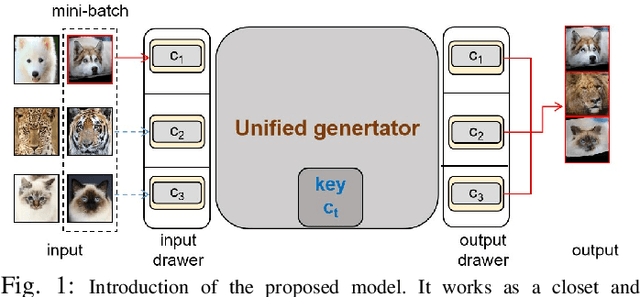



Recent image-to-image translation models have shown great success in mapping local textures between two domains. Existing approaches rely on a cycle-consistency constraint that supervises the generators to learn an inverse mapping. However, learning the inverse mapping introduces extra trainable parameters and it is unable to learn the inverse mapping for some domains. As a result, they are ineffective in the scenarios where (i) multiple visual image domains are involved; (ii) both structure and texture transformations are required; and (iii) semantic consistency is preserved. To solve these challenges, the paper proposes a unified model to translate images across multiple domains with significant domain gaps. Unlike previous models that constrain the generators with the ubiquitous cycle-consistency constraint to achieve the content similarity, the proposed model employs a perceptual self-regularization constraint. With a single unified generator, the model can maintain consistency over the global shapes as well as the local texture information across multiple domains. Extensive qualitative and quantitative evaluations demonstrate the effectiveness and superior performance over state-of-the-art models. It is more effective in representing shape deformation in challenging mappings with significant dataset variation across multiple domains.