 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Flattening Transformers through Decomposed Row and Column Queries for Semantic Segmentation
Paper and Code
Jan 22, 2022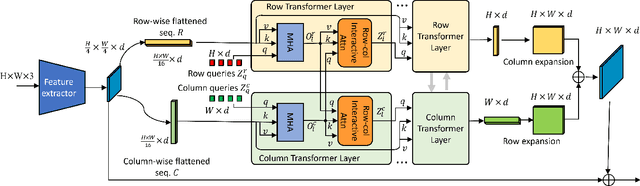

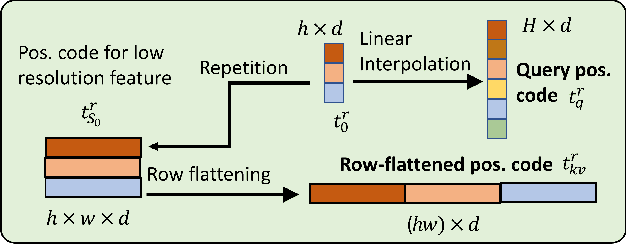
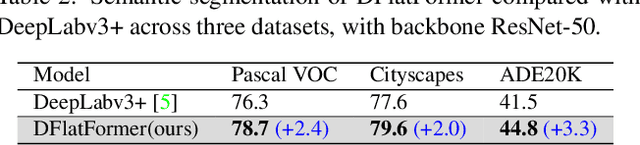
It is critical to obtain high resolution features with long range dependency for dense prediction tasks such as semantic segmentation. To generate high-resolution output of size $H\times W$ from a low-resolution feature map of size $h\times w$ ($hw\ll HW$), a naive dense transformer incurs an intractable complexity of $\mathcal{O}(hwHW)$, limiting its application on high-resolution dense prediction. We propose a Dual-Flattening Transformer (DFlatFormer) to enable high-resolution output by reducing complexity to $\mathcal{O}(hw(H+W))$ that is multiple orders of magnitude smaller than the naive dense transformer. Decomposed queries are presented to retrieve row and column attentions tractably through separate transformers, and their outputs are combined to form a dense feature map at high resolution. To this end, the input sequence fed from an encoder is row-wise and column-wise flattened to align with decomposed queries by preserving their row and column structures, respectively. Row and column transformers also interact with each other to capture their mutual attentions with the spatial crossings between rows and columns. We also propose to perform attentions through efficient grouping and pooling to further reduce the model complexity. Extensive experiments on ADE20K and Cityscapes datasets demonstrate the superiority of the proposed dual-flattening transformer architecture with higher mIoUs.