 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Efficient Tool Orchestration via Layered Execution Structures with Reflective Correction
Feb 21, 2026Tool invocation is a core capability of agentic systems, yet failures often arise not from individual tool calls but from how multiple tools are organized and executed together. Existing approaches tightly couple tool execution with stepwise language reasoning or explicit planning, leading to brittle behavior and high execution overhead. To overcome these limitations, we revisit tool invocation from the perspective of tool orchestration. Our key insight is that effective orchestration does not require precise dependency graphs or fine-grained planning. Instead, a coarse-grained layer structure suffices to provide global guidance, while execution-time errors can be corrected locally. Specifically, we model tool orchestration as learning a layered execution structure that captures high-level tool dependencies, inducing layer-wise execution through context constraints. To handle execution-time failures, we introduce a schema-aware reflective correction mechanism that detects and repairs errors locally. This design confines errors to individual tool calls and avoids re-planning entire execution trajectories. This structured execution paradigm enables a lightweight and reusable orchestration component for agentic systems. Experimental results show that our approach achieves robust tool execution while reducing execution complexity and overhead. Code will be made publicly available.
Improving Vision Transformers by Overlapping Heads in Multi-Head Self-Attention
Oct 18, 2024



Vision Transformers have made remarkable progress in recent years, achieving state-of-the-art performance in most vision tasks. A key component of this success is due to the introduction of the Multi-Head Self-Attention (MHSA) module, which enables each head to learn different representations by applying the attention mechanism independently. In this paper, we empirically demonstrate that Vision Transformers can be further enhanced by overlapping the heads in MHSA. We introduce Multi-Overlapped-Head Self-Attention (MOHSA), where heads are overlapped with their two adjacent heads for queries, keys, and values, while zero-padding is employed for the first and last heads, which have only one neighboring head. Various paradigms for overlapping ratios are proposed to fully investigate the optimal performance of our approach. The proposed approach is evaluated using five Transformer models on four benchmark datasets and yields a significant performance boost. The source code will be made publicly available upon publication.
Depth-Wise Convolutions in Vision Transformers for Efficient Training on Small Datasets
Jul 28, 2024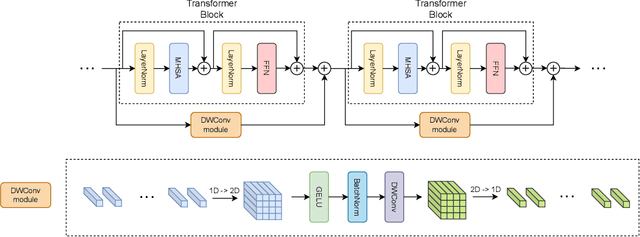
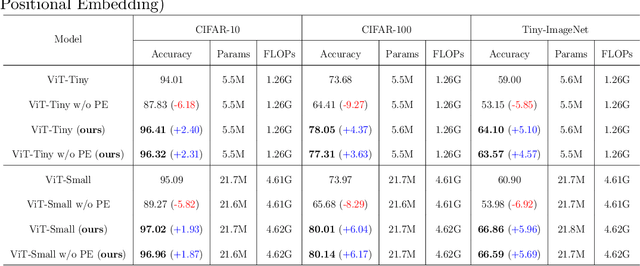
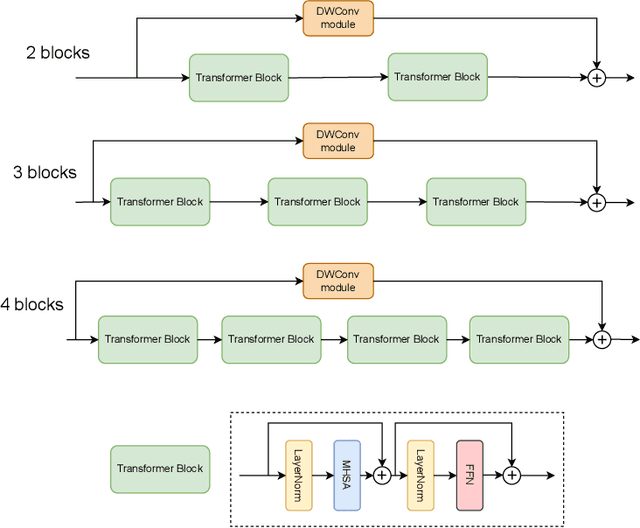
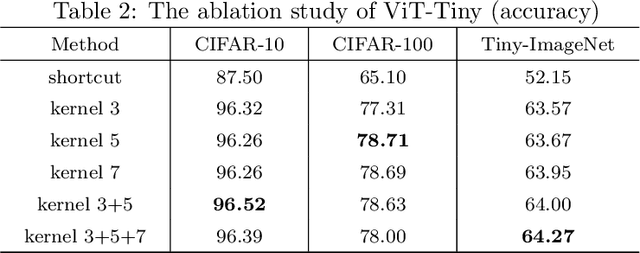
The Vision Transformer (ViT) leverages the Transformer's encoder to capture global information by dividing images into patches and achieves superior performance across various computer vision tasks. However, the self-attention mechanism of ViT captures the global context from the outset, overlooking the inherent relationships between neighboring pixels in images or videos. Transformers mainly focus on global information while ignoring the fine-grained local details. Consequently, ViT lacks inductive bias during image or video dataset training. In contrast, convolutional neural networks (CNNs), with their reliance on local filters, possess an inherent inductive bias, making them more efficient and quicker to converge than ViT with less data. In this paper, we present a lightweight Depth-Wise Convolution module as a shortcut in ViT models, bypassing entire Transformer blocks to ensure the models capture both local and global information with minimal overhead. Additionally, we introduce two architecture variants, allowing the Depth-Wise Convolution modules to be applied to multiple Transformer blocks for parameter savings, and incorporating independent parallel Depth-Wise Convolution modules with different kernels to enhance the acquisition of local information. The proposed approach significantly boosts the performance of ViT models on image classification, object detection and instance segmentation by a large margin, especially on small datasets, as evaluated on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet for image classification, and COCO for object detection and instance segmentation. The source code can be accessed at https://github.com/ZTX-100/Efficient_ViT_with_DW.
The Adversarial AI-Art: Understanding, Generation, Detection, and Benchmarking
Apr 22, 2024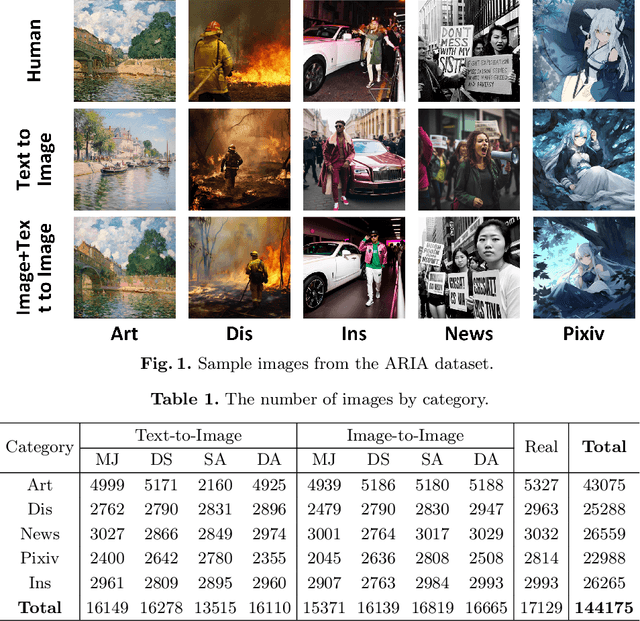
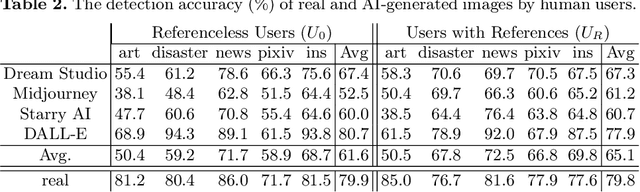
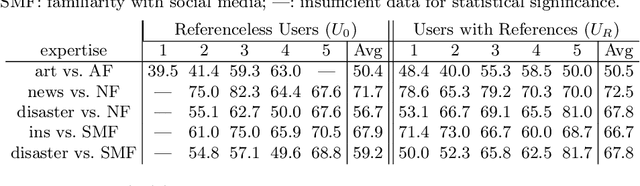
Generative AI models can produce high-quality images based on text prompts. The generated images often appear indistinguishable from images generated by conventional optical photography devices or created by human artists (i.e., real images). While the outstanding performance of such generative models is generally well received, security concerns arise. For instance, such image generators could be used to facilitate fraud or scam schemes, generate and spread misinformation, or produce fabricated artworks. In this paper, we present a systematic attempt at understanding and detecting AI-generated images (AI-art) in adversarial scenarios. First, we collect and share a dataset of real images and their corresponding artificial counterparts generated by four popular AI image generators. The dataset, named ARIA, contains over 140K images in five categories: artworks (painting), social media images, news photos, disaster scenes, and anime pictures. This dataset can be used as a foundation to support future research on adversarial AI-art. Next, we present a user study that employs the ARIA dataset to evaluate if real-world users can distinguish with or without reference images. In a benchmarking study, we further evaluate if state-of-the-art open-source and commercial AI image detectors can effectively identify the images in the ARIA dataset. Finally, we present a ResNet-50 classifier and evaluate its accuracy and transferability on the ARIA dataset.
Counterfactual Prediction Under Selective Confounding
Oct 21, 2023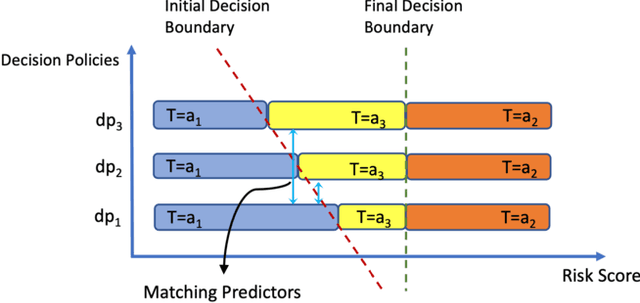
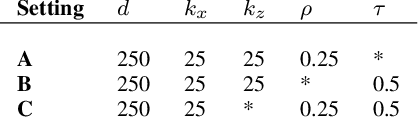

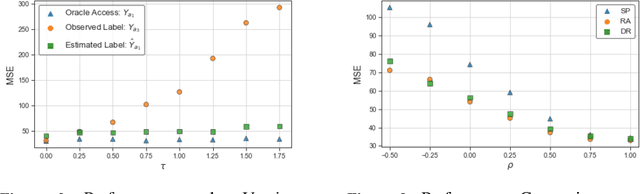
This research addresses the challenge of conducting interpretable causal inference between a binary treatment and its resulting outcome when not all confounders are known. Confounders are factors that have an influence on both the treatment and the outcome. We relax the requirement of knowing all confounders under desired treatment, which we refer to as Selective Confounding, to enable causal inference in diverse real-world scenarios. Our proposed scheme is designed to work in situations where multiple decision-makers with different policies are involved and where there is a re-evaluation mechanism after the initial decision to ensure consistency. These assumptions are more practical to fulfill compared to the availability of all confounders under all treatments. To tackle the issue of Selective Confounding, we propose the use of dual-treatment samples. These samples allow us to employ two-step procedures, such as Regression Adjustment or Doubly-Robust, to learn counterfactual predictors. We provide both theoretical error bounds and empirical evidence of the effectiveness of our proposed scheme using synthetic and real-world child placement data. Furthermore, we introduce three evaluation methods specifically tailored to assess the performance in child placement scenarios. By emphasizing transparency and interpretability, our approach aims to provide decision-makers with a valuable tool. The source code repository of this work is located at https://github.com/sohaib730/CausalML.
Aphid Cluster Recognition and Detection in the Wild Using Deep Learning Models
Aug 10, 2023Aphid infestation poses a significant threat to crop production, rural communities, and global food security. While chemical pest control is crucial for maximizing yields, applying chemicals across entire fields is both environmentally unsustainable and costly. Hence, precise localization and management of aphids are essential for targeted pesticide application. The paper primarily focuses on using deep learning models for detecting aphid clusters. We propose a novel approach for estimating infection levels by detecting aphid clusters. To facilitate this research, we have captured a large-scale dataset from sorghum fields, manually selected 5,447 images containing aphids, and annotated each individual aphid cluster within these images. To facilitate the use of machine learning models, we further process the images by cropping them into patches, resulting in a labeled dataset comprising 151,380 image patches. Then, we implemented and compared the performance of four state-of-the-art object detection models (VFNet, GFLV2, PAA, and ATSS) on the aphid dataset. Extensive experimental results show that all models yield stable similar performance in terms of average precision and recall. We then propose to merge close neighboring clusters and remove tiny clusters caused by cropping, and the performance is further boosted by around 17%. The study demonstrates the feasibility of automatically detecting and managing insects using machine learning models. The labeled dataset will be made openly available to the research community.
A New Dataset and Comparative Study for Aphid Cluster Detection
Jul 12, 2023

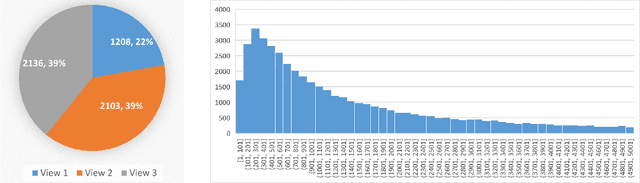
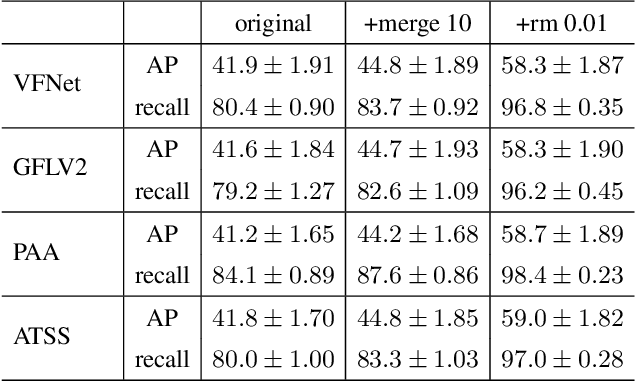
Aphids are one of the main threats to crops, rural families, and global food security. Chemical pest control is a necessary component of crop production for maximizing yields, however, it is unnecessary to apply the chemical approaches to the entire fields in consideration of the environmental pollution and the cost. Thus, accurately localizing the aphid and estimating the infestation level is crucial to the precise local application of pesticides. Aphid detection is very challenging as each individual aphid is really small and all aphids are crowded together as clusters. In this paper, we propose to estimate the infection level by detecting aphid clusters. We have taken millions of images in the sorghum fields, manually selected 5,447 images that contain aphids, and annotated each aphid cluster in the image. To use these images for machine learning models, we crop the images into patches and created a labeled dataset with over 151,000 image patches. Then, we implement and compare the performance of four state-of-the-art object detection models.
Check Me If You Can: Detecting ChatGPT-Generated Academic Writing using CheckGPT
Jun 07, 2023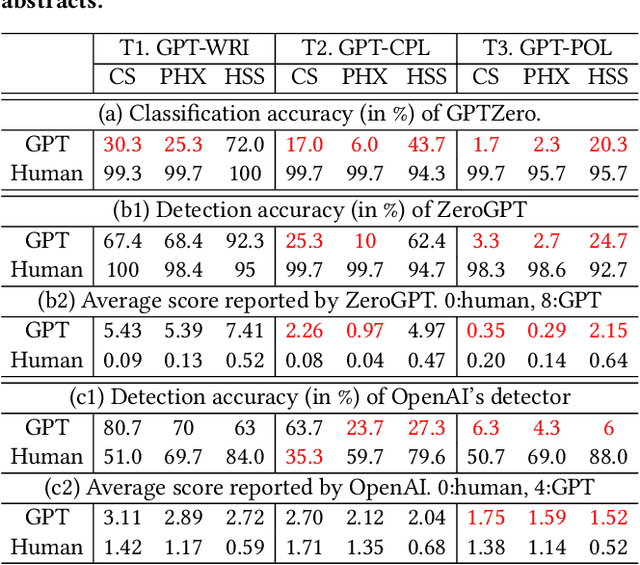

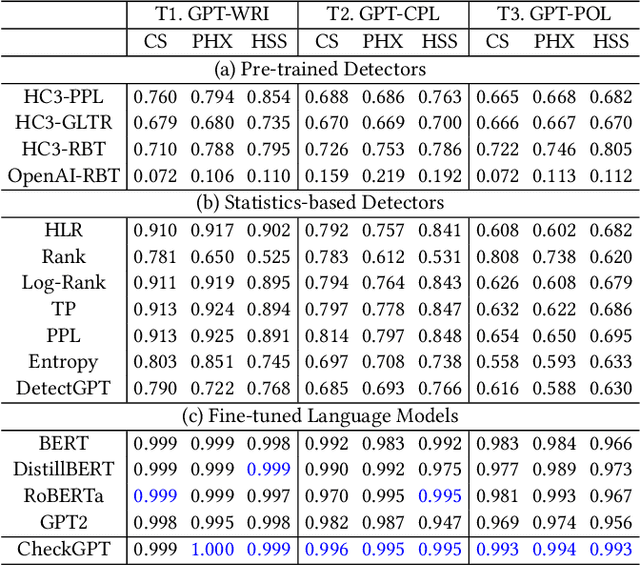
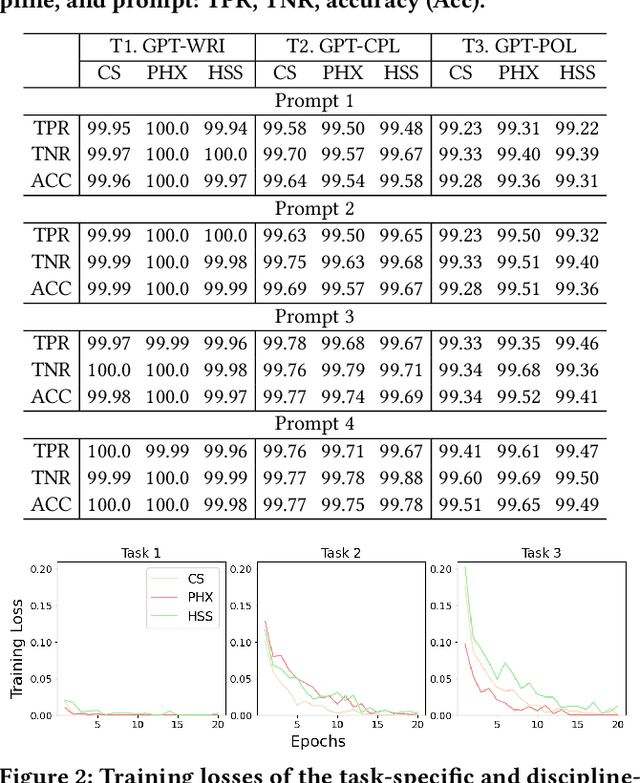
With ChatGPT under the spotlight, utilizing large language models (LLMs) for academic writing has drawn a significant amount of discussions and concerns in the community. While substantial research efforts have been stimulated for detecting LLM-Generated Content (LLM-content), most of the attempts are still in the early stage of exploration. In this paper, we present a holistic investigation of detecting LLM-generate academic writing, by providing a dataset, evidence, and algorithms, in order to inspire more community effort to address the concern of LLM academic misuse. We first present GPABenchmark, a benchmarking dataset of 600,000 samples of human-written, GPT-written, GPT-completed, and GPT-polished abstracts of research papers in CS, physics, and humanities and social sciences (HSS). We show that existing open-source and commercial GPT detectors provide unsatisfactory performance on GPABenchmark, especially for GPT-polished text. Moreover, through a user study of 150+ participants, we show that it is highly challenging for human users, including experienced faculty members and researchers, to identify GPT-generated abstracts. We then present CheckGPT, a novel LLM-content detector consisting of a general representation module and an attentive-BiLSTM classification module, which is accurate, transferable, and interpretable. Experimental results show that CheckGPT achieves an average classification accuracy of 98% to 99% for the task-specific discipline-specific detectors and the unified detectors. CheckGPT is also highly transferable that, without tuning, it achieves ~90% accuracy in new domains, such as news articles, while a model tuned with approximately 2,000 samples in the target domain achieves ~98% accuracy. Finally, we demonstrate the explainability insights obtained from CheckGPT to reveal the key behaviors of how LLM generates texts.
Gender, Smoking History and Age Prediction from Laryngeal Images
May 26, 2023
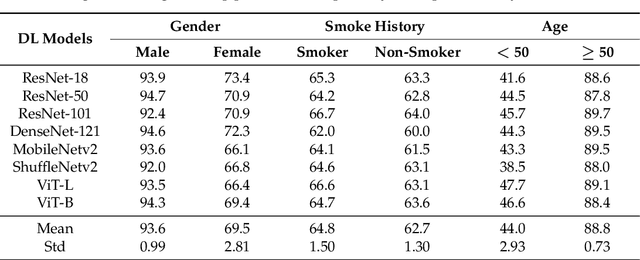
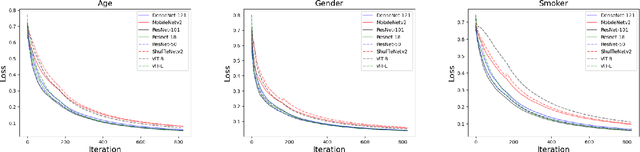
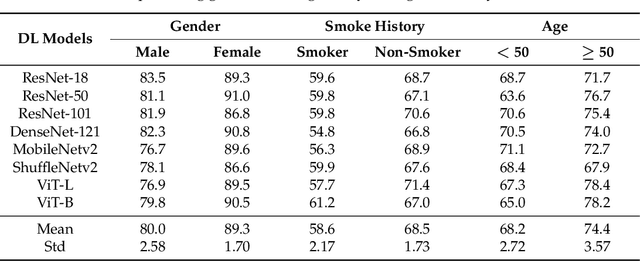
Flexible laryngoscopy is commonly performed by otolaryngologists to detect laryngeal diseases and to recognize potentially malignant lesions. Recently, researchers have introduced machine learning techniques to facilitate automated diagnosis using laryngeal images and achieved promising results. Diagnostic performance can be improved when patients' demographic information is incorporated into models. However, manual entry of patient data is time consuming for clinicians. In this study, we made the first endeavor to employ deep learning models to predict patient demographic information to improve detector model performance. The overall accuracy for gender, smoking history, and age was 85.5%, 65.2%, and 75.9%, respectively. We also created a new laryngoscopic image set for machine learning study and benchmarked the performance of 8 classical deep learning models based on CNNs and Transformers. The results can be integrated into current learning models to improve their performance by incorporating the patient's demographic information.
Hide and Seek: on the Stealthiness of Attacks against Deep Learning Systems
May 31, 2022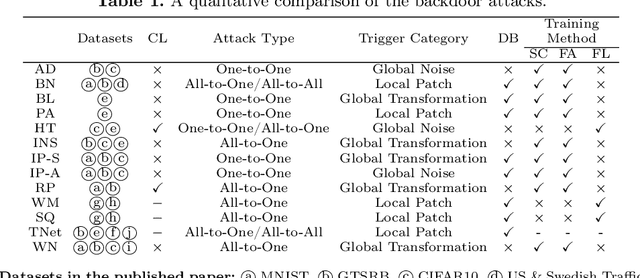

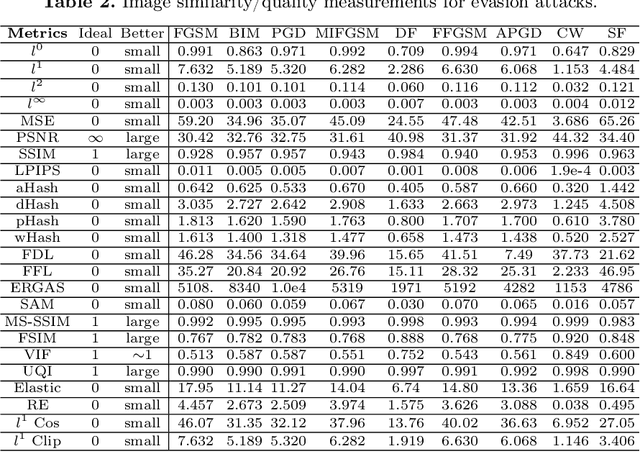
With the growing popularity of artificial intelligence and machine learning, a wide spectrum of attacks against deep learning models have been proposed in the literature. Both the evasion attacks and the poisoning attacks attempt to utilize adversarially altered samples to fool the victim model to misclassify the adversarial sample. While such attacks claim to be or are expected to be stealthy, i.e., imperceptible to human eyes, such claims are rarely evaluated. In this paper, we present the first large-scale study on the stealthiness of adversarial samples used in the attacks against deep learning. We have implemented 20 representative adversarial ML attacks on six popular benchmarking datasets. We evaluate the stealthiness of the attack samples using two complementary approaches: (1) a numerical study that adopts 24 metrics for image similarity or quality assessment; and (2) a user study of 3 sets of questionnaires that has collected 20,000+ annotations from 1,000+ responses. Our results show that the majority of the existing attacks introduce nonnegligible perturbations that are not stealthy to human eyes. We further analyze the factors that contribute to attack stealthiness. We further examine the correlation between the numerical analysis and the user studies, and demonstrate that some image quality metrics may provide useful guidance in attack designs, while there is still a significant gap between assessed image quality and visual stealthiness of attacks.