 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Adversarial AI-Art: Understanding, Generation, Detection, and Benchmarking
Apr 22, 2024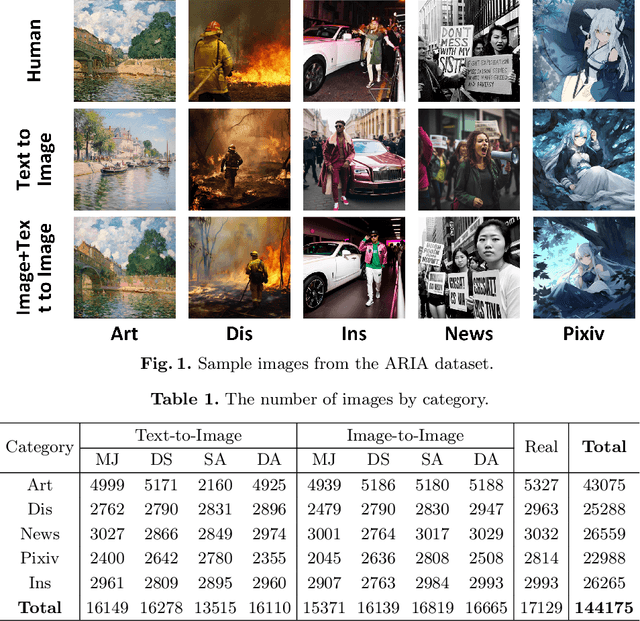
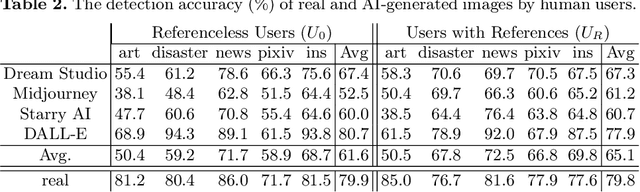
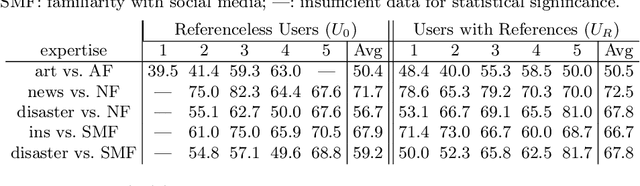
Generative AI models can produce high-quality images based on text prompts. The generated images often appear indistinguishable from images generated by conventional optical photography devices or created by human artists (i.e., real images). While the outstanding performance of such generative models is generally well received, security concerns arise. For instance, such image generators could be used to facilitate fraud or scam schemes, generate and spread misinformation, or produce fabricated artworks. In this paper, we present a systematic attempt at understanding and detecting AI-generated images (AI-art) in adversarial scenarios. First, we collect and share a dataset of real images and their corresponding artificial counterparts generated by four popular AI image generators. The dataset, named ARIA, contains over 140K images in five categories: artworks (painting), social media images, news photos, disaster scenes, and anime pictures. This dataset can be used as a foundation to support future research on adversarial AI-art. Next, we present a user study that employs the ARIA dataset to evaluate if real-world users can distinguish with or without reference images. In a benchmarking study, we further evaluate if state-of-the-art open-source and commercial AI image detectors can effectively identify the images in the ARIA dataset. Finally, we present a ResNet-50 classifier and evaluate its accuracy and transferability on the ARIA dataset.
Multi-Layer Dense Attention Decoder for Polyp Segmentation
Mar 27, 2024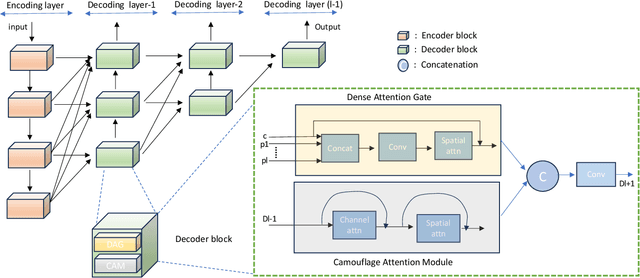
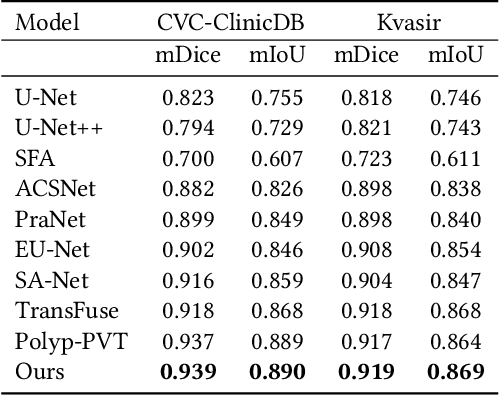
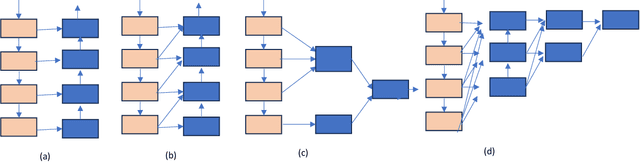
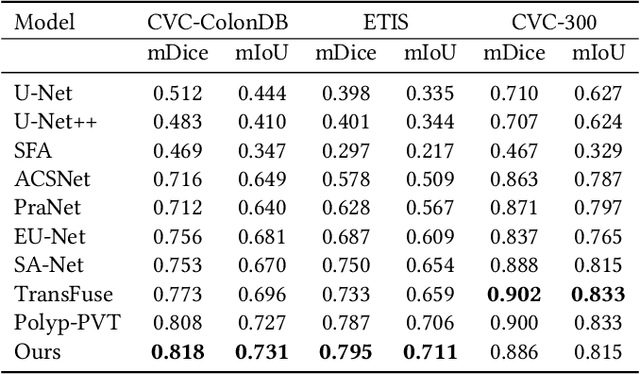
Detecting and segmenting polyps is crucial for expediting the diagnosis of colon cancer. This is a challenging task due to the large variations of polyps in color, texture, and lighting conditions, along with subtle differences between the polyp and its surrounding area. Recently, vision Transformers have shown robust abilities in modeling global context for polyp segmentation. However, they face two major limitations: the inability to learn local relations among multi-level layers and inadequate feature aggregation in the decoder. To address these issues, we propose a novel decoder architecture aimed at hierarchically aggregating locally enhanced multi-level dense features. Specifically, we introduce a novel module named Dense Attention Gate (DAG), which adaptively fuses all previous layers' features to establish local feature relations among all layers. Furthermore, we propose a novel nested decoder architecture that hierarchically aggregates decoder features, thereby enhancing semantic features. We incorporate our novel dense decoder with the PVT backbone network and conduct evaluations on five polyp segmentation datasets: Kvasir, CVC-300, CVC-ColonDB, CVC-ClinicDB, and ETIS. Our experiments and comparisons with nine competing segmentation models demonstrate that the proposed architecture achieves state-of-the-art performance and outperforms the previous models on four datasets. The source code is available at: https://github.com/krushi1992/Dense-Decoder.
Check Me If You Can: Detecting ChatGPT-Generated Academic Writing using CheckGPT
Jun 07, 2023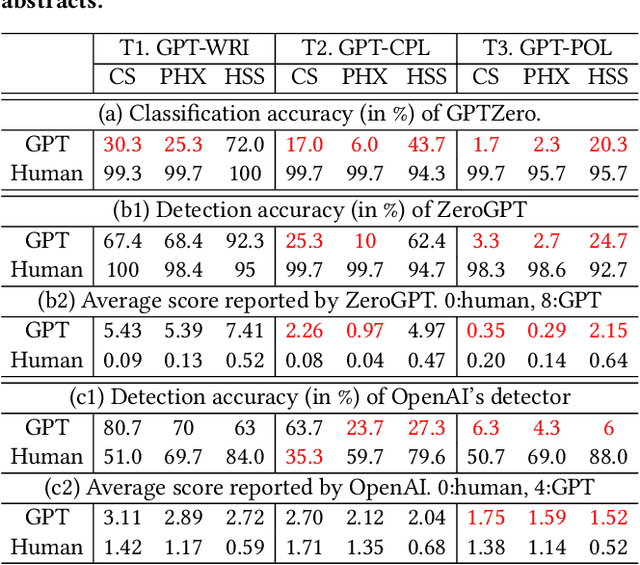

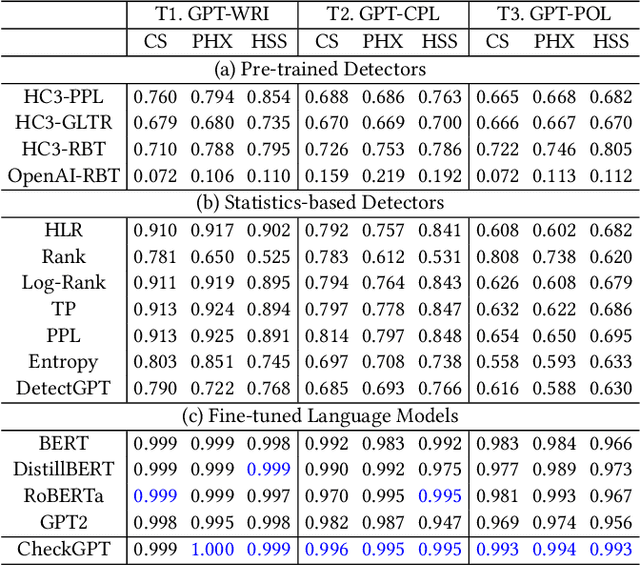
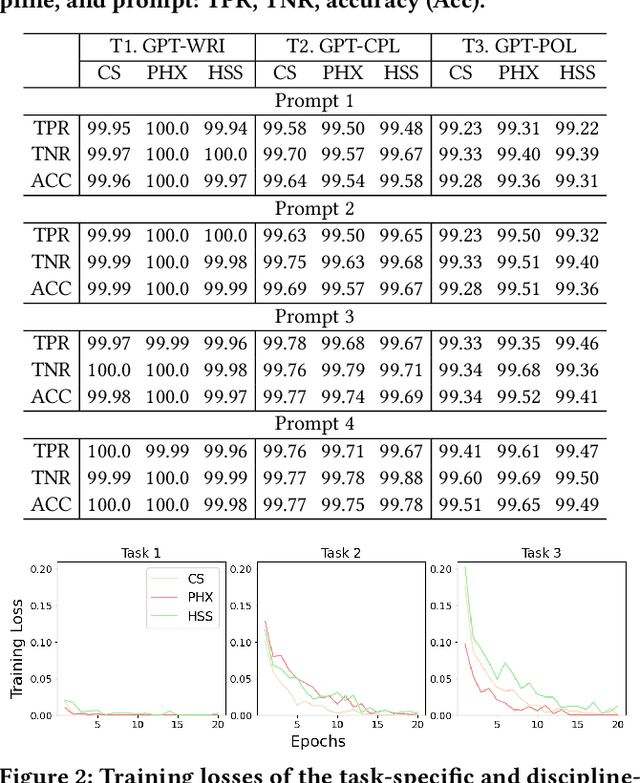
With ChatGPT under the spotlight, utilizing large language models (LLMs) for academic writing has drawn a significant amount of discussions and concerns in the community. While substantial research efforts have been stimulated for detecting LLM-Generated Content (LLM-content), most of the attempts are still in the early stage of exploration. In this paper, we present a holistic investigation of detecting LLM-generate academic writing, by providing a dataset, evidence, and algorithms, in order to inspire more community effort to address the concern of LLM academic misuse. We first present GPABenchmark, a benchmarking dataset of 600,000 samples of human-written, GPT-written, GPT-completed, and GPT-polished abstracts of research papers in CS, physics, and humanities and social sciences (HSS). We show that existing open-source and commercial GPT detectors provide unsatisfactory performance on GPABenchmark, especially for GPT-polished text. Moreover, through a user study of 150+ participants, we show that it is highly challenging for human users, including experienced faculty members and researchers, to identify GPT-generated abstracts. We then present CheckGPT, a novel LLM-content detector consisting of a general representation module and an attentive-BiLSTM classification module, which is accurate, transferable, and interpretable. Experimental results show that CheckGPT achieves an average classification accuracy of 98% to 99% for the task-specific discipline-specific detectors and the unified detectors. CheckGPT is also highly transferable that, without tuning, it achieves ~90% accuracy in new domains, such as news articles, while a model tuned with approximately 2,000 samples in the target domain achieves ~98% accuracy. Finally, we demonstrate the explainability insights obtained from CheckGPT to reveal the key behaviors of how LLM generates texts.
Learning Generalizable Latent Representations for Novel Degradations in Super Resolution
Jul 25, 2022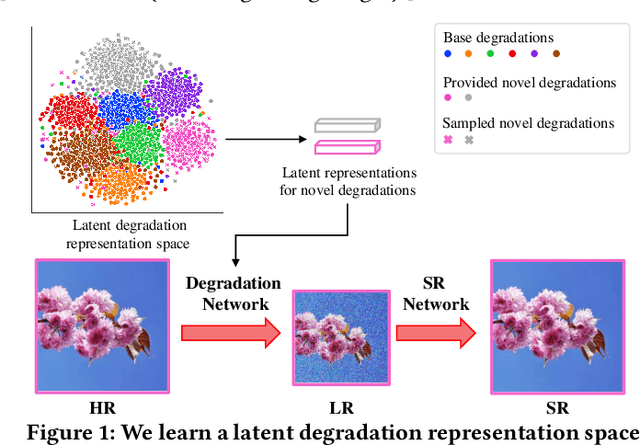

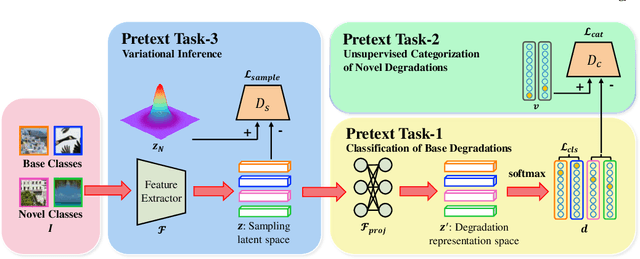
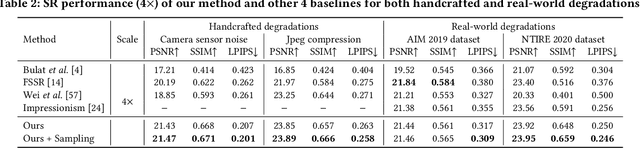
Typical methods for blind image super-resolution (SR) focus on dealing with unknown degradations by directly estimating them or learning the degradation representations in a latent space. A potential limitation of these methods is that they assume the unknown degradations can be simulated by the integration of various handcrafted degradations (e.g., bicubic downsampling), which is not necessarily true. The real-world degradations can be beyond the simulation scope by the handcrafted degradations, which are referred to as novel degradations. In this work, we propose to learn a latent representation space for degradations, which can be generalized from handcrafted (base) degradations to novel degradations. The obtained representations for a novel degradation in this latent space are then leveraged to generate degraded images consistent with the novel degradation to compose paired training data for SR model. Furthermore, we perform variational inference to match the posterior of degradations in latent representation space with a prior distribution (e.g., Gaussian distribution). Consequently, we are able to sample more high-quality representations for a novel degradation to augment the training data for SR model. We conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness and advantages of our method for blind super-resolution with novel degradations.
Hide and Seek: on the Stealthiness of Attacks against Deep Learning Systems
May 31, 2022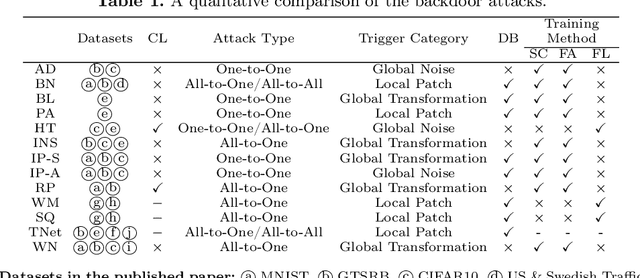

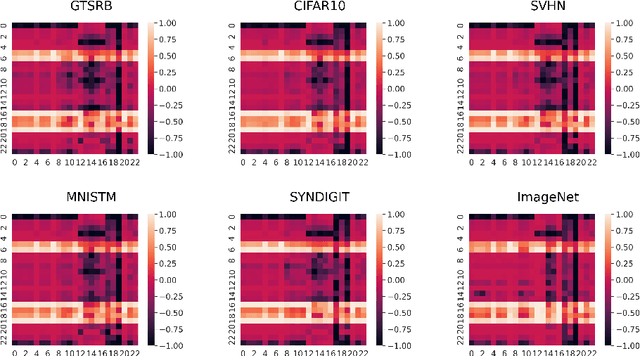
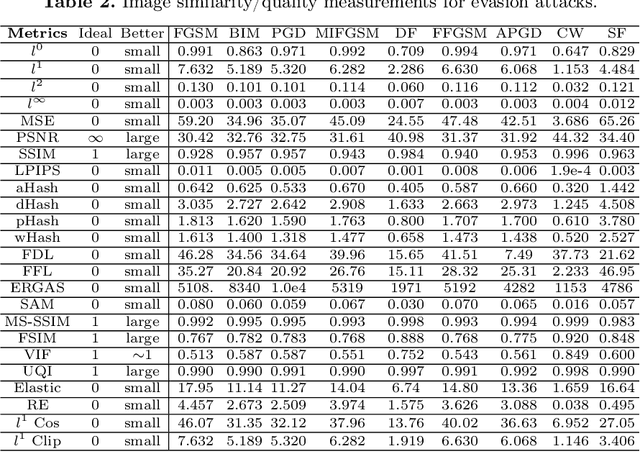
With the growing popularity of artificial intelligence and machine learning, a wide spectrum of attacks against deep learning models have been proposed in the literature. Both the evasion attacks and the poisoning attacks attempt to utilize adversarially altered samples to fool the victim model to misclassify the adversarial sample. While such attacks claim to be or are expected to be stealthy, i.e., imperceptible to human eyes, such claims are rarely evaluated. In this paper, we present the first large-scale study on the stealthiness of adversarial samples used in the attacks against deep learning. We have implemented 20 representative adversarial ML attacks on six popular benchmarking datasets. We evaluate the stealthiness of the attack samples using two complementary approaches: (1) a numerical study that adopts 24 metrics for image similarity or quality assessment; and (2) a user study of 3 sets of questionnaires that has collected 20,000+ annotations from 1,000+ responses. Our results show that the majority of the existing attacks introduce nonnegligible perturbations that are not stealthy to human eyes. We further analyze the factors that contribute to attack stealthiness. We further examine the correlation between the numerical analysis and the user studies, and demonstrate that some image quality metrics may provide useful guidance in attack designs, while there is still a significant gap between assessed image quality and visual stealthiness of attacks.
Aggregating Global Features into Local Vision Transformer
Jan 30, 2022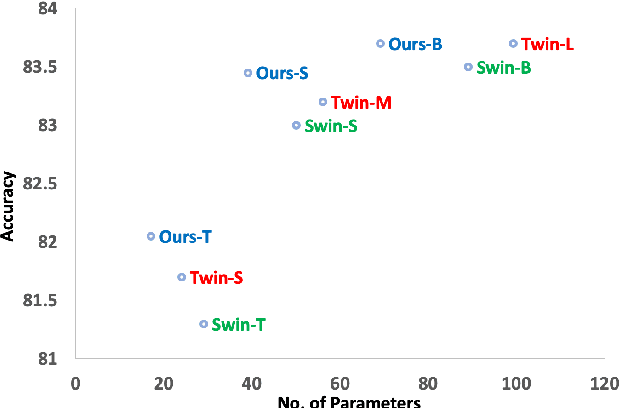
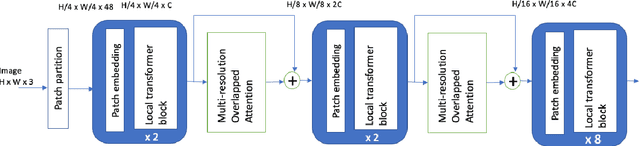
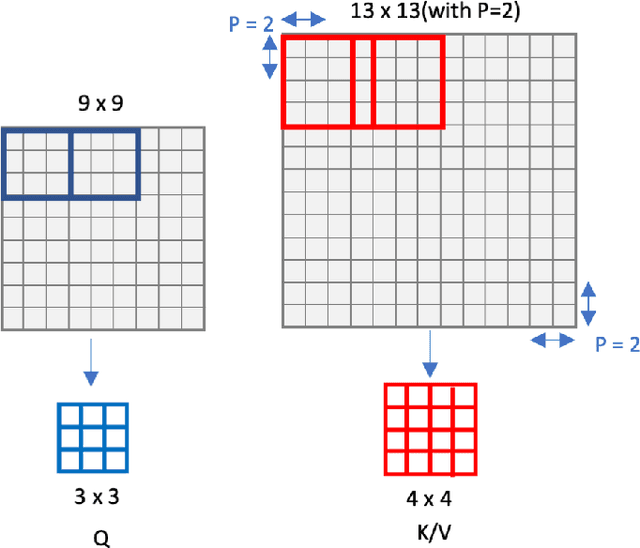

Local Transformer-based classification models have recently achieved promising results with relatively low computational costs. However, the effect of aggregating spatial global information of local Transformer-based architecture is not clear. This work investigates the outcome of applying a global attention-based module named multi-resolution overlapped attention (MOA) in the local window-based transformer after each stage. The proposed MOA employs slightly larger and overlapped patches in the key to enable neighborhood pixel information transmission, which leads to significant performance gain. In addition, we thoroughly investigate the effect of the dimension of essential architecture components through extensive experiments and discover an optimum architecture design. Extensive experimental results CIFAR-10, CIFAR-100, and ImageNet-1K datasets demonstrate that the proposed approach outperforms previous vision Transformers with a comparatively fewer number of parameters.
Two Souls in an Adversarial Image: Towards Universal Adversarial Example Detection using Multi-view Inconsistency
Oct 11, 2021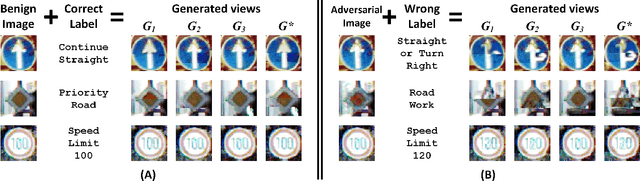
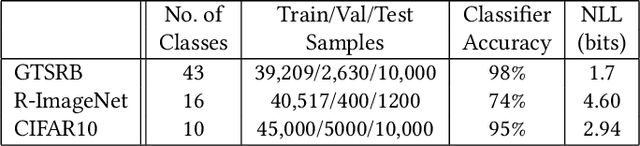
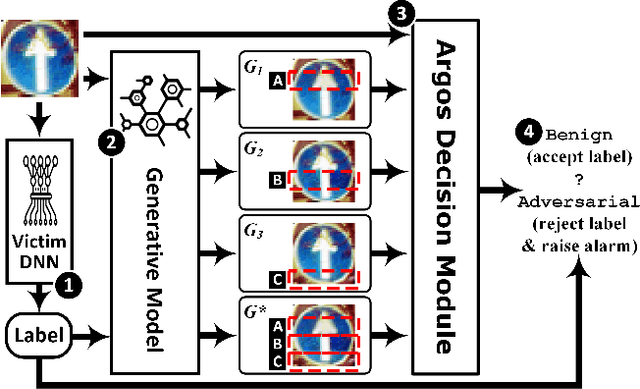
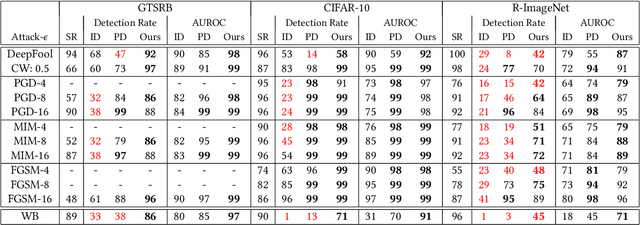
In the evasion attacks against deep neural networks (DNN), the attacker generates adversarial instances that are visually indistinguishable from benign samples and sends them to the target DNN to trigger misclassifications. In this paper, we propose a novel multi-view adversarial image detector, namely Argos, based on a novel observation. That is, there exist two "souls" in an adversarial instance, i.e., the visually unchanged content, which corresponds to the true label, and the added invisible perturbation, which corresponds to the misclassified label. Such inconsistencies could be further amplified through an autoregressive generative approach that generates images with seed pixels selected from the original image, a selected label, and pixel distributions learned from the training data. The generated images (i.e., the "views") will deviate significantly from the original one if the label is adversarial, demonstrating inconsistencies that Argos expects to detect. To this end, Argos first amplifies the discrepancies between the visual content of an image and its misclassified label induced by the attack using a set of regeneration mechanisms and then identifies an image as adversarial if the reproduced views deviate to a preset degree. Our experimental results show that Argos significantly outperforms two representative adversarial detectors in both detection accuracy and robustness against six well-known adversarial attacks. Code is available at: https://github.com/sohaib730/Argos-Adversarial_Detection
Generative Memory-Guided Semantic Reasoning Model for Image Inpainting
Oct 01, 2021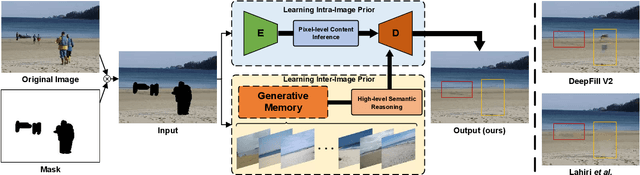

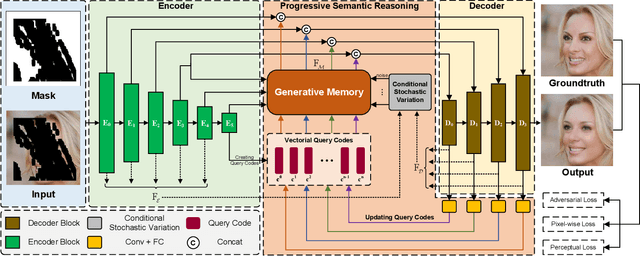
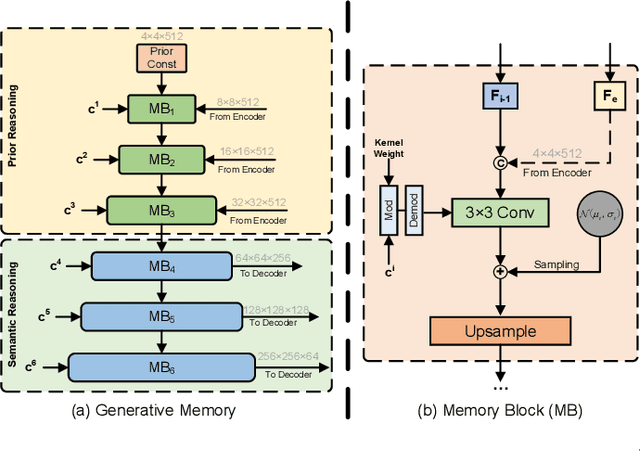
Most existing methods for image inpainting focus on learning the intra-image priors from the known regions of the current input image to infer the content of the corrupted regions in the same image. While such methods perform well on images with small corrupted regions, it is challenging for these methods to deal with images with large corrupted area due to two potential limitations: 1) such methods tend to overfit each single training pair of images relying solely on the intra-image prior knowledge learned from the limited known area; 2) the inter-image prior knowledge about the general distribution patterns of visual semantics, which can be transferred across images sharing similar semantics, is not exploited. In this paper, we propose the Generative Memory-Guided Semantic Reasoning Model (GM-SRM), which not only learns the intra-image priors from the known regions, but also distills the inter-image reasoning priors to infer the content of the corrupted regions. In particular, the proposed GM-SRM first pre-learns a generative memory from the whole training data to capture the semantic distribution patterns in a global view. Then the learned memory are leveraged to retrieve the matching inter-image priors for the current corrupted image to perform semantic reasoning during image inpainting. While the intra-image priors are used for guaranteeing the pixel-level content consistency, the inter-image priors are favorable for performing high-level semantic reasoning, which is particularly effective for inferring semantic content for large corrupted area. Extensive experiments on Paris Street View, CelebA-HQ, and Places2 benchmarks demonstrate that our GM-SRM outperforms the state-of-the-art methods for image inpainting in terms of both the visual quality and quantitative metrics.