 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheck Me If You Can: Detecting ChatGPT-Generated Academic Writing using CheckGPT
Paper and Code
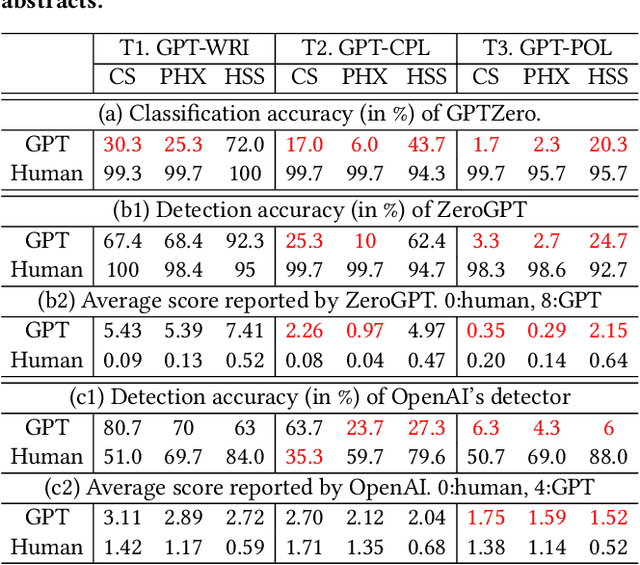

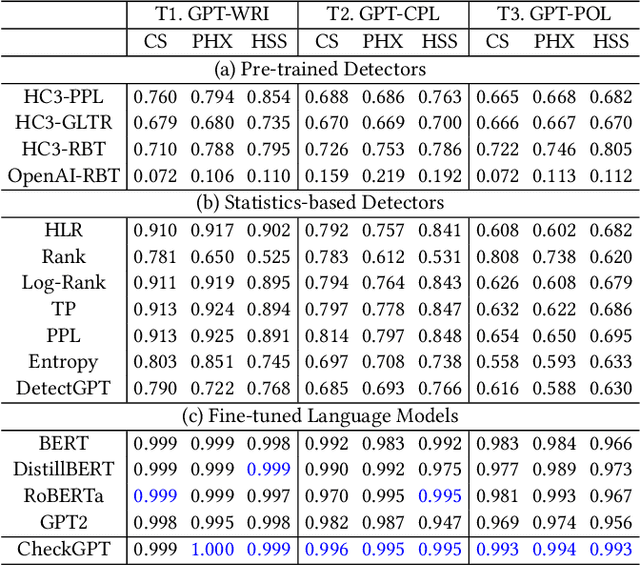
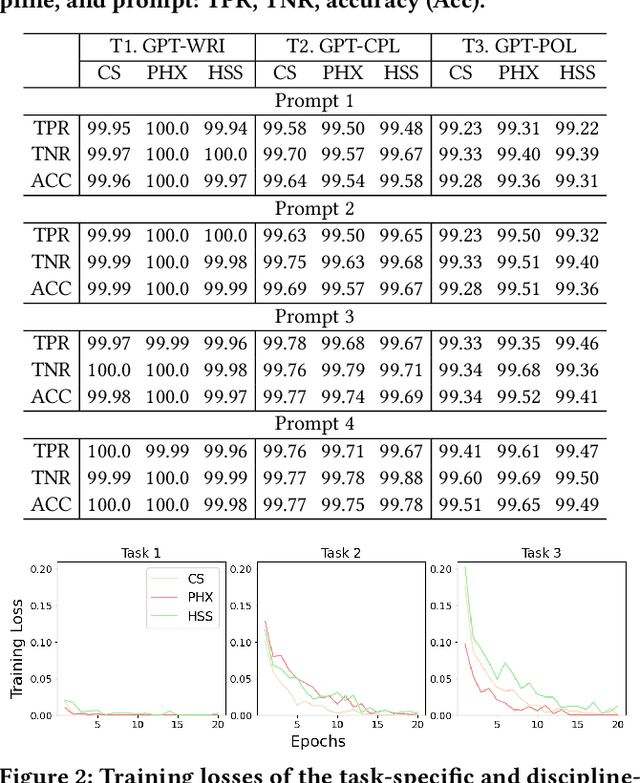
With ChatGPT under the spotlight, utilizing large language models (LLMs) for academic writing has drawn a significant amount of discussions and concerns in the community. While substantial research efforts have been stimulated for detecting LLM-Generated Content (LLM-content), most of the attempts are still in the early stage of exploration. In this paper, we present a holistic investigation of detecting LLM-generate academic writing, by providing a dataset, evidence, and algorithms, in order to inspire more community effort to address the concern of LLM academic misuse. We first present GPABenchmark, a benchmarking dataset of 600,000 samples of human-written, GPT-written, GPT-completed, and GPT-polished abstracts of research papers in CS, physics, and humanities and social sciences (HSS). We show that existing open-source and commercial GPT detectors provide unsatisfactory performance on GPABenchmark, especially for GPT-polished text. Moreover, through a user study of 150+ participants, we show that it is highly challenging for human users, including experienced faculty members and researchers, to identify GPT-generated abstracts. We then present CheckGPT, a novel LLM-content detector consisting of a general representation module and an attentive-BiLSTM classification module, which is accurate, transferable, and interpretable. Experimental results show that CheckGPT achieves an average classification accuracy of 98% to 99% for the task-specific discipline-specific detectors and the unified detectors. CheckGPT is also highly transferable that, without tuning, it achieves ~90% accuracy in new domains, such as news articles, while a model tuned with approximately 2,000 samples in the target domain achieves ~98% accuracy. Finally, we demonstrate the explainability insights obtained from CheckGPT to reveal the key behaviors of how LLM generates texts.