 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Souls in an Adversarial Image: Towards Universal Adversarial Example Detection using Multi-view Inconsistency
Oct 11, 2021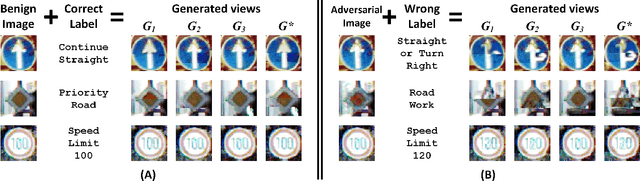
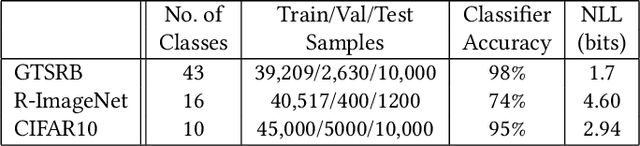
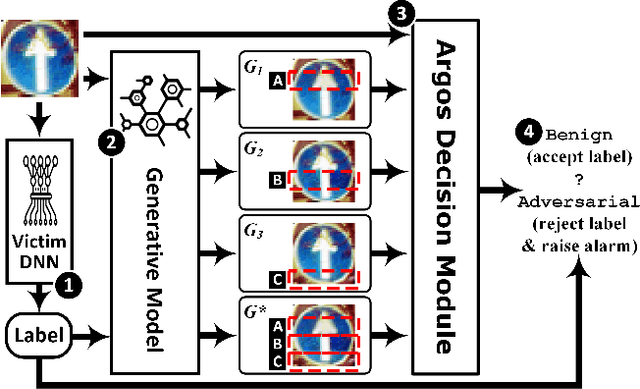
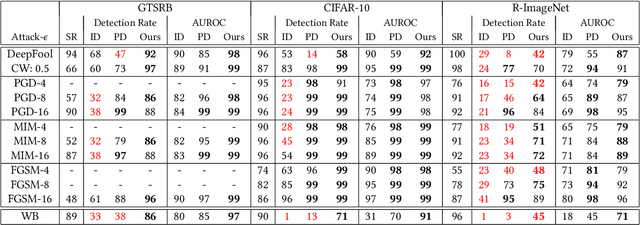
In the evasion attacks against deep neural networks (DNN), the attacker generates adversarial instances that are visually indistinguishable from benign samples and sends them to the target DNN to trigger misclassifications. In this paper, we propose a novel multi-view adversarial image detector, namely Argos, based on a novel observation. That is, there exist two "souls" in an adversarial instance, i.e., the visually unchanged content, which corresponds to the true label, and the added invisible perturbation, which corresponds to the misclassified label. Such inconsistencies could be further amplified through an autoregressive generative approach that generates images with seed pixels selected from the original image, a selected label, and pixel distributions learned from the training data. The generated images (i.e., the "views") will deviate significantly from the original one if the label is adversarial, demonstrating inconsistencies that Argos expects to detect. To this end, Argos first amplifies the discrepancies between the visual content of an image and its misclassified label induced by the attack using a set of regeneration mechanisms and then identifies an image as adversarial if the reproduced views deviate to a preset degree. Our experimental results show that Argos significantly outperforms two representative adversarial detectors in both detection accuracy and robustness against six well-known adversarial attacks. Code is available at: https://github.com/sohaib730/Argos-Adversarial_Detection
A Distributed Fair Machine Learning Framework with Private Demographic Data Protection
Sep 17, 2019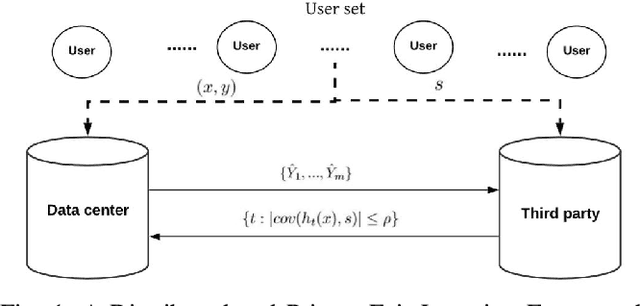
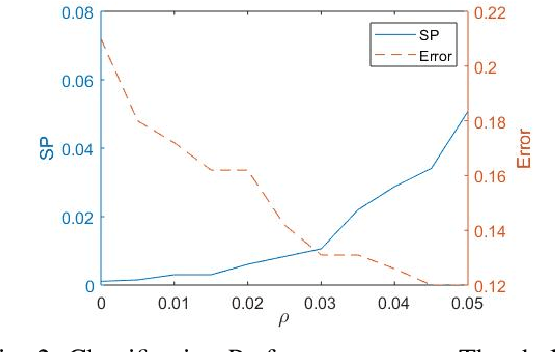
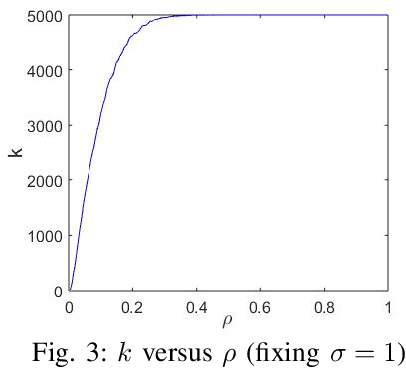
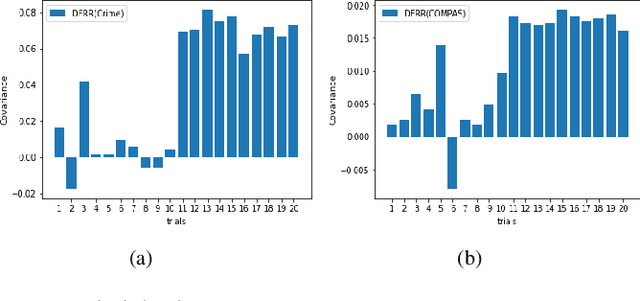
Fair machine learning has become a significant research topic with broad societal impact. However, most fair learning methods require direct access to personal demographic data, which is increasingly restricted to use for protecting user privacy (e.g. by the EU General Data Protection Regulation). In this paper, we propose a distributed fair learning framework for protecting the privacy of demographic data. We assume this data is privately held by a third party, which can communicate with the data center (responsible for model development) without revealing the demographic information. We propose a principled approach to design fair learning methods under this framework, exemplify four methods and show they consistently outperform their existing counterparts in both fairness and accuracy across three real-world data sets. We theoretically analyze the framework, and prove it can learn models with high fairness or high accuracy, with their trade-offs balanced by a threshold variable.
Fair Kernel Regression via Fair Feature Embedding in Kernel Space
Jul 04, 2019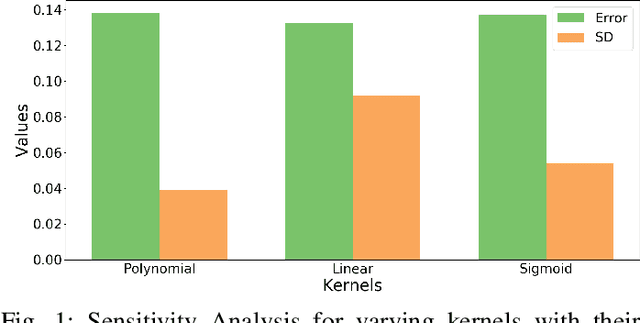
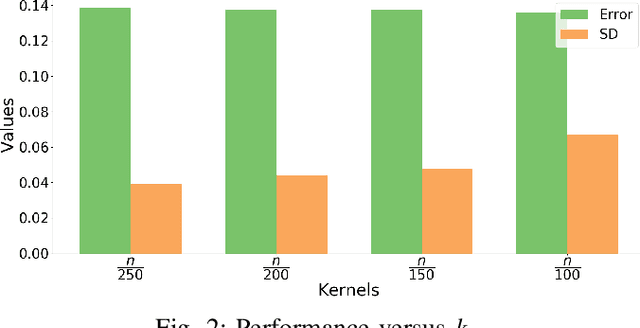
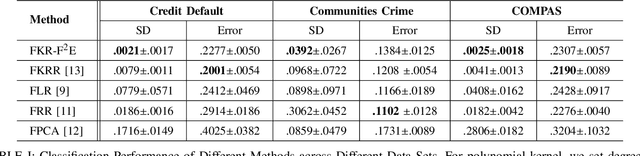
In recent years, there have been significant efforts on mitigating unethical demographic biases in machine learning methods. However, very little is done for kernel methods. In this paper, we propose a new fair kernel regression method via fair feature embedding (FKR-F$^2$E) in kernel space. Motivated by prior works on feature selection in kernel space and feature processing for fair machine learning, we propose to learn fair feature embedding functions that minimize demographic discrepancy of feature distributions in kernel space. Compared to the state-of-the-art fair kernel regression method and several baseline methods, we show FKR-F$^2$E achieves significantly lower prediction disparity across three real-world data sets.
Discriminatory Transfer
Aug 07, 2017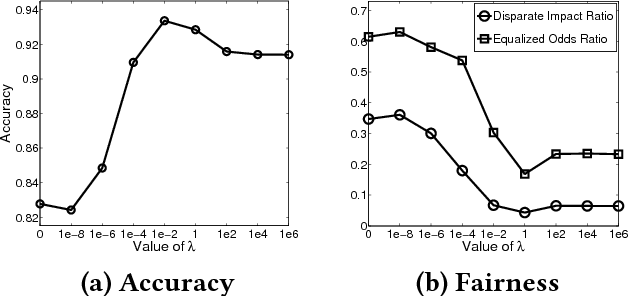
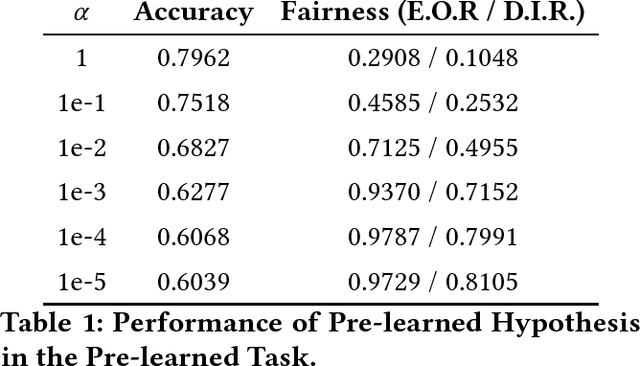
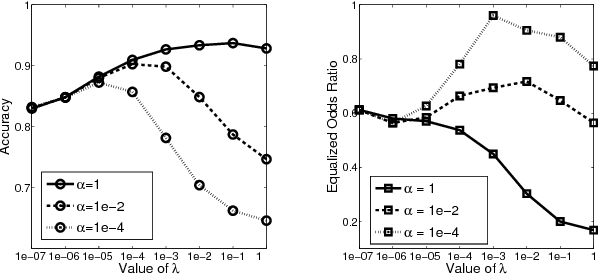
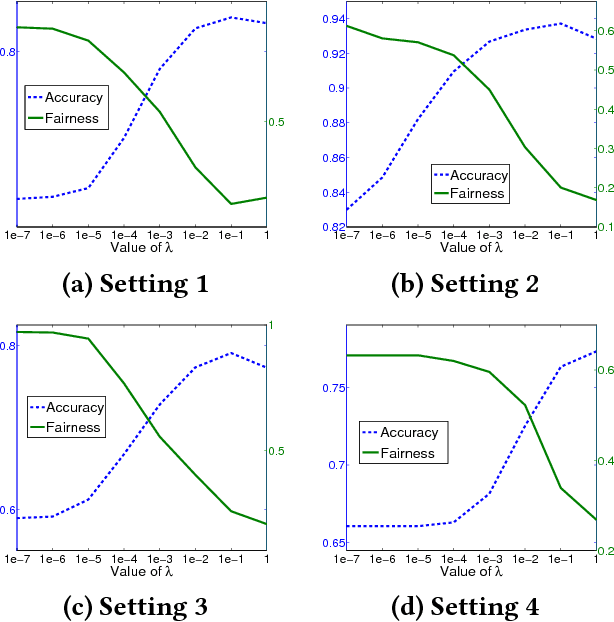
We observe standard transfer learning can improve prediction accuracies of target tasks at the cost of lowering their prediction fairness -- a phenomenon we named discriminatory transfer. We examine prediction fairness of a standard hypothesis transfer algorithm and a standard multi-task learning algorithm, and show they both suffer discriminatory transfer on the real-world Communities and Crime data set. The presented case study introduces an interaction between fairness and transfer learning, as an extension of existing fairness studies that focus on single task learning.
On the Unreported-Profile-is-Negative Assumption for Predictive Cheminformatics
Aug 07, 2017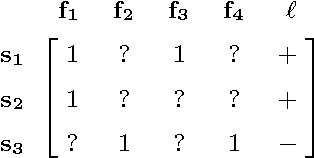


In cheminformatics, compound-target binding profiles has been a main source of data for research. For data repositories that only provide positive profiles, a popular assumption is that unreported profiles are all negative. In this paper, we caution audience not to take this assumption for granted, and present empirical evidence of its ineffectiveness from a machine learning perspective. Our examination is based on a setting where binding profiles are used as features to train predictive models; we show (1) prediction performance degrades when the assumption fails and (2) explicit recovery of unreported profiles improves prediction performance. In particular, we propose a framework that jointly recovers profiles and learns predictive model, and show it achieves further performance improvement. The presented study not only suggests applying matrix recovery methods to recover unreported profiles, but also initiates a new missing feature problem which we called Learning with Positive and Unknown Features.
Learning Social Circles in Ego Networks based on Multi-View Social Graphs
Dec 24, 2016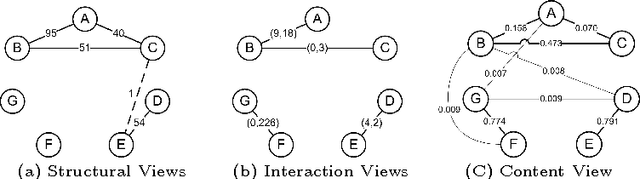
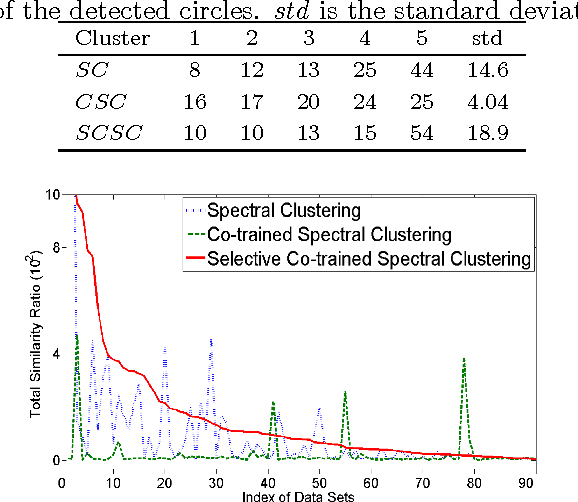
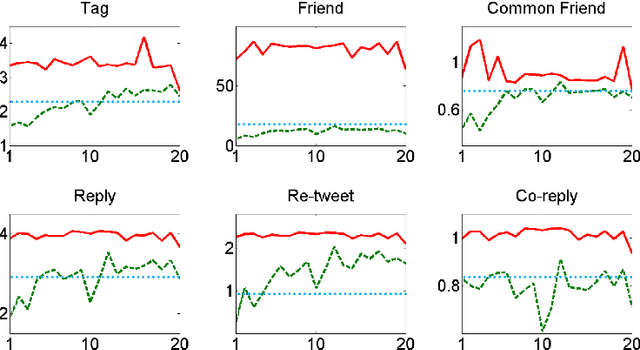
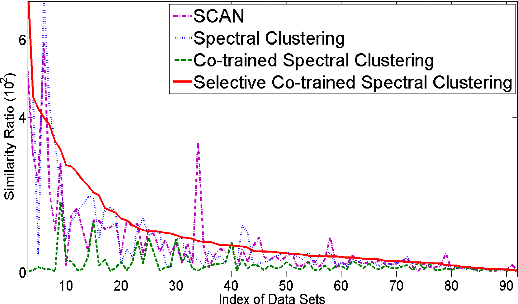
In social network analysis, automatic social circle detection in ego-networks is becoming a fundamental and important task, with many potential applications such as user privacy protection or interest group recommendation. So far, most studies have focused on addressing two questions, namely, how to detect overlapping circles and how to detect circles using a combination of network structure and network node attributes. This paper asks an orthogonal research question, that is, how to detect circles based on network structures that are (usually) described by multiple views? Our investigation begins with crawling ego-networks from Twitter and employing classic techniques to model their structures by six views, including user relationships, user interactions and user content. We then apply both standard and our modified multi-view spectral clustering techniques to detect social circles in these ego-networks. Based on extensive automatic and manual experimental evaluations, we deliver two major findings: first, multi-view clustering techniques perform better than common single-view clustering techniques, which only use one view or naively integrate all views for detection, second, the standard multi-view clustering technique is less robust than our modified technique, which selectively transfers information across views based on an assumption that sparse network structures are (potentially) incomplete. In particular, the second finding makes us believe a direct application of standard clustering on potentially incomplete networks may yield biased results. We lightly examine this issue in theory, where we derive an upper bound for such bias by integrating theories of spectral clustering and matrix perturbation, and discuss how it may be affected by several network characteristics.