 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Fair Machine Learning Framework with Private Demographic Data Protection
Paper and Code
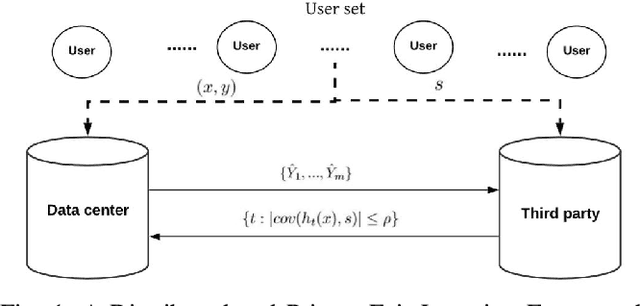
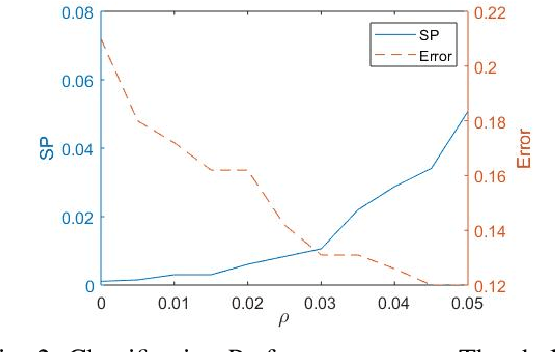
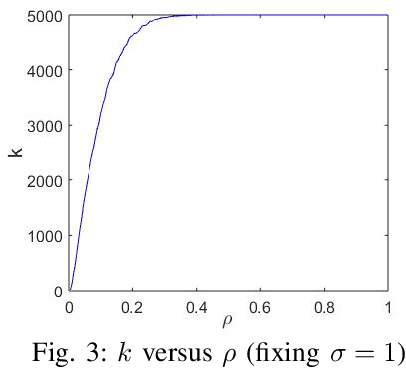
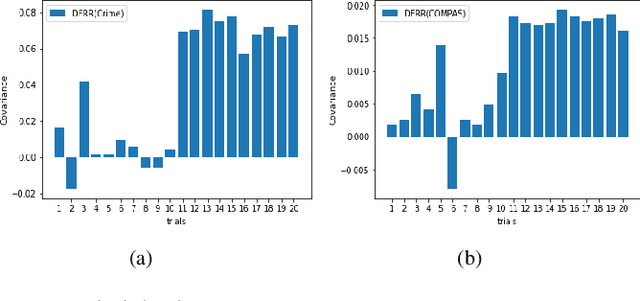
Fair machine learning has become a significant research topic with broad societal impact. However, most fair learning methods require direct access to personal demographic data, which is increasingly restricted to use for protecting user privacy (e.g. by the EU General Data Protection Regulation). In this paper, we propose a distributed fair learning framework for protecting the privacy of demographic data. We assume this data is privately held by a third party, which can communicate with the data center (responsible for model development) without revealing the demographic information. We propose a principled approach to design fair learning methods under this framework, exemplify four methods and show they consistently outperform their existing counterparts in both fairness and accuracy across three real-world data sets. We theoretically analyze the framework, and prove it can learn models with high fairness or high accuracy, with their trade-offs balanced by a threshold variable.