 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Memory-Guided Semantic Reasoning Model for Image Inpainting
Paper and Code
Oct 01, 2021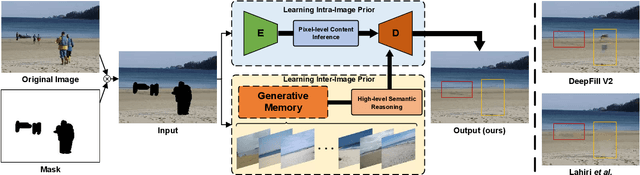

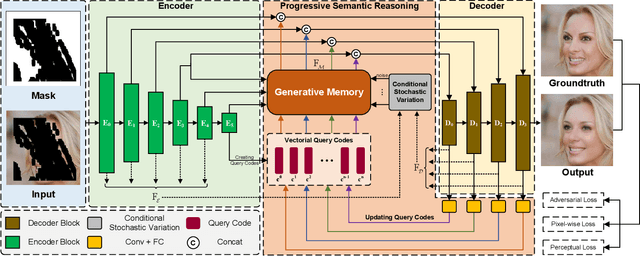
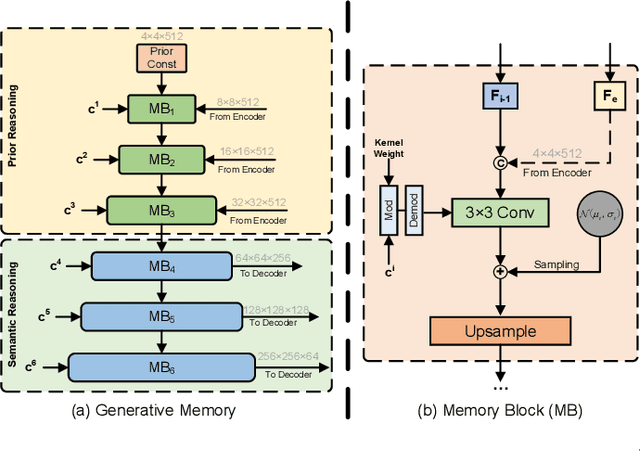
Most existing methods for image inpainting focus on learning the intra-image priors from the known regions of the current input image to infer the content of the corrupted regions in the same image. While such methods perform well on images with small corrupted regions, it is challenging for these methods to deal with images with large corrupted area due to two potential limitations: 1) such methods tend to overfit each single training pair of images relying solely on the intra-image prior knowledge learned from the limited known area; 2) the inter-image prior knowledge about the general distribution patterns of visual semantics, which can be transferred across images sharing similar semantics, is not exploited. In this paper, we propose the Generative Memory-Guided Semantic Reasoning Model (GM-SRM), which not only learns the intra-image priors from the known regions, but also distills the inter-image reasoning priors to infer the content of the corrupted regions. In particular, the proposed GM-SRM first pre-learns a generative memory from the whole training data to capture the semantic distribution patterns in a global view. Then the learned memory are leveraged to retrieve the matching inter-image priors for the current corrupted image to perform semantic reasoning during image inpainting. While the intra-image priors are used for guaranteeing the pixel-level content consistency, the inter-image priors are favorable for performing high-level semantic reasoning, which is particularly effective for inferring semantic content for large corrupted area. Extensive experiments on Paris Street View, CelebA-HQ, and Places2 benchmarks demonstrate that our GM-SRM outperforms the state-of-the-art methods for image inpainting in terms of both the visual quality and quantitative metrics.