 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStart from Video-Music Retrieval: An Inter-Intra Modal Loss for Cross Modal Retrieval
Jul 28, 2024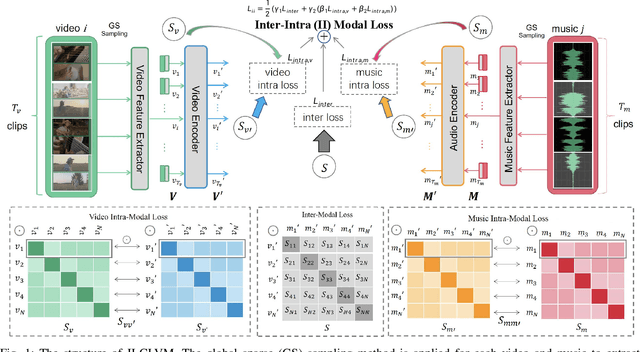
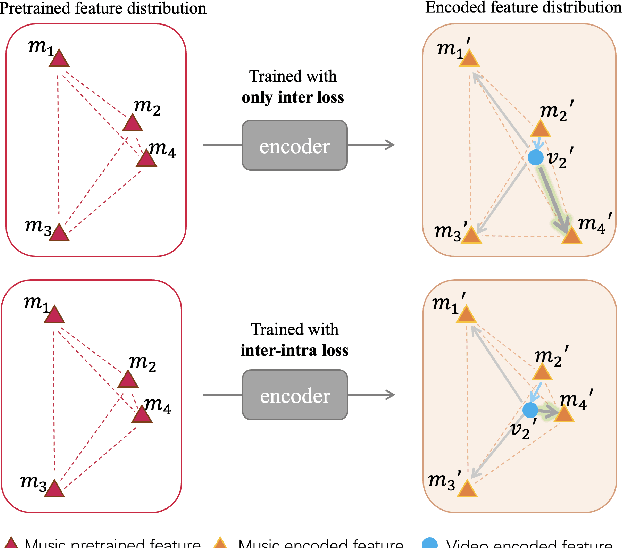
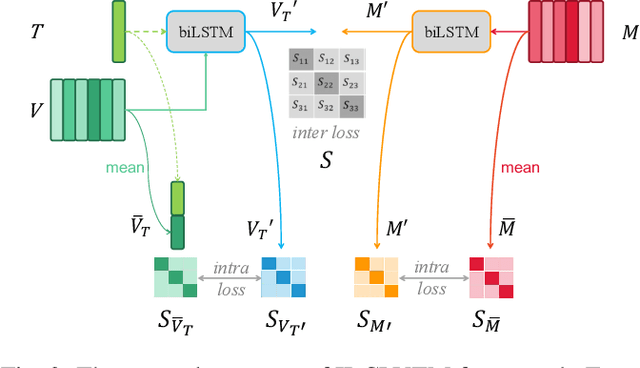
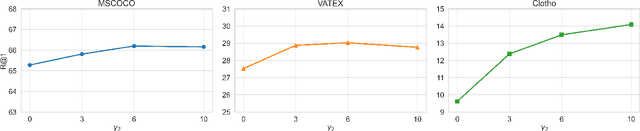
The burgeoning short video industry has accelerated the advancement of video-music retrieval technology, assisting content creators in selecting appropriate music for their videos. In self-supervised training for video-to-music retrieval, the video and music samples in the dataset are separated from the same video work, so they are all one-to-one matches. This does not match the real situation. In reality, a video can use different music as background music, and a music can be used as background music for different videos. Many videos and music that are not in a pair may be compatible, leading to false negative noise in the dataset. A novel inter-intra modal (II) loss is proposed as a solution. By reducing the variation of feature distribution within the two modalities before and after the encoder, II loss can reduce the model's overfitting to such noise without removing it in a costly and laborious way. The video-music retrieval framework, II-CLVM (Contrastive Learning for Video-Music Retrieval), incorporating the II Loss, achieves state-of-the-art performance on the YouTube8M dataset. The framework II-CLVTM shows better performance when retrieving music using multi-modal video information (such as text in videos). Experiments are designed to show that II loss can effectively alleviate the problem of false negative noise in retrieval tasks. Experiments also show that II loss improves various self-supervised and supervised uni-modal and cross-modal retrieval tasks, and can obtain good retrieval models with a small amount of training samples.
Metamorpheus: Interactive, Affective, and Creative Dream Narration Through Metaphorical Visual Storytelling
Mar 01, 2024



Human emotions are essentially molded by lived experiences, from which we construct personalised meaning. The engagement in such meaning-making process has been practiced as an intervention in various psychotherapies to promote wellness. Nevertheless, to support recollecting and recounting lived experiences in everyday life remains under explored in HCI. It also remains unknown how technologies such as generative AI models can facilitate the meaning making process, and ultimately support affective mindfulness. In this paper we present Metamorpheus, an affective interface that engages users in a creative visual storytelling of emotional experiences during dreams. Metamorpheus arranges the storyline based on a dream's emotional arc, and provokes self-reflection through the creation of metaphorical images and text depictions. The system provides metaphor suggestions, and generates visual metaphors and text depictions using generative AI models, while users can apply generations to recolour and re-arrange the interface to be visually affective. Our experience-centred evaluation manifests that, by interacting with Metamorpheus, users can recall their dreams in vivid detail, through which they relive and reflect upon their experiences in a meaningful way.
Unsupervised Learning Method for the Wave Equation Based on Finite Difference Residual Constraints Loss
Jan 23, 2024The wave equation is an important physical partial differential equation, and in recent years, deep learning has shown promise in accelerating or replacing traditional numerical methods for solving it. However, existing deep learning methods suffer from high data acquisition costs, low training efficiency, and insufficient generalization capability for boundary conditions. To address these issues, this paper proposes an unsupervised learning method for the wave equation based on finite difference residual constraints. We construct a novel finite difference residual constraint based on structured grids and finite difference methods, as well as an unsupervised training strategy, enabling convolutional neural networks to train without data and predict the forward propagation process of waves. Experimental results show that finite difference residual constraints have advantages over physics-informed neural networks (PINNs) type physical information constraints, such as easier fitting, lower computational costs, and stronger source term generalization capability, making our method more efficient in training and potent in application.
Hierarchical Contrastive Learning for Pattern-Generalizable Image Corruption Detection
Aug 27, 2023Effective image restoration with large-size corruptions, such as blind image inpainting, entails precise detection of corruption region masks which remains extremely challenging due to diverse shapes and patterns of corruptions. In this work, we present a novel method for automatic corruption detection, which allows for blind corruption restoration without known corruption masks. Specifically, we develop a hierarchical contrastive learning framework to detect corrupted regions by capturing the intrinsic semantic distinctions between corrupted and uncorrupted regions. In particular, our model detects the corrupted mask in a coarse-to-fine manner by first predicting a coarse mask by contrastive learning in low-resolution feature space and then refines the uncertain area of the mask by high-resolution contrastive learning. A specialized hierarchical interaction mechanism is designed to facilitate the knowledge propagation of contrastive learning in different scales, boosting the modeling performance substantially. The detected multi-scale corruption masks are then leveraged to guide the corruption restoration. Detecting corrupted regions by learning the contrastive distinctions rather than the semantic patterns of corruptions, our model has well generalization ability across different corruption patterns. Extensive experiments demonstrate following merits of our model: 1) the superior performance over other methods on both corruption detection and various image restoration tasks including blind inpainting and watermark removal, and 2) strong generalization across different corruption patterns such as graffiti, random noise or other image content. Codes and trained weights are available at https://github.com/xyfJASON/HCL .
Efficient Visual Computing with Camera RAW Snapshots
Dec 15, 2022



Conventional cameras capture image irradiance on a sensor and convert it to RGB images using an image signal processor (ISP). The images can then be used for photography or visual computing tasks in a variety of applications, such as public safety surveillance and autonomous driving. One can argue that since RAW images contain all the captured information, the conversion of RAW to RGB using an ISP is not necessary for visual computing. In this paper, we propose a novel $\rho$-Vision framework to perform high-level semantic understanding and low-level compression using RAW images without the ISP subsystem used for decades. Considering the scarcity of available RAW image datasets, we first develop an unpaired CycleR2R network based on unsupervised CycleGAN to train modular unrolled ISP and inverse ISP (invISP) models using unpaired RAW and RGB images. We can then flexibly generate simulated RAW images (simRAW) using any existing RGB image dataset and finetune different models originally trained for the RGB domain to process real-world camera RAW images. We demonstrate object detection and image compression capabilities in RAW-domain using RAW-domain YOLOv3 and RAW image compressor (RIC) on snapshots from various cameras. Quantitative results reveal that RAW-domain task inference provides better detection accuracy and compression compared to RGB-domain processing. Furthermore, the proposed \r{ho}-Vision generalizes across various camera sensors and different task-specific models. Additional advantages of the proposed $\rho$-Vision that eliminates the ISP are the potential reductions in computations and processing times.
Learning Generalizable Latent Representations for Novel Degradations in Super Resolution
Jul 25, 2022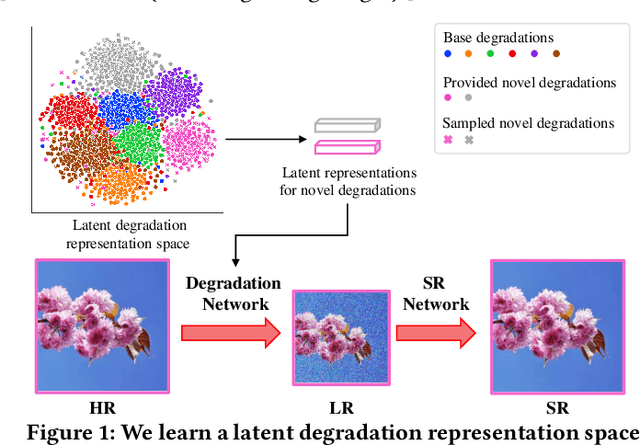

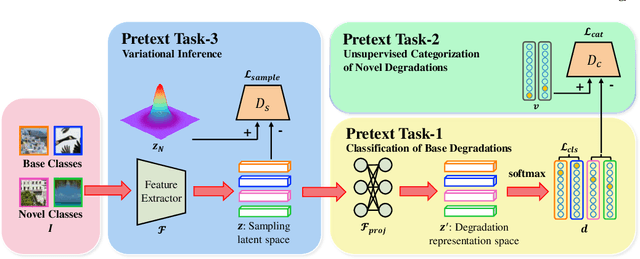
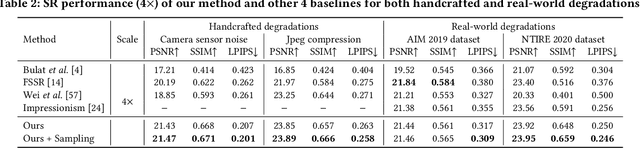
Typical methods for blind image super-resolution (SR) focus on dealing with unknown degradations by directly estimating them or learning the degradation representations in a latent space. A potential limitation of these methods is that they assume the unknown degradations can be simulated by the integration of various handcrafted degradations (e.g., bicubic downsampling), which is not necessarily true. The real-world degradations can be beyond the simulation scope by the handcrafted degradations, which are referred to as novel degradations. In this work, we propose to learn a latent representation space for degradations, which can be generalized from handcrafted (base) degradations to novel degradations. The obtained representations for a novel degradation in this latent space are then leveraged to generate degraded images consistent with the novel degradation to compose paired training data for SR model. Furthermore, we perform variational inference to match the posterior of degradations in latent representation space with a prior distribution (e.g., Gaussian distribution). Consequently, we are able to sample more high-quality representations for a novel degradation to augment the training data for SR model. We conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness and advantages of our method for blind super-resolution with novel degradations.
Learning Sequence Representations by Non-local Recurrent Neural Memory
Jul 20, 2022
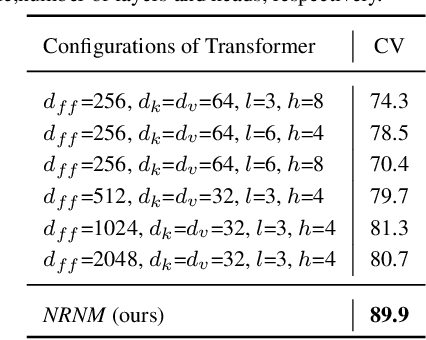

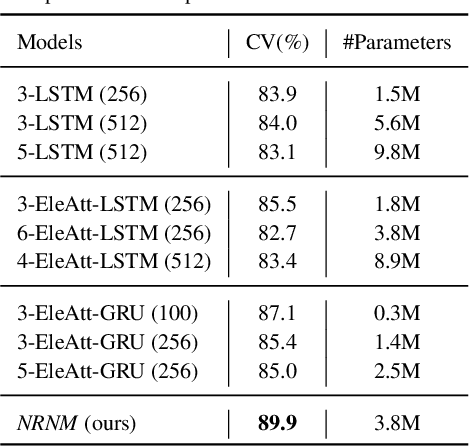
The key challenge of sequence representation learning is to capture the long-range temporal dependencies. Typical methods for supervised sequence representation learning are built upon recurrent neural networks to capture temporal dependencies. One potential limitation of these methods is that they only model one-order information interactions explicitly between adjacent time steps in a sequence, hence the high-order interactions between nonadjacent time steps are not fully exploited. It greatly limits the capability of modeling the long-range temporal dependencies since the temporal features learned by one-order interactions cannot be maintained for a long term due to temporal information dilution and gradient vanishing. To tackle this limitation, we propose the Non-local Recurrent Neural Memory (NRNM) for supervised sequence representation learning, which performs non-local operations \MR{by means of self-attention mechanism} to learn full-order interactions within a sliding temporal memory block and models global interactions between memory blocks in a gated recurrent manner. Consequently, our model is able to capture long-range dependencies. Besides, the latent high-level features contained in high-order interactions can be distilled by our model. We validate the effectiveness and generalization of our NRNM on three types of sequence applications across different modalities, including sequence classification, step-wise sequential prediction and sequence similarity learning. Our model compares favorably against other state-of-the-art methods specifically designed for each of these sequence applications.
Global-Local Stepwise Generative Network for Ultra High-Resolution Image Restoration
Jul 16, 2022



While the research on image background restoration from regular size of degraded images has achieved remarkable progress, restoring ultra high-resolution (e.g., 4K) images remains an extremely challenging task due to the explosion of computational complexity and memory usage, as well as the deficiency of annotated data. In this paper we present a novel model for ultra high-resolution image restoration, referred to as the Global-Local Stepwise Generative Network (GLSGN), which employs a stepwise restoring strategy involving four restoring pathways: three local pathways and one global pathway. The local pathways focus on conducting image restoration in a fine-grained manner over local but high-resolution image patches, while the global pathway performs image restoration coarsely on the scale-down but intact image to provide cues for the local pathways in a global view including semantics and noise patterns. To smooth the mutual collaboration between these four pathways, our GLSGN is designed to ensure the inter-pathway consistency in four aspects in terms of low-level content, perceptual attention, restoring intensity and high-level semantics, respectively. As another major contribution of this work, we also introduce the first ultra high-resolution dataset to date for both reflection removal and rain streak removal, comprising 4,670 real-world and synthetic images. Extensive experiments across three typical tasks for image background restoration, including image reflection removal, image rain streak removal and image dehazing, show that our GLSGN consistently outperforms state-of-the-art methods.
ViT-P: Rethinking Data-efficient Vision Transformers from Locality
Mar 04, 2022
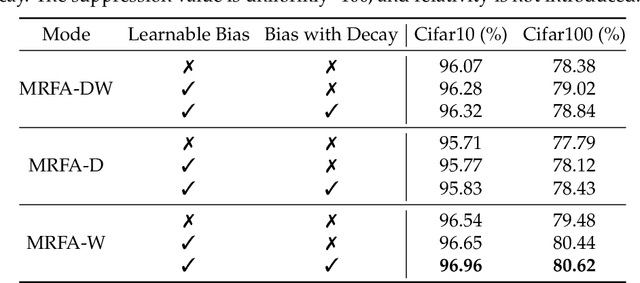

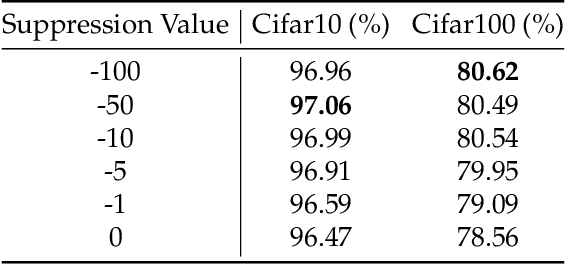
Recent advances of Transformers have brought new trust to computer vision tasks. However, on small dataset, Transformers is hard to train and has lower performance than convolutional neural networks. We make vision transformers as data-efficient as convolutional neural networks by introducing multi-focal attention bias. Inspired by the attention distance in a well-trained ViT, we constrain the self-attention of ViT to have multi-scale localized receptive field. The size of receptive field is adaptable during training so that optimal configuration can be learned. We provide empirical evidence that proper constrain of receptive field can reduce the amount of training data for vision transformers. On Cifar100, our ViT-P Base model achieves the state-of-the-art accuracy (83.16%) trained from scratch. We also perform analysis on ImageNet to show our method does not lose accuracy on large data sets.
U2-Former: A Nested U-shaped Transformer for Image Restoration
Dec 08, 2021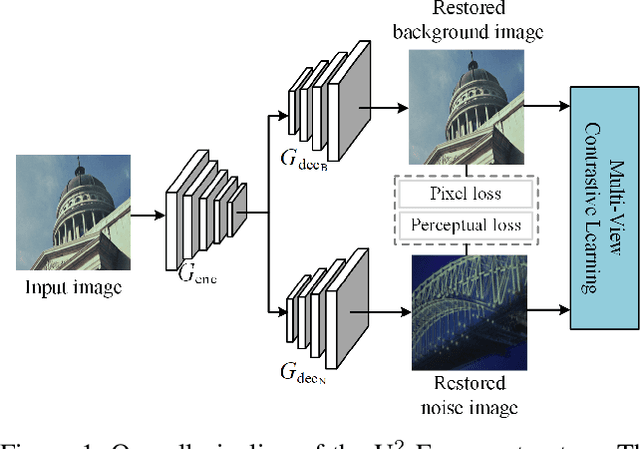
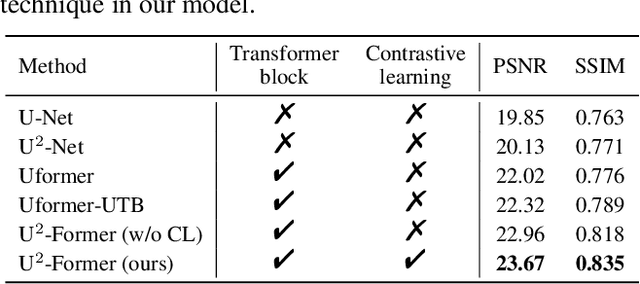
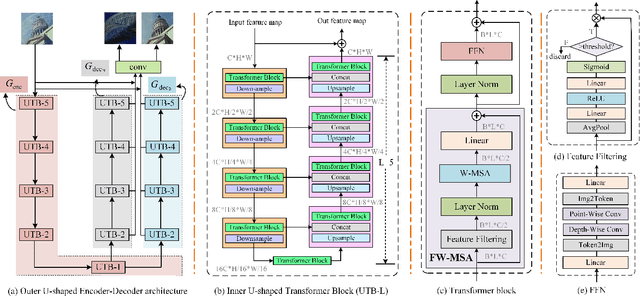
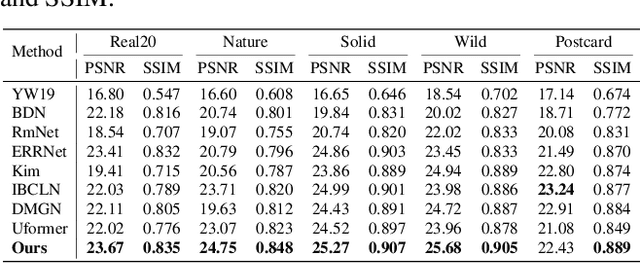
While Transformer has achieved remarkable performance in various high-level vision tasks, it is still challenging to exploit the full potential of Transformer in image restoration. The crux lies in the limited depth of applying Transformer in the typical encoder-decoder framework for image restoration, resulting from heavy self-attention computation load and inefficient communications across different depth (scales) of layers. In this paper, we present a deep and effective Transformer-based network for image restoration, termed as U2-Former, which is able to employ Transformer as the core operation to perform image restoration in a deep encoding and decoding space. Specifically, it leverages the nested U-shaped structure to facilitate the interactions across different layers with different scales of feature maps. Furthermore, we optimize the computational efficiency for the basic Transformer block by introducing a feature-filtering mechanism to compress the token representation. Apart from the typical supervision ways for image restoration, our U2-Former also performs contrastive learning in multiple aspects to further decouple the noise component from the background image. Extensive experiments on various image restoration tasks, including reflection removal, rain streak removal and dehazing respectively, demonstrate the effectiveness of the proposed U2-Former.