 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJodi: Unification of Visual Generation and Understanding via Joint Modeling
May 25, 2025Visual generation and understanding are two deeply interconnected aspects of human intelligence, yet they have been traditionally treated as separate tasks in machine learning. In this paper, we propose Jodi, a diffusion framework that unifies visual generation and understanding by jointly modeling the image domain and multiple label domains. Specifically, Jodi is built upon a linear diffusion transformer along with a role switch mechanism, which enables it to perform three particular types of tasks: (1) joint generation, where the model simultaneously generates images and multiple labels; (2) controllable generation, where images are generated conditioned on any combination of labels; and (3) image perception, where multiple labels can be predicted at once from a given image. Furthermore, we present the Joint-1.6M dataset, which contains 200,000 high-quality images collected from public sources, automatic labels for 7 visual domains, and LLM-generated captions. Extensive experiments demonstrate that Jodi excels in both generation and understanding tasks and exhibits strong extensibility to a wider range of visual domains. Code is available at https://github.com/VIPL-GENUN/Jodi.
RGBSQGrasp: Inferring Local Superquadric Primitives from Single RGB Image for Graspability-Aware Bin Picking
Mar 04, 2025

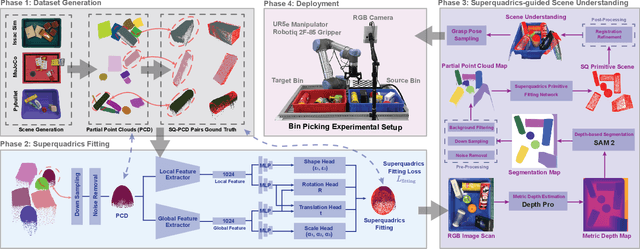

Bin picking is a challenging robotic task due to occlusions and physical constraints that limit visual information for object recognition and grasping. Existing approaches often rely on known CAD models or prior object geometries, restricting generalization to novel or unknown objects. Other methods directly regress grasp poses from RGB-D data without object priors, but the inherent noise in depth sensing and the lack of object understanding make grasp synthesis and evaluation more difficult. Superquadrics (SQ) offer a compact, interpretable shape representation that captures the physical and graspability understanding of objects. However, recovering them from limited viewpoints is challenging, as existing methods rely on multiple perspectives for near-complete point cloud reconstruction, limiting their effectiveness in bin-picking. To address these challenges, we propose \textbf{RGBSQGrasp}, a grasping framework that leverages superquadric shape primitives and foundation metric depth estimation models to infer grasp poses from a monocular RGB camera -- eliminating the need for depth sensors. Our framework integrates a universal, cross-platform dataset generation pipeline, a foundation model-based object point cloud estimation module, a global-local superquadric fitting network, and an SQ-guided grasp pose sampling module. By integrating these components, RGBSQGrasp reliably infers grasp poses through geometric reasoning, enhancing grasp stability and adaptability to unseen objects. Real-world robotic experiments demonstrate a 92\% grasp success rate, highlighting the effectiveness of RGBSQGrasp in packed bin-picking environments.
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
Jan 24, 2025We introduce DRESS, a novel approach for generating stylized large language model (LLM) responses through representation editing. Existing methods like prompting and fine-tuning are either insufficient for complex style adaptation or computationally expensive, particularly in tasks like NPC creation or character role-playing. Our approach leverages the over-parameterized nature of LLMs to disentangle a style-relevant subspace within the model's representation space to conduct representation editing, ensuring a minimal impact on the original semantics. By applying adaptive editing strengths, we dynamically adjust the steering vectors in the style subspace to maintain both stylistic fidelity and semantic integrity. We develop two stylized QA benchmark datasets to validate the effectiveness of DRESS, and the results demonstrate significant improvements compared to baseline methods such as prompting and ITI. In short, DRESS is a lightweight, train-free solution for enhancing LLMs with flexible and effective style control, making it particularly useful for developing stylized conversational agents. Codes and benchmark datasets are available at https://github.com/ArthurLeoM/DRESS-LLM.
CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation
Oct 12, 2024Recently, large-scale diffusion models have made impressive progress in text-to-image (T2I) generation. To further equip these T2I models with fine-grained spatial control, approaches like ControlNet introduce an extra network that learns to follow a condition image. However, for every single condition type, ControlNet requires independent training on millions of data pairs with hundreds of GPU hours, which is quite expensive and makes it challenging for ordinary users to explore and develop new types of conditions. To address this problem, we propose the CtrLoRA framework, which trains a Base ControlNet to learn the common knowledge of image-to-image generation from multiple base conditions, along with condition-specific LoRAs to capture distinct characteristics of each condition. Utilizing our pretrained Base ControlNet, users can easily adapt it to new conditions, requiring as few as 1,000 data pairs and less than one hour of single-GPU training to obtain satisfactory results in most scenarios. Moreover, our CtrLoRA reduces the learnable parameters by 90% compared to ControlNet, significantly lowering the threshold to distribute and deploy the model weights. Extensive experiments on various types of conditions demonstrate the efficiency and effectiveness of our method. Codes and model weights will be released at https://github.com/xyfJASON/ctrlora.
Hierarchical Contrastive Learning for Pattern-Generalizable Image Corruption Detection
Aug 27, 2023Effective image restoration with large-size corruptions, such as blind image inpainting, entails precise detection of corruption region masks which remains extremely challenging due to diverse shapes and patterns of corruptions. In this work, we present a novel method for automatic corruption detection, which allows for blind corruption restoration without known corruption masks. Specifically, we develop a hierarchical contrastive learning framework to detect corrupted regions by capturing the intrinsic semantic distinctions between corrupted and uncorrupted regions. In particular, our model detects the corrupted mask in a coarse-to-fine manner by first predicting a coarse mask by contrastive learning in low-resolution feature space and then refines the uncertain area of the mask by high-resolution contrastive learning. A specialized hierarchical interaction mechanism is designed to facilitate the knowledge propagation of contrastive learning in different scales, boosting the modeling performance substantially. The detected multi-scale corruption masks are then leveraged to guide the corruption restoration. Detecting corrupted regions by learning the contrastive distinctions rather than the semantic patterns of corruptions, our model has well generalization ability across different corruption patterns. Extensive experiments demonstrate following merits of our model: 1) the superior performance over other methods on both corruption detection and various image restoration tasks including blind inpainting and watermark removal, and 2) strong generalization across different corruption patterns such as graffiti, random noise or other image content. Codes and trained weights are available at https://github.com/xyfJASON/HCL .
Fed-TDA: Federated Tabular Data Augmentation on Non-IID Data
Nov 22, 2022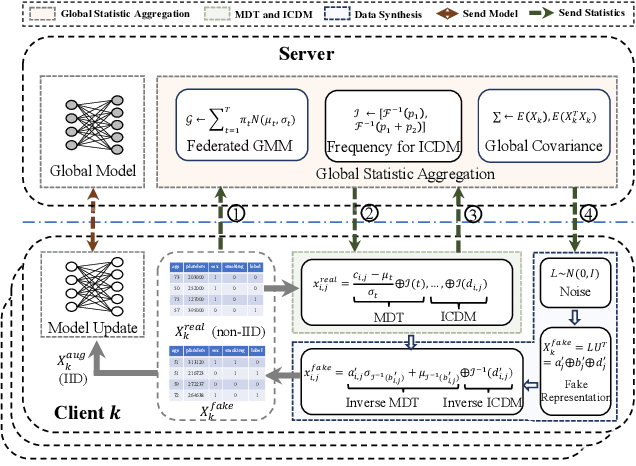

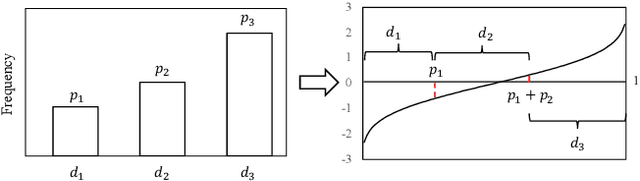
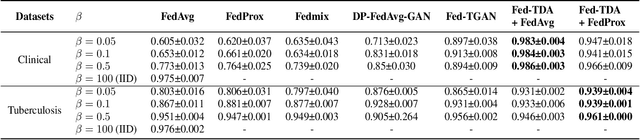
Non-independent and identically distributed (non-IID) data is a key challenge in federated learning (FL), which usually hampers the optimization convergence and the performance of FL. Existing data augmentation methods based on federated generative models or raw data sharing strategies for solving the non-IID problem still suffer from low performance, privacy protection concerns, and high communication overhead in decentralized tabular data. To tackle these challenges, we propose a federated tabular data augmentation method, named Fed-TDA. The core idea of Fed-TDA is to synthesize tabular data for data augmentation using some simple statistics (e.g., distributions of each column and global covariance). Specifically, we propose the multimodal distribution transformation and inverse cumulative distribution mapping respectively synthesize continuous and discrete columns in tabular data from a noise according to the pre-learned statistics. Furthermore, we theoretically analyze that our Fed-TDA not only preserves data privacy but also maintains the distribution of the original data and the correlation between columns. Through extensive experiments on five real-world tabular datasets, we demonstrate the superiority of Fed-TDA over the state-of-the-art in test performance and communication efficiency.