 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPFT-SQL: Enhancing Large Language Model for Text-to-SQL Parsing by Self-Play Fine-Tuning
Sep 04, 2025Despite the significant advancements of self-play fine-tuning (SPIN), which can transform a weak large language model (LLM) into a strong one through competitive interactions between models of varying capabilities, it still faces challenges in the Text-to-SQL task. SPIN does not generate new information, and the large number of correct SQL queries produced by the opponent model during self-play reduces the main model's ability to generate accurate SQL queries. To address this challenge, we propose a new self-play fine-tuning method tailored for the Text-to-SQL task, called SPFT-SQL. Prior to self-play, we introduce a verification-based iterative fine-tuning approach, which synthesizes high-quality fine-tuning data iteratively based on the database schema and validation feedback to enhance model performance, while building a model base with varying capabilities. During the self-play fine-tuning phase, we propose an error-driven loss method that incentivizes incorrect outputs from the opponent model, enabling the main model to distinguish between correct SQL and erroneous SQL generated by the opponent model, thereby improving its ability to generate correct SQL. Extensive experiments and in-depth analyses on six open-source LLMs and five widely used benchmarks demonstrate that our approach outperforms existing state-of-the-art (SOTA) methods.
Generative Data Augmentation for Non-IID Problem in Decentralized Clinical Machine Learning
Dec 02, 2022



Swarm learning (SL) is an emerging promising decentralized machine learning paradigm and has achieved high performance in clinical applications. SL solves the problem of a central structure in federated learning by combining edge computing and blockchain-based peer-to-peer network. While there are promising results in the assumption of the independent and identically distributed (IID) data across participants, SL suffers from performance degradation as the degree of the non-IID data increases. To address this problem, we propose a generative augmentation framework in swarm learning called SL-GAN, which augments the non-IID data by generating the synthetic data from participants. SL-GAN trains generators and discriminators locally, and periodically aggregation via a randomly elected coordinator in SL network. Under the standard assumptions, we theoretically prove the convergence of SL-GAN using stochastic approximations. Experimental results demonstrate that SL-GAN outperforms state-of-art methods on three real world clinical datasets including Tuberculosis, Leukemia, COVID-19.
Fed-TDA: Federated Tabular Data Augmentation on Non-IID Data
Nov 22, 2022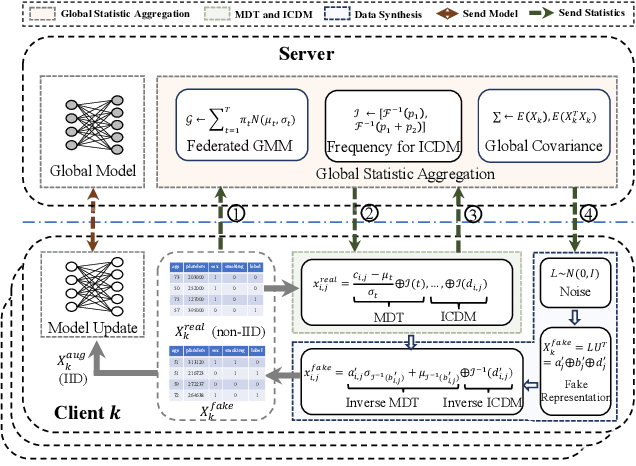

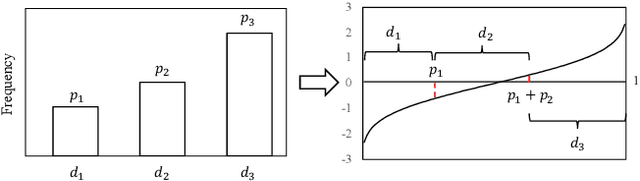
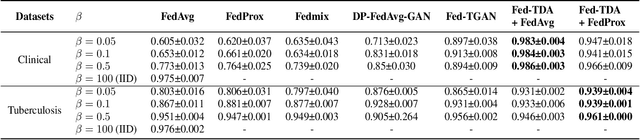
Non-independent and identically distributed (non-IID) data is a key challenge in federated learning (FL), which usually hampers the optimization convergence and the performance of FL. Existing data augmentation methods based on federated generative models or raw data sharing strategies for solving the non-IID problem still suffer from low performance, privacy protection concerns, and high communication overhead in decentralized tabular data. To tackle these challenges, we propose a federated tabular data augmentation method, named Fed-TDA. The core idea of Fed-TDA is to synthesize tabular data for data augmentation using some simple statistics (e.g., distributions of each column and global covariance). Specifically, we propose the multimodal distribution transformation and inverse cumulative distribution mapping respectively synthesize continuous and discrete columns in tabular data from a noise according to the pre-learned statistics. Furthermore, we theoretically analyze that our Fed-TDA not only preserves data privacy but also maintains the distribution of the original data and the correlation between columns. Through extensive experiments on five real-world tabular datasets, we demonstrate the superiority of Fed-TDA over the state-of-the-art in test performance and communication efficiency.