 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAED: a New Paradigm for Few-shot Graph Learning with Explanation in the Loop
Mar 02, 2026The challenges of training and inference in few-shot environments persist in the area of graph representation learning. The quality and quantity of labels are often insufficient due to the extensive expert knowledge required to annotate graph data. In this context, Few-Shot Graph Learning (FSGL) approaches have been developed over the years. Through sophisticated neural architectures and customized training pipelines, these approaches enhance model adaptability to new label distributions. However, compromises in \textcolor{black}{the model's} robustness and interpretability can result in overfitting to noise in labeled data and degraded performance. This paper introduces the first explanation-in-the-loop framework for the FSGL problem, called BAED. We novelly employ the belief propagation algorithm to facilitate label augmentation on graphs. Then, leveraging an auxiliary graph neural network and the gradient backpropagation method, our framework effectively extracts explanatory subgraphs surrounding target nodes. The final predictions are based on these informative subgraphs while mitigating the influence of redundant information from neighboring nodes. Extensive experiments on seven benchmark datasets demonstrate superior prediction accuracy, training efficiency, and explanation quality of BAED. As a pioneer, this work highlights the potential of the explanation-based research paradigm in FSGL.
Explanation-Guided Adversarial Training for Robust and Interpretable Models
Mar 02, 2026Deep neural networks (DNNs) have achieved remarkable performance in many tasks, yet they often behave as opaque black boxes. Explanation-guided learning (EGL) methods steer DNNs using human-provided explanations or supervision on model attributions. These approaches improve interpretability but typically assume benign inputs and incur heavy annotation costs. In contrast, both predictions and saliency maps of DNNs could dramatically alter facing imperceptible perturbations or unseen patterns. Adversarial training (AT) can substantially improve robustness, but it does not guarantee that model decisions rely on semantically meaningful features. In response, we propose Explanation-Guided Adversarial Training (EGAT), a unified framework that integrates the strength of AT and EGL to simultaneously improve prediction performance, robustness, and explanation quality. EGAT generates adversarial examples on the fly while imposing explanation-based constraints on the model. By jointly optimizing classification performance, adversarial robustness, and attributional stability, EGAT is not only more resistant to unexpected cases, including adversarial attacks and out-of-distribution (OOD) scenarios, but also offer human-interpretable justifications for the decisions. We further formalize EGAT within the Probably Approximately Correct learning framework, demonstrating theoretically that it yields more stable predictions under unexpected situations compared to standard AT. Empirical evaluations on OOD benchmark datasets show that EGAT consistently outperforms competitive baselines in both clean accuracy and adversarial accuracy +37% while producing more semantically meaningful explanations, and requiring only a limited increase +16% in training time.
Simple Network Graph Comparative Learning
Jan 15, 2026The effectiveness of contrastive learning methods has been widely recognized in the field of graph learning, especially in contexts where graph data often lack labels or are difficult to label. However, the application of these methods to node classification tasks still faces a number of challenges. First, existing data enhancement techniques may lead to significant differences from the original view when generating new views, which may weaken the relevance of the view and affect the efficiency of model training. Second, the vast majority of existing graph comparison learning algorithms rely on the use of a large number of negative samples. To address the above challenges, this study proposes a novel node classification contrast learning method called Simple Network Graph Comparative Learning (SNGCL). Specifically, SNGCL employs a superimposed multilayer Laplace smoothing filter as a step in processing the data to obtain global and local feature smoothing matrices, respectively, which are thus passed into the target and online networks of the siamese network, and finally employs an improved triple recombination loss function to bring the intra-class distance closer and the inter-class distance farther. We have compared SNGCL with state-of-the-art models in node classification tasks, and the experimental results show that SNGCL is strongly competitive in most tasks.
Defense Against Indirect Prompt Injection via Tool Result Parsing
Jan 08, 2026As LLM agents transition from digital assistants to physical controllers in autonomous systems and robotics, they face an escalating threat from indirect prompt injection. By embedding adversarial instructions into the results of tool calls, attackers can hijack the agent's decision-making process to execute unauthorized actions. This vulnerability poses a significant risk as agents gain more direct control over physical environments. Existing defense mechanisms against Indirect Prompt Injection (IPI) generally fall into two categories. The first involves training dedicated detection models; however, this approach entails high computational overhead for both training and inference, and requires frequent updates to keep pace with evolving attack vectors. Alternatively, prompt-based methods leverage the inherent capabilities of LLMs to detect or ignore malicious instructions via prompt engineering. Despite their flexibility, most current prompt-based defenses suffer from high Attack Success Rates (ASR), demonstrating limited robustness against sophisticated injection attacks. In this paper, we propose a novel method that provides LLMs with precise data via tool result parsing while effectively filtering out injected malicious code. Our approach achieves competitive Utility under Attack (UA) while maintaining the lowest Attack Success Rate (ASR) to date, significantly outperforming existing methods. Code is available at GitHub.
SPFT-SQL: Enhancing Large Language Model for Text-to-SQL Parsing by Self-Play Fine-Tuning
Sep 04, 2025Despite the significant advancements of self-play fine-tuning (SPIN), which can transform a weak large language model (LLM) into a strong one through competitive interactions between models of varying capabilities, it still faces challenges in the Text-to-SQL task. SPIN does not generate new information, and the large number of correct SQL queries produced by the opponent model during self-play reduces the main model's ability to generate accurate SQL queries. To address this challenge, we propose a new self-play fine-tuning method tailored for the Text-to-SQL task, called SPFT-SQL. Prior to self-play, we introduce a verification-based iterative fine-tuning approach, which synthesizes high-quality fine-tuning data iteratively based on the database schema and validation feedback to enhance model performance, while building a model base with varying capabilities. During the self-play fine-tuning phase, we propose an error-driven loss method that incentivizes incorrect outputs from the opponent model, enabling the main model to distinguish between correct SQL and erroneous SQL generated by the opponent model, thereby improving its ability to generate correct SQL. Extensive experiments and in-depth analyses on six open-source LLMs and five widely used benchmarks demonstrate that our approach outperforms existing state-of-the-art (SOTA) methods.
Exploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities
May 28, 2025



Converting natural language (NL) questions into SQL queries, referred to as Text-to-SQL, has emerged as a pivotal technology for facilitating access to relational databases, especially for users without SQL knowledge. Recent progress in large language models (LLMs) has markedly propelled the field of natural language processing (NLP), opening new avenues to improve text-to-SQL systems. This study presents a systematic review of LLM-based text-to-SQL, focusing on four key aspects: (1) an analysis of the research trends in LLM-based text-to-SQL; (2) an in-depth analysis of existing LLM-based text-to-SQL techniques from diverse perspectives; (3) summarization of existing text-to-SQL datasets and evaluation metrics; and (4) discussion on potential obstacles and avenues for future exploration in this domain. This survey seeks to furnish researchers with an in-depth understanding of LLM-based text-to-SQL, sparking new innovations and advancements in this field.
QDA-SQL: Questions Enhanced Dialogue Augmentation for Multi-Turn Text-to-SQL
Jun 15, 2024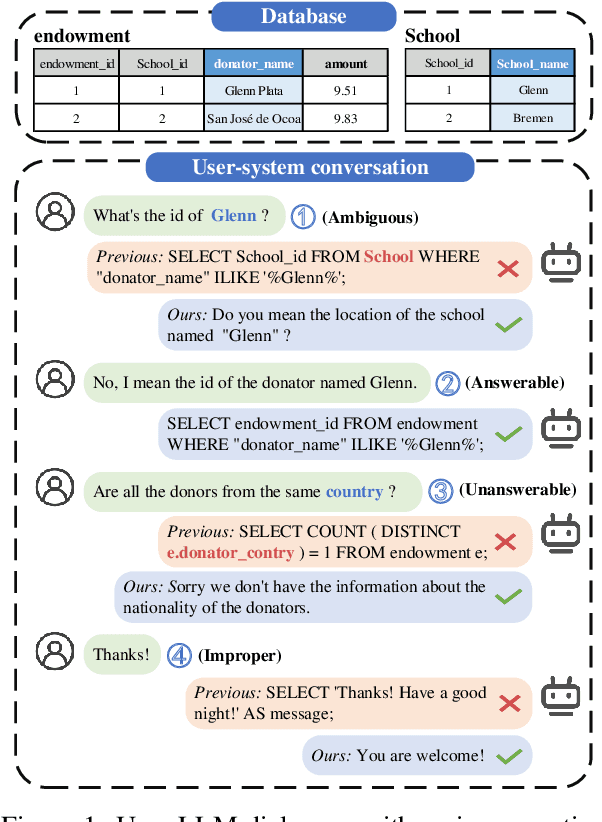

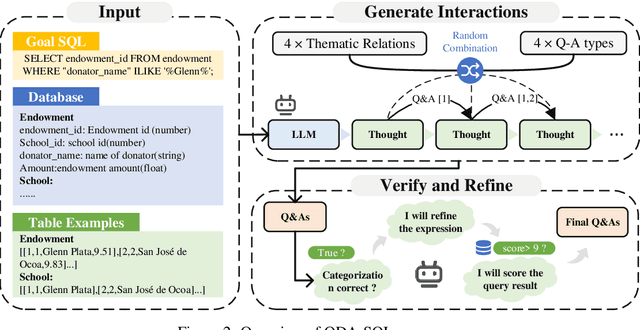

Fine-tuning large language models (LLMs) for specific domain tasks has achieved great success in Text-to-SQL tasks. However, these fine-tuned models often face challenges with multi-turn Text-to-SQL tasks caused by ambiguous or unanswerable questions. It is desired to enhance LLMs to handle multiple types of questions in multi-turn Text-to-SQL tasks. To address this, we propose a novel data augmentation method, called QDA-SQL, which generates multiple types of multi-turn Q\&A pairs by using LLMs. In QDA-SQL, we introduce a novel data augmentation method incorporating validation and correction mechanisms to handle complex multi-turn Text-to-SQL tasks. Experimental results demonstrate that QDA-SQL enables fine-tuned models to exhibit higher performance on SQL statement accuracy and enhances their ability to handle complex, unanswerable questions in multi-turn Text-to-SQL tasks. The generation script and test set are released at https://github.com/mcxiaoxiao/QDA-SQL.
First-principles Based 3D Virtual Simulation Testing for Discovering SOTIF Corner Cases of Autonomous Driving
Jan 22, 20243D virtual simulation, which generates diversified test scenarios and tests full-stack of Autonomous Driving Systems (ADSes) modules dynamically as a whole, is a promising approach for Safety of The Intended Functionality (SOTIF) ADS testing. However, as different configurations of a test scenario will affect the sensor perceptions and environment interaction, e.g. light pulses emitted by the LiDAR sensor will undergo backscattering and attenuation, which is usually overlooked by existing works, leading to false positives or wrong results. Moreover, the input space of an ADS is extremely large, with infinite number of possible initial scenarios and mutations, along both temporal and spatial domains. This paper proposes a first-principles based sensor modeling and environment interaction scheme, and integrates it into CARLA simulator. With this scheme, a long-overlooked category of adverse weather related corner cases are discovered, along with their root causes. Moreover, a meta-heuristic algorithm is designed based on several empirical insights, which guide both seed scenarios and mutations, significantly reducing the search dimensions of scenarios and enhancing the efficiency of corner case identification. Experimental results show that under identical simulation setups, our algorithm discovers about four times as many corner cases as compared to state-of-the-art work.
ZO-AdaMU Optimizer: Adapting Perturbation by the Momentum and Uncertainty in Zeroth-order Optimization
Dec 23, 2023Lowering the memory requirement in full-parameter training on large models has become a hot research area. MeZO fine-tunes the large language models (LLMs) by just forward passes in a zeroth-order SGD optimizer (ZO-SGD), demonstrating excellent performance with the same GPU memory usage as inference. However, the simulated perturbation stochastic approximation for gradient estimate in MeZO leads to severe oscillations and incurs a substantial time overhead. Moreover, without momentum regularization, MeZO shows severe over-fitting problems. Lastly, the perturbation-irrelevant momentum on ZO-SGD does not improve the convergence rate. This study proposes ZO-AdaMU to resolve the above problems by adapting the simulated perturbation with momentum in its stochastic approximation. Unlike existing adaptive momentum methods, we relocate momentum on simulated perturbation in stochastic gradient approximation. Our convergence analysis and experiments prove this is a better way to improve convergence stability and rate in ZO-SGD. Extensive experiments demonstrate that ZO-AdaMU yields better generalization for LLMs fine-tuning across various NLP tasks than MeZO and its momentum variants.
State-of-the-art optical-based physical adversarial attacks for deep learning computer vision systems
Mar 22, 2023



Adversarial attacks can mislead deep learning models to make false predictions by implanting small perturbations to the original input that are imperceptible to the human eye, which poses a huge security threat to the computer vision systems based on deep learning. Physical adversarial attacks, which is more realistic, as the perturbation is introduced to the input before it is being captured and converted to a binary image inside the vision system, when compared to digital adversarial attacks. In this paper, we focus on physical adversarial attacks and further classify them into invasive and non-invasive. Optical-based physical adversarial attack techniques (e.g. using light irradiation) belong to the non-invasive category. As the perturbations can be easily ignored by humans as the perturbations are very similar to the effects generated by a natural environment in the real world. They are highly invisibility and executable and can pose a significant or even lethal threats to real systems. This paper focuses on optical-based physical adversarial attack techniques for computer vision systems, with emphasis on the introduction and discussion of optical-based physical adversarial attack techniques.