 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2Vformer: A Flexible Time Series Prediction Model Based on Time Position Embedding
Sep 17, 2024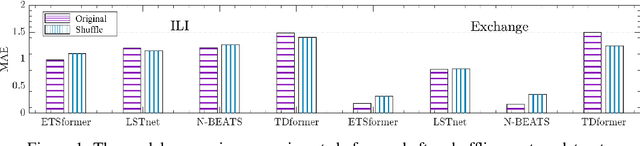
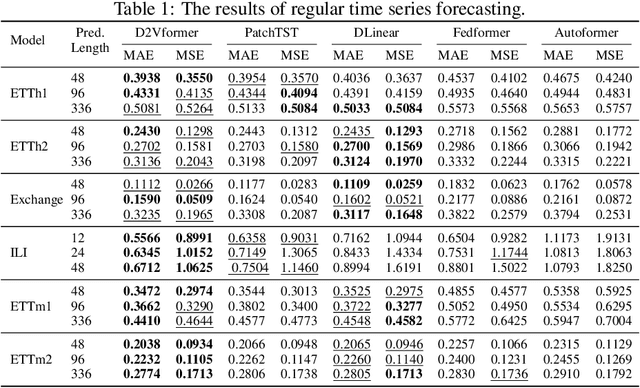

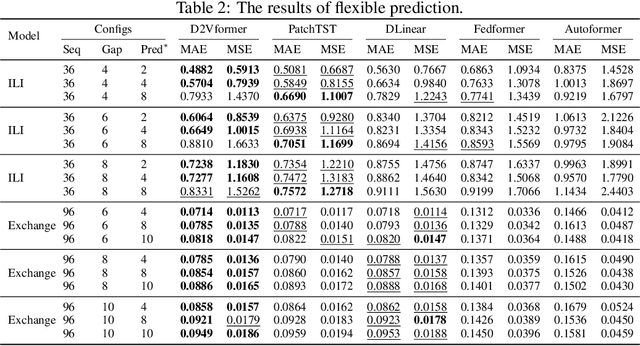
Time position embeddings capture the positional information of time steps, often serving as auxiliary inputs to enhance the predictive capabilities of time series models. However, existing models exhibit limitations in capturing intricate time positional information and effectively utilizing these embeddings. To address these limitations, this paper proposes a novel model called D2Vformer. Unlike typical prediction methods that rely on RNNs or Transformers, this approach can directly handle scenarios where the predicted sequence is not adjacent to the input sequence or where its length dynamically changes. In comparison to conventional methods, D2Vformer undoubtedly saves a significant amount of training resources. In D2Vformer, the Date2Vec module uses the timestamp information and feature sequences to generate time position embeddings. Afterward, D2Vformer introduces a new fusion block that utilizes an attention mechanism to explore the similarity in time positions between the embeddings of the input sequence and the predicted sequence, thereby generating predictions based on this similarity. Through extensive experiments on six datasets, we demonstrate that Date2Vec outperforms other time position embedding methods, and D2Vformer surpasses state-of-the-art methods in both fixed-length and variable-length prediction tasks.
ZO-AdaMU Optimizer: Adapting Perturbation by the Momentum and Uncertainty in Zeroth-order Optimization
Dec 23, 2023Lowering the memory requirement in full-parameter training on large models has become a hot research area. MeZO fine-tunes the large language models (LLMs) by just forward passes in a zeroth-order SGD optimizer (ZO-SGD), demonstrating excellent performance with the same GPU memory usage as inference. However, the simulated perturbation stochastic approximation for gradient estimate in MeZO leads to severe oscillations and incurs a substantial time overhead. Moreover, without momentum regularization, MeZO shows severe over-fitting problems. Lastly, the perturbation-irrelevant momentum on ZO-SGD does not improve the convergence rate. This study proposes ZO-AdaMU to resolve the above problems by adapting the simulated perturbation with momentum in its stochastic approximation. Unlike existing adaptive momentum methods, we relocate momentum on simulated perturbation in stochastic gradient approximation. Our convergence analysis and experiments prove this is a better way to improve convergence stability and rate in ZO-SGD. Extensive experiments demonstrate that ZO-AdaMU yields better generalization for LLMs fine-tuning across various NLP tasks than MeZO and its momentum variants.