 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIRA: A Learning-based Query-aware Partition Framework for Large-scale ANN Search
Mar 30, 2025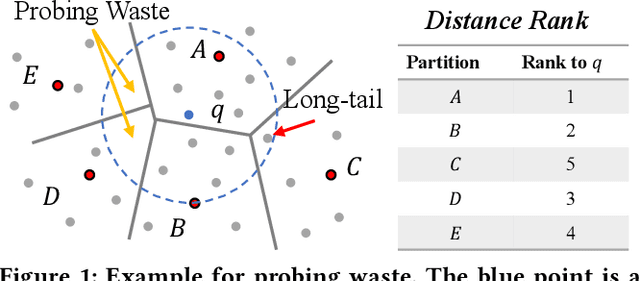
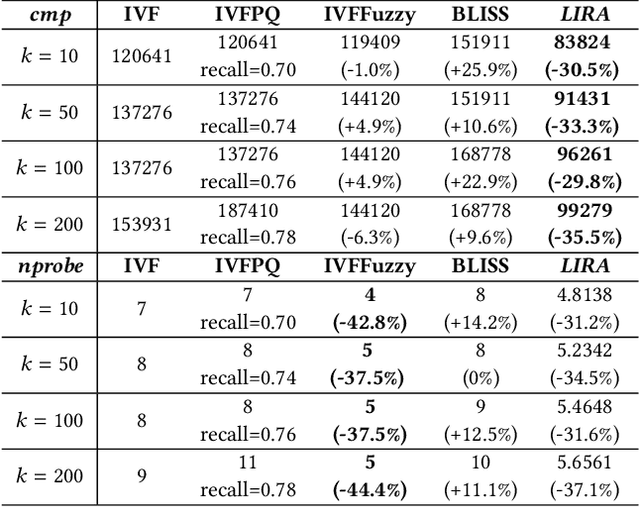
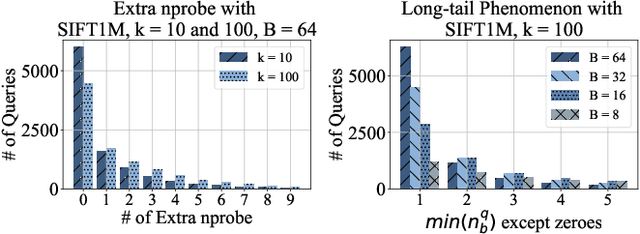
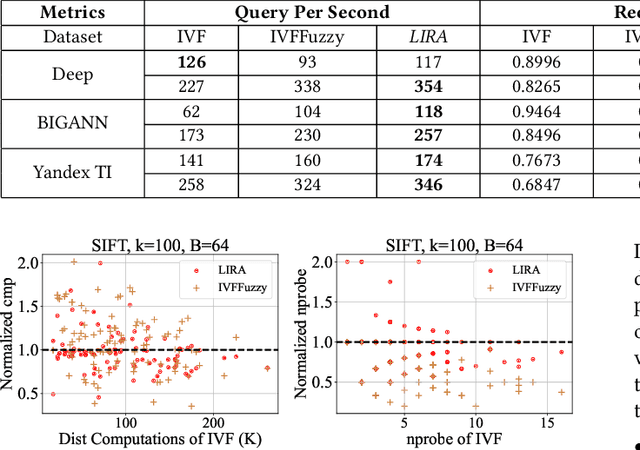
Approximate nearest neighbor search is fundamental in information retrieval. Previous partition-based methods enhance search efficiency by probing partial partitions, yet they face two common issues. In the query phase, a common strategy is to probe partitions based on the distance ranks of a query to partition centroids, which inevitably probes irrelevant partitions as it ignores data distribution. In the partition construction phase, all partition-based methods face the boundary problem that separates a query's nearest neighbors to multiple partitions, resulting in a long-tailed kNN distribution and degrading the optimal nprobe (i.e., the number of probing partitions). To address this gap, we propose LIRA, a LearnIng-based queRy-aware pArtition framework. Specifically, we propose a probing model to directly probe the partitions containing the kNN of a query, which can reduce probing waste and allow for query-aware probing with nprobe individually. Moreover, we incorporate the probing model into a learning-based redundancy strategy to mitigate the adverse impact of the long-tailed kNN distribution on search efficiency. Extensive experiments on real-world vector datasets demonstrate the superiority of LIRA in the trade-off among accuracy, latency, and query fan-out. The codes are available at https://github.com/SimoneZeng/LIRA-ANN-search.
Efficient Large-Scale Traffic Forecasting with Transformers: A Spatial Data Management Perspective
Dec 13, 2024Road traffic forecasting is crucial in real-world intelligent transportation scenarios like traffic dispatching and path planning in city management and personal traveling. Spatio-temporal graph neural networks (STGNNs) stand out as the mainstream solution in this task. Nevertheless, the quadratic complexity of remarkable dynamic spatial modeling-based STGNNs has become the bottleneck over large-scale traffic data. From the spatial data management perspective, we present a novel Transformer framework called PatchSTG to efficiently and dynamically model spatial dependencies for large-scale traffic forecasting with interpretability and fidelity. Specifically, we design a novel irregular spatial patching to reduce the number of points involved in the dynamic calculation of Transformer. The irregular spatial patching first utilizes the leaf K-dimensional tree (KDTree) to recursively partition irregularly distributed traffic points into leaf nodes with a small capacity, and then merges leaf nodes belonging to the same subtree into occupancy-equaled and non-overlapped patches through padding and backtracking. Based on the patched data, depth and breadth attention are used interchangeably in the encoder to dynamically learn local and global spatial knowledge from points in a patch and points with the same index of patches. Experimental results on four real world large-scale traffic datasets show that our PatchSTG achieves train speed and memory utilization improvements up to $10\times$ and $4\times$ with the state-of-the-art performance.
MILLION: A General Multi-Objective Framework with Controllable Risk for Portfolio Management
Dec 04, 2024



Portfolio management is an important yet challenging task in AI for FinTech, which aims to allocate investors' budgets among different assets to balance the risk and return of an investment. In this study, we propose a general Multi-objectIve framework with controLLable rIsk for pOrtfolio maNagement (MILLION), which consists of two main phases, i.e., return-related maximization and risk control. Specifically, in the return-related maximization phase, we introduce two auxiliary objectives, i.e., return rate prediction, and return rate ranking, combined with portfolio optimization to remit the overfitting problem and improve the generalization of the trained model to future markets. Subsequently, in the risk control phase, we propose two methods, i.e., portfolio interpolation and portfolio improvement, to achieve fine-grained risk control and fast risk adaption to a user-specified risk level. For the portfolio interpolation method, we theoretically prove that the risk can be perfectly controlled if the to-be-set risk level is in a proper interval. In addition, we also show that the return rate of the adjusted portfolio after portfolio interpolation is no less than that of the min-variance optimization, as long as the model in the reward maximization phase is effective. Furthermore, the portfolio improvement method can achieve greater return rates while keeping the same risk level compared to portfolio interpolation. Extensive experiments are conducted on three real-world datasets. The results demonstrate the effectiveness and efficiency of the proposed framework.
Efficient Data-aware Distance Comparison Operations for High-Dimensional Approximate Nearest Neighbor Search
Nov 26, 2024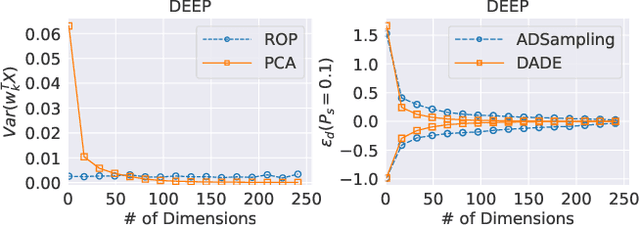
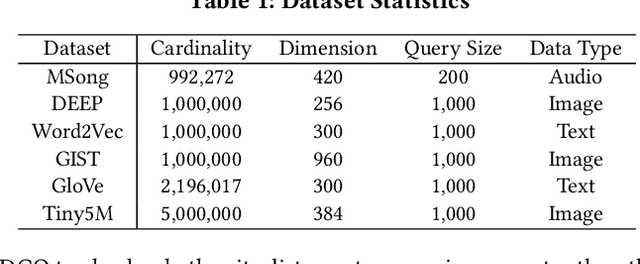
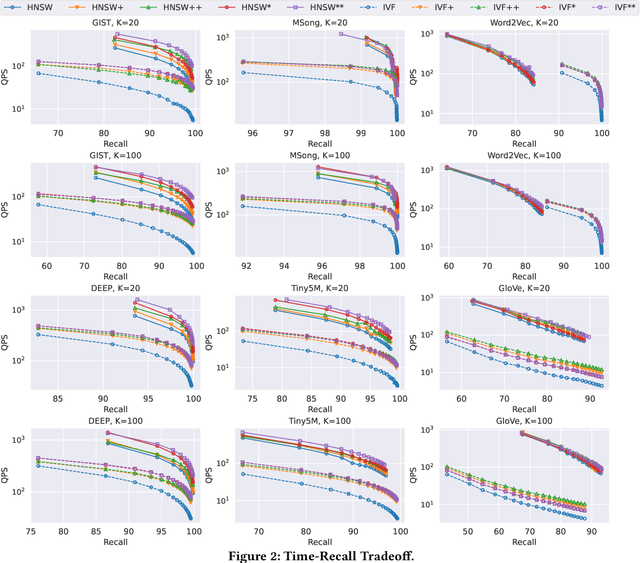
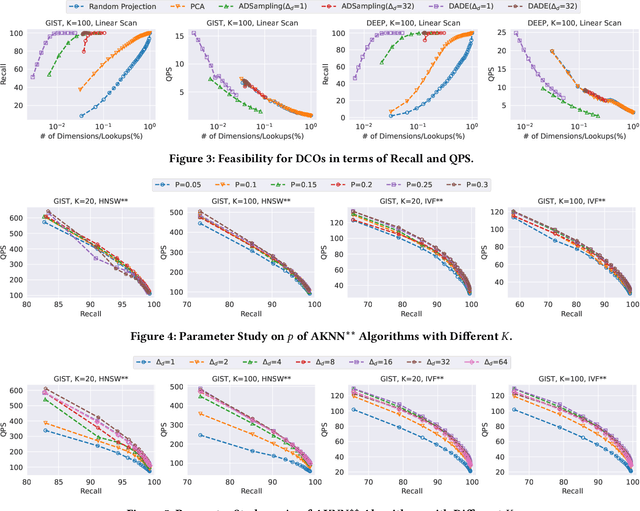
High-dimensional approximate $K$ nearest neighbor search (AKNN) is a fundamental task for various applications, including information retrieval. Most existing algorithms for AKNN can be decomposed into two main components, i.e., candidate generation and distance comparison operations (DCOs). While different methods have unique ways of generating candidates, they all share the same DCO process. In this study, we focus on accelerating the process of DCOs that dominates the time cost in most existing AKNN algorithms. To achieve this, we propose an \underline{D}ata-\underline{A}ware \underline{D}istance \underline{E}stimation approach, called \emph{DADE}, which approximates the \emph{exact} distance in a lower-dimensional space. We theoretically prove that the distance estimation in \emph{DADE} is \emph{unbiased} in terms of data distribution. Furthermore, we propose an optimized estimation based on the unbiased distance estimation formulation. In addition, we propose a hypothesis testing approach to adaptively determine the number of dimensions needed to estimate the \emph{exact} distance with sufficient confidence. We integrate \emph{DADE} into widely-used AKNN search algorithms, e.g., \emph{IVF} and \emph{HNSW}, and conduct extensive experiments to demonstrate the superiority.
D2Vformer: A Flexible Time Series Prediction Model Based on Time Position Embedding
Sep 17, 2024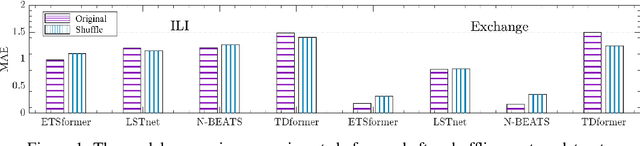
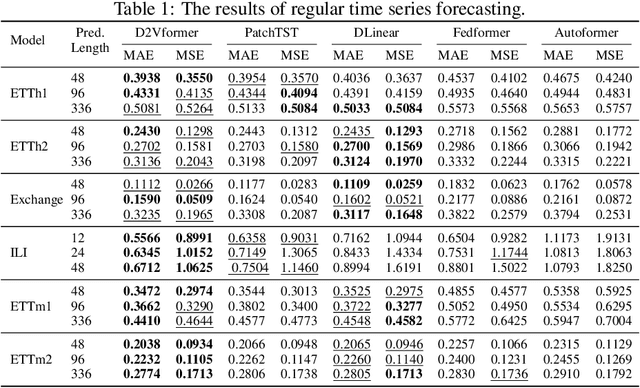

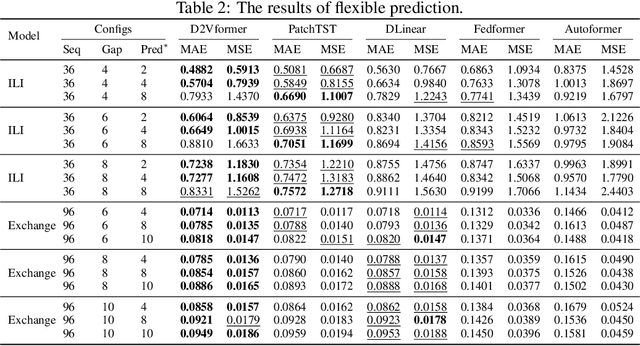
Time position embeddings capture the positional information of time steps, often serving as auxiliary inputs to enhance the predictive capabilities of time series models. However, existing models exhibit limitations in capturing intricate time positional information and effectively utilizing these embeddings. To address these limitations, this paper proposes a novel model called D2Vformer. Unlike typical prediction methods that rely on RNNs or Transformers, this approach can directly handle scenarios where the predicted sequence is not adjacent to the input sequence or where its length dynamically changes. In comparison to conventional methods, D2Vformer undoubtedly saves a significant amount of training resources. In D2Vformer, the Date2Vec module uses the timestamp information and feature sequences to generate time position embeddings. Afterward, D2Vformer introduces a new fusion block that utilizes an attention mechanism to explore the similarity in time positions between the embeddings of the input sequence and the predicted sequence, thereby generating predictions based on this similarity. Through extensive experiments on six datasets, we demonstrate that Date2Vec outperforms other time position embedding methods, and D2Vformer surpasses state-of-the-art methods in both fixed-length and variable-length prediction tasks.
Parameterized Decision-making with Multi-modal Perception for Autonomous Driving
Dec 19, 2023



Autonomous driving is an emerging technology that has advanced rapidly over the last decade. Modern transportation is expected to benefit greatly from a wise decision-making framework of autonomous vehicles, including the improvement of mobility and the minimization of risks and travel time. However, existing methods either ignore the complexity of environments only fitting straight roads, or ignore the impact on surrounding vehicles during optimization phases, leading to weak environmental adaptability and incomplete optimization objectives. To address these limitations, we propose a parameterized decision-making framework with multi-modal perception based on deep reinforcement learning, called AUTO. We conduct a comprehensive perception to capture the state features of various traffic participants around the autonomous vehicle, based on which we design a graph-based model to learn a state representation of the multi-modal semantic features. To distinguish between lane-following and lane-changing, we decompose an action of the autonomous vehicle into a parameterized action structure that first decides whether to change lanes and then computes an exact action to execute. A hybrid reward function takes into account aspects of safety, traffic efficiency, passenger comfort, and impact to guide the framework to generate optimal actions. In addition, we design a regularization term and a multi-worker paradigm to enhance the training. Extensive experiments offer evidence that AUTO can advance state-of-the-art in terms of both macroscopic and microscopic effectiveness.
History Semantic Graph Enhanced Conversational KBQA with Temporal Information Modeling
Jun 12, 2023
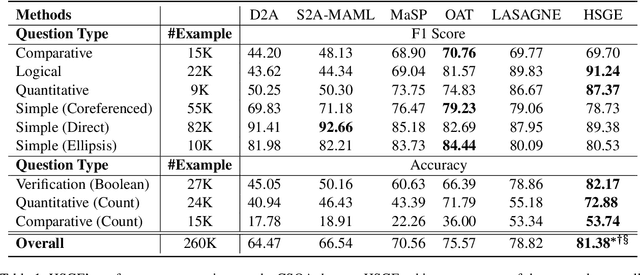
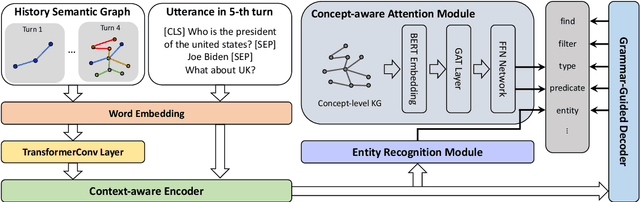
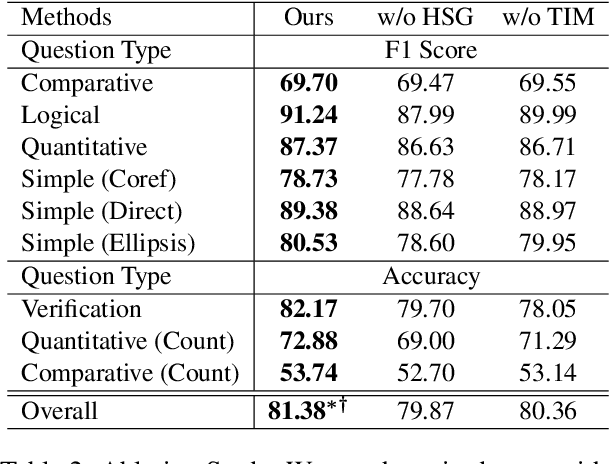
Context information modeling is an important task in conversational KBQA. However, existing methods usually assume the independence of utterances and model them in isolation. In this paper, we propose a History Semantic Graph Enhanced KBQA model (HSGE) that is able to effectively model long-range semantic dependencies in conversation history while maintaining low computational cost. The framework incorporates a context-aware encoder, which employs a dynamic memory decay mechanism and models context at different levels of granularity. We evaluate HSGE on a widely used benchmark dataset for complex sequential question answering. Experimental results demonstrate that it outperforms existing baselines averaged on all question types.
A Comparative Study on Unsupervised Anomaly Detection for Time Series: Experiments and Analysis
Sep 10, 2022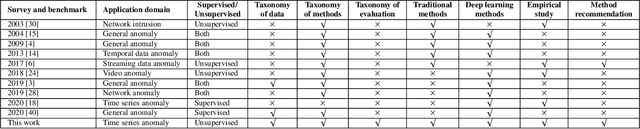
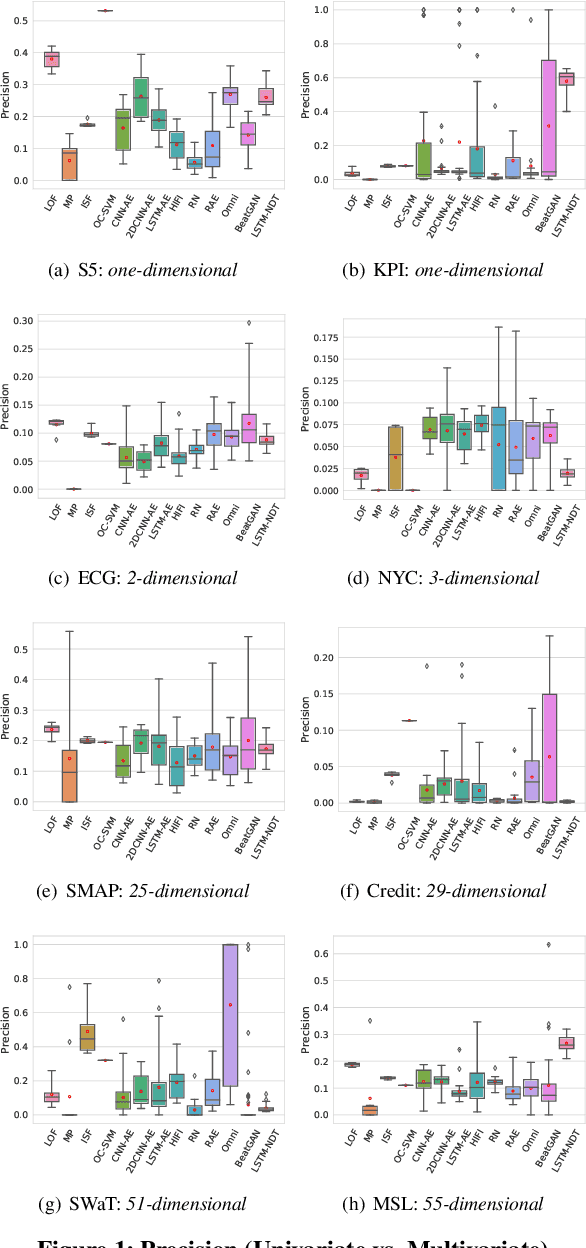
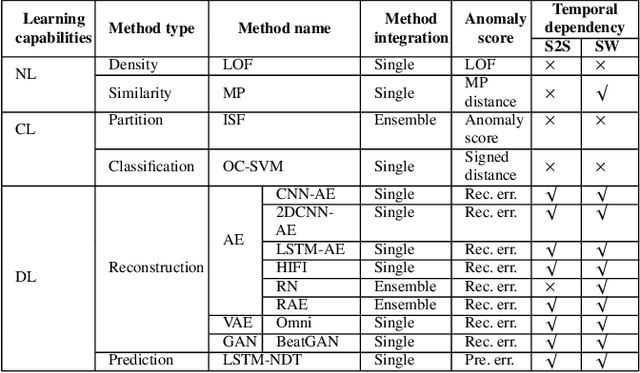

The continued digitization of societal processes translates into a proliferation of time series data that cover applications such as fraud detection, intrusion detection, and energy management, where anomaly detection is often essential to enable reliability and safety. Many recent studies target anomaly detection for time series data. Indeed, area of time series anomaly detection is characterized by diverse data, methods, and evaluation strategies, and comparisons in existing studies consider only part of this diversity, which makes it difficult to select the best method for a particular problem setting. To address this shortcoming, we introduce taxonomies for data, methods, and evaluation strategies, provide a comprehensive overview of unsupervised time series anomaly detection using the taxonomies, and systematically evaluate and compare state-of-the-art traditional as well as deep learning techniques. In the empirical study using nine publicly available datasets, we apply the most commonly-used performance evaluation metrics to typical methods under a fair implementation standard. Based on the structuring offered by the taxonomies, we report on empirical studies and provide guidelines, in the form of comparative tables, for choosing the methods most suitable for particular application settings. Finally, we propose research directions for this dynamic field.
HIFI: Anomaly Detection for Multivariate Time Series with High-order Feature Interactions
Jun 11, 2021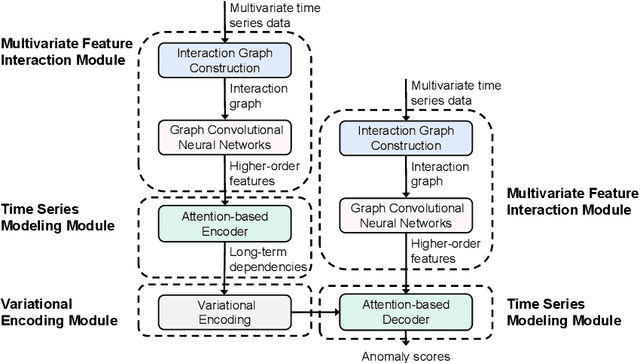
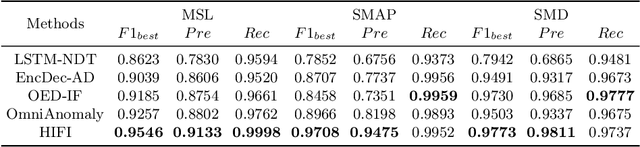
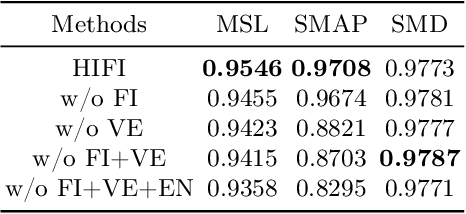
Monitoring complex systems results in massive multivariate time series data, and anomaly detection of these data is very important to maintain the normal operation of the systems. Despite the recent emergence of a large number of anomaly detection algorithms for multivariate time series, most of them ignore the correlation modeling among multivariate, which can often lead to poor anomaly detection results. In this work, we propose a novel anomaly detection model for multivariate time series with \underline{HI}gh-order \underline{F}eature \underline{I}nteractions (HIFI). More specifically, HIFI builds multivariate feature interaction graph automatically and uses the graph convolutional neural network to achieve high-order feature interactions, in which the long-term temporal dependencies are modeled by attention mechanisms and a variational encoding technique is utilized to improve the model performance and robustness. Extensive experiments on three publicly available datasets demonstrate the superiority of our framework compared with state-of-the-art approaches.