 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: A Training-Free Approach for Streaming 3D Reconstruction
Mar 16, 2026Streaming 3D reconstruction demands long-horizon state updates under strict latency constraints, yet stateful recurrent models often suffer from geometric drift as errors accumulate over time. We revisit this problem from a Grassmannian manifold perspective: the latent persistent state can be viewed as a subspace representation, i.e., a point evolving on a Grassmannian manifold, where temporal coherence implies the state trajectory should remain on (or near) this manifold.Based on this view, we propose Self-expressive Sequence Regularization (SSR), a plug-and-play, training-free operator that enforces Grassmannian sequence regularity during inference.Given a window of historical states, SSR computes an analytical affinity matrix via the self-expressive property and uses it to regularize the current update, effectively pulling noisy predictions back toward the manifold-consistent trajectory with minimal overhead. Experiments on long-sequence benchmarks demonstrate that SSR consistently reduces drift and improves reconstruction quality across multiple streaming 3D reconstruction tasks.
CauCLIP: Bridging the Sim-to-Real Gap in Surgical Video Understanding via Causality-Inspired Vision-Language Modeling
Feb 06, 2026Surgical phase recognition is a critical component for context-aware decision support in intelligent operating rooms, yet training robust models is hindered by limited annotated clinical videos and large domain gaps between synthetic and real surgical data. To address this, we propose CauCLIP, a causality-inspired vision-language framework that leverages CLIP to learn domain-invariant representations for surgical phase recognition without access to target domain data. Our approach integrates a frequency-based augmentation strategy to perturb domain-specific attributes while preserving semantic structures, and a causal suppression loss that mitigates non-causal biases and reinforces causal surgical features. These components are combined in a unified training framework that enables the model to focus on stable causal factors underlying surgical workflows. Experiments on the SurgVisDom hard adaptation benchmark demonstrate that our method substantially outperforms all competing approaches, highlighting the effectiveness of causality-guided vision-language models for domain-generalizable surgical video understanding.
Towards Exploratory and Focused Manipulation with Bimanual Active Perception: A New Problem, Benchmark and Strategy
Feb 02, 2026Recently, active vision has reemerged as an important concept for manipulation, since visual occlusion occurs more frequently when main cameras are mounted on the robot heads. We reflect on the visual occlusion issue and identify its essence as the absence of information useful for task completion. Inspired by this, we come up with the more fundamental problem of Exploratory and Focused Manipulation (EFM). The proposed problem is about actively collecting information to complete challenging manipulation tasks that require exploration or focus. As an initial attempt to address this problem, we establish the EFM-10 benchmark that consists of 4 categories of tasks that align with our definition (10 tasks in total). We further come up with a Bimanual Active Perception (BAP) strategy, which leverages one arm to provide active vision and another arm to provide force sensing while manipulating. Based on this idea, we collect a dataset named BAPData for the tasks in EFM-10. With the dataset, we successfully verify the effectiveness of the BAP strategy in an imitation learning manner. We hope that the EFM-10 benchmark along with the BAP strategy can become a cornerstone that facilitates future research towards this direction. Project website: EFManipulation.github.io.
RoboAct-CLIP: Video-Driven Pre-training of Atomic Action Understanding for Robotics
Apr 02, 2025Visual Language Models (VLMs) have emerged as pivotal tools for robotic systems, enabling cross-task generalization, dynamic environmental interaction, and long-horizon planning through multimodal perception and semantic reasoning. However, existing open-source VLMs predominantly trained for generic vision-language alignment tasks fail to model temporally correlated action semantics that are crucial for robotic manipulation effectively. While current image-based fine-tuning methods partially adapt VLMs to robotic applications, they fundamentally disregard temporal evolution patterns in video sequences and suffer from visual feature entanglement between robotic agents, manipulated objects, and environmental contexts, thereby limiting semantic decoupling capability for atomic actions and compromising model generalizability.To overcome these challenges, this work presents RoboAct-CLIP with dual technical contributions: 1) A dataset reconstruction framework that performs semantic-constrained action unit segmentation and re-annotation on open-source robotic videos, constructing purified training sets containing singular atomic actions (e.g., "grasp"); 2) A temporal-decoupling fine-tuning strategy based on Contrastive Language-Image Pretraining (CLIP) architecture, which disentangles temporal action features across video frames from object-centric characteristics to achieve hierarchical representation learning of robotic atomic actions.Experimental results in simulated environments demonstrate that the RoboAct-CLIP pretrained model achieves a 12% higher success rate than baseline VLMs, along with superior generalization in multi-object manipulation tasks.
A Prompt Refinement-based Large Language Model for Metro Passenger Flow Forecasting under Delay Conditions
Oct 19, 2024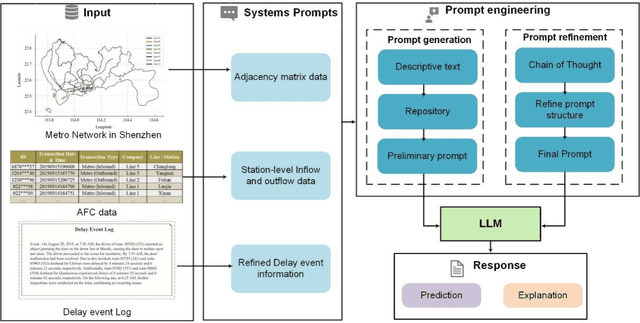
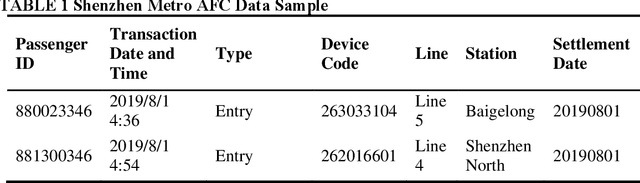
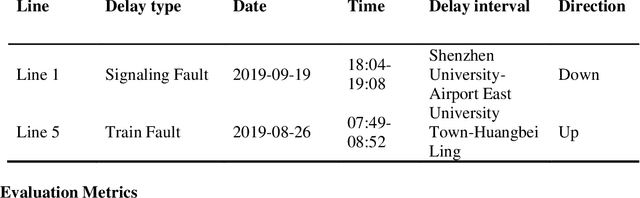
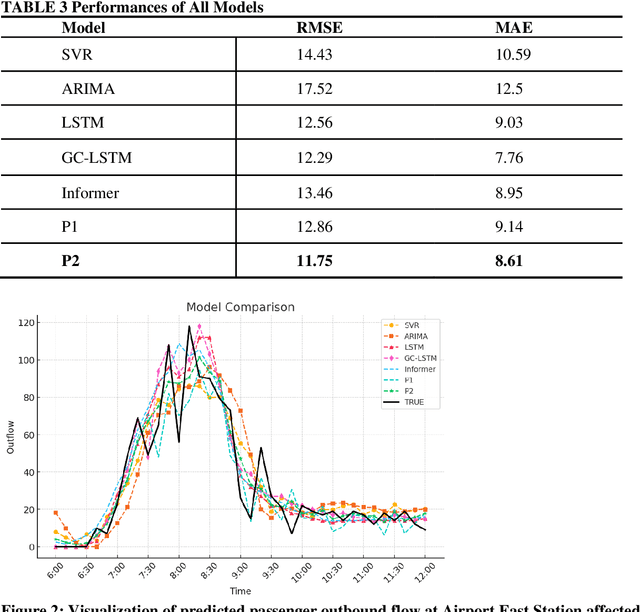
Accurate short-term forecasts of passenger flow in metro systems under delay conditions are crucial for emergency response and service recovery, which pose significant challenges and are currently under-researched. Due to the rare occurrence of delay events, the limited sample size under delay condictions make it difficult for conventional models to effectively capture the complex impacts of delays on passenger flow, resulting in low forecasting accuracy. Recognizing the strengths of large language models (LLMs) in few-shot learning due to their powerful pre-training, contextual understanding, ability to perform zero-shot and few-shot reasoning, to address the issues that effectively generalize and adapt with minimal data, we propose a passenger flow forecasting framework under delay conditions that synthesizes an LLM with carefully designed prompt engineering. By Refining prompt design, we enable the LLM to understand delay event information and the pattern from historical passenger flow data, thus overcoming the challenges of passenger flow forecasting under delay conditions. The propmpt engineering in the framework consists of two main stages: systematic prompt generation and prompt refinement. In the prompt generation stage, multi-source data is transformed into descriptive texts understandable by the LLM and stored. In the prompt refinement stage, we employ the multidimensional Chain of Thought (CoT) method to refine the prompts. We verify the proposed framework by conducting experiments using real-world datasets specifically targeting passenger flow forecasting under delay conditions of Shenzhen metro in China. The experimental results demonstrate that the proposed model performs particularly well in forecasting passenger flow under delay conditions.
D2Vformer: A Flexible Time Series Prediction Model Based on Time Position Embedding
Sep 17, 2024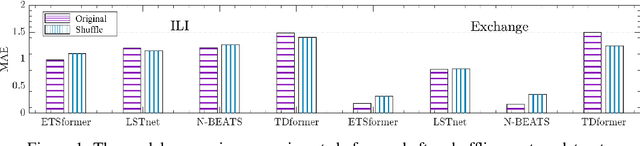
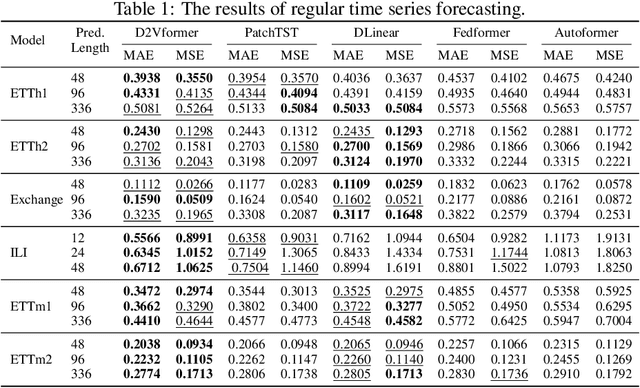

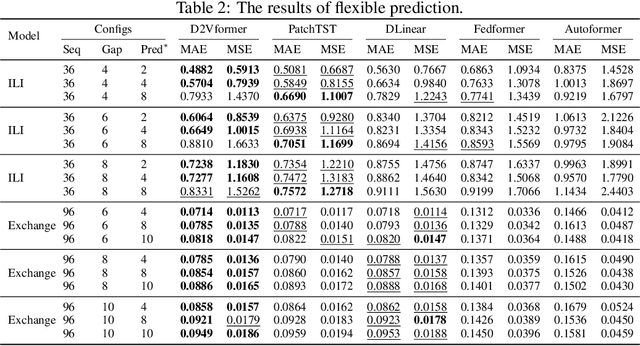
Time position embeddings capture the positional information of time steps, often serving as auxiliary inputs to enhance the predictive capabilities of time series models. However, existing models exhibit limitations in capturing intricate time positional information and effectively utilizing these embeddings. To address these limitations, this paper proposes a novel model called D2Vformer. Unlike typical prediction methods that rely on RNNs or Transformers, this approach can directly handle scenarios where the predicted sequence is not adjacent to the input sequence or where its length dynamically changes. In comparison to conventional methods, D2Vformer undoubtedly saves a significant amount of training resources. In D2Vformer, the Date2Vec module uses the timestamp information and feature sequences to generate time position embeddings. Afterward, D2Vformer introduces a new fusion block that utilizes an attention mechanism to explore the similarity in time positions between the embeddings of the input sequence and the predicted sequence, thereby generating predictions based on this similarity. Through extensive experiments on six datasets, we demonstrate that Date2Vec outperforms other time position embedding methods, and D2Vformer surpasses state-of-the-art methods in both fixed-length and variable-length prediction tasks.
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024



Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
Explorers at #SMM4H 2023: Enhancing BERT for Health Applications through Knowledge and Model Fusion
Dec 17, 2023An increasing number of individuals are willing to post states and opinions in social media, which has become a valuable data resource for studying human health. Furthermore, social media has been a crucial research point for healthcare now. This paper outlines the methods in our participation in the #SMM4H 2023 Shared Tasks, including data preprocessing, continual pre-training and fine-tuned optimization strategies. Especially for the Named Entity Recognition (NER) task, we utilize the model architecture named W2NER that effectively enhances the model generalization ability. Our method achieved first place in the Task 3. This paper has been peer-reviewed and accepted for presentation at the #SMM4H 2023 Workshop.
Revisiting Event Argument Extraction: Can EAE Models Learn Better When Being Aware of Event Co-occurrences?
Jun 01, 2023
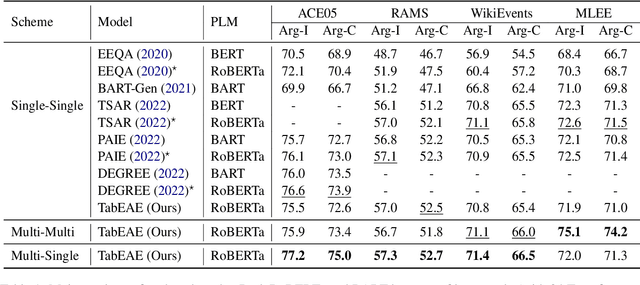
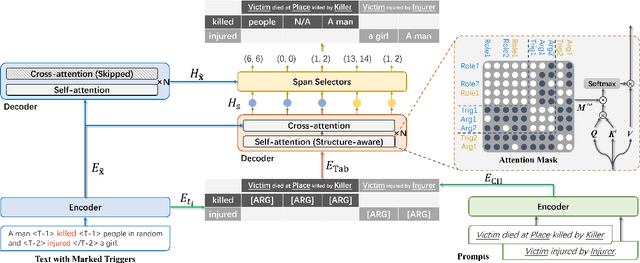
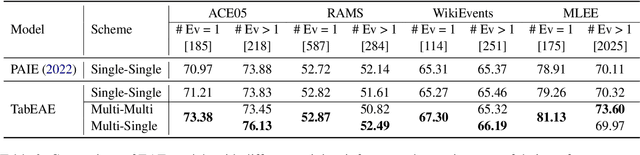
Event co-occurrences have been proved effective for event extraction (EE) in previous studies, but have not been considered for event argument extraction (EAE) recently. In this paper, we try to fill this gap between EE research and EAE research, by highlighting the question that ``Can EAE models learn better when being aware of event co-occurrences?''. To answer this question, we reformulate EAE as a problem of table generation and extend a SOTA prompt-based EAE model into a non-autoregressive generation framework, called TabEAE, which is able to extract the arguments of multiple events in parallel. Under this framework, we experiment with 3 different training-inference schemes on 4 datasets (ACE05, RAMS, WikiEvents and MLEE) and discover that via training the model to extract all events in parallel, it can better distinguish the semantic boundary of each event and its ability to extract single event gets substantially improved. Experimental results show that our method achieves new state-of-the-art performance on the 4 datasets. Our code is avilable at https://github.com/Stardust-hyx/TabEAE.
Contrastive Learning with Hard Negative Entities for Entity Set Expansion
Apr 25, 2022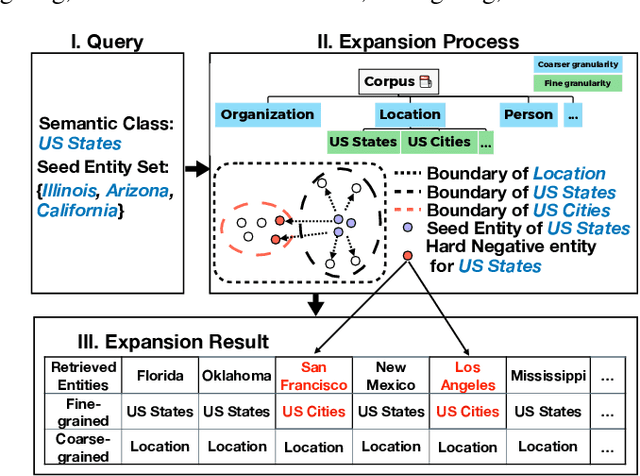
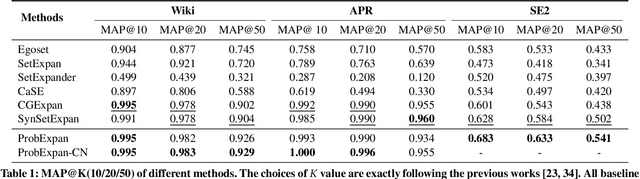
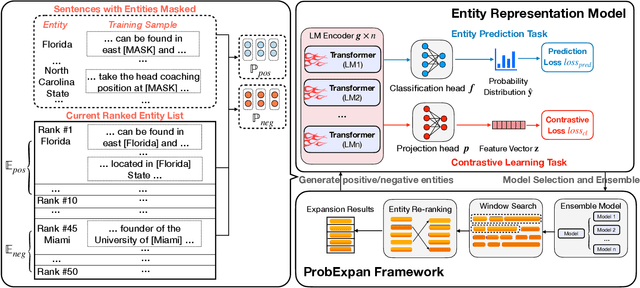
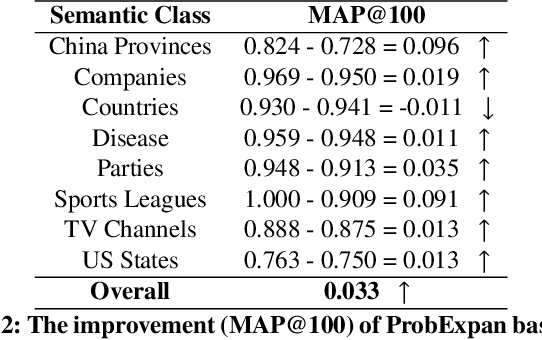
Entity Set Expansion (ESE) is a promising task which aims to expand entities of the target semantic class described by a small seed entity set. Various NLP and IR applications will benefit from ESE due to its ability to discover knowledge. Although previous ESE methods have achieved great progress, most of them still lack the ability to handle hard negative entities (i.e., entities that are difficult to distinguish from the target entities), since two entities may or may not belong to the same semantic class based on different granularity levels we analyze on. To address this challenge, we devise an entity-level masked language model with contrastive learning to refine the representation of entities. In addition, we propose the ProbExpan, a novel probabilistic ESE framework utilizing the entity representation obtained by the aforementioned language model to expand entities. Extensive experiments and detailed analyses on three datasets show that our method outperforms previous state-of-the-art methods.