 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Mental Modeling from Limited Views
Jun 26, 2025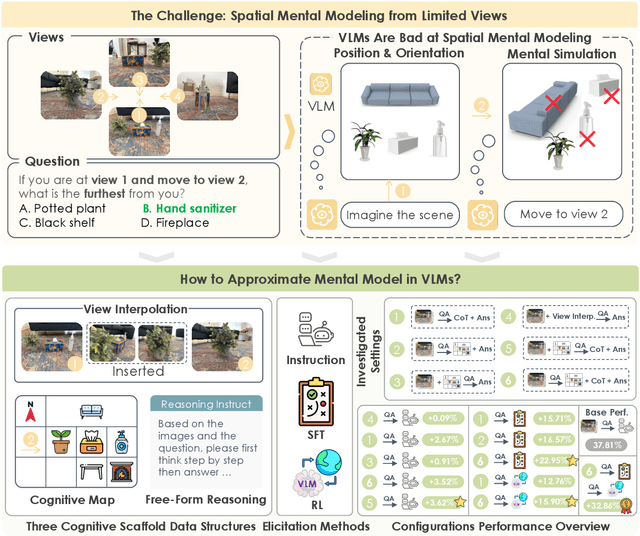

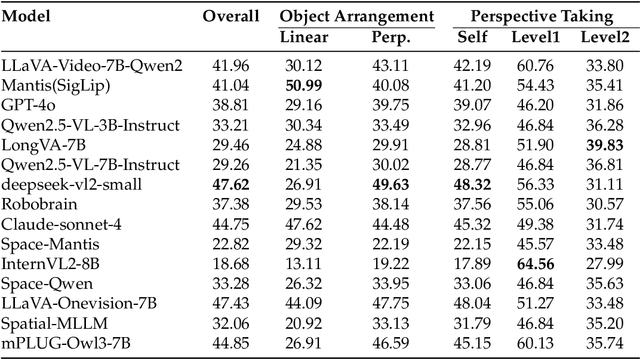
Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation
Jun 03, 2024As cutting-edge Text-to-Image (T2I) generation models already excel at producing remarkable single images, an even more challenging task, i.e., multi-turn interactive image generation begins to attract the attention of related research communities. This task requires models to interact with users over multiple turns to generate a coherent sequence of images. However, since users may switch subjects frequently, current efforts struggle to maintain subject consistency while generating diverse images. To address this issue, we introduce a training-free multi-agent framework called AutoStudio. AutoStudio employs three agents based on large language models (LLMs) to handle interactions, along with a stable diffusion (SD) based agent for generating high-quality images. Specifically, AutoStudio consists of (i) a subject manager to interpret interaction dialogues and manage the context of each subject, (ii) a layout generator to generate fine-grained bounding boxes to control subject locations, (iii) a supervisor to provide suggestions for layout refinements, and (iv) a drawer to complete image generation. Furthermore, we introduce a Parallel-UNet to replace the original UNet in the drawer, which employs two parallel cross-attention modules for exploiting subject-aware features. We also introduce a subject-initialized generation method to better preserve small subjects. Our AutoStudio hereby can generate a sequence of multi-subject images interactively and consistently. Extensive experiments on the public CMIGBench benchmark and human evaluations show that AutoStudio maintains multi-subject consistency across multiple turns well, and it also raises the state-of-the-art performance by 13.65% in average Frechet Inception Distance and 2.83% in average character-character similarity.
SemiPL: A Semi-supervised Method for Event Sound Source Localization
Apr 30, 2024



In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024



Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
HDBN: A Novel Hybrid Dual-branch Network for Robust Skeleton-based Action Recognition
Apr 25, 2024



Skeleton-based action recognition has gained considerable traction thanks to its utilization of succinct and robust skeletal representations. Nonetheless, current methodologies often lean towards utilizing a solitary backbone to model skeleton modality, which can be limited by inherent flaws in the network backbone. To address this and fully leverage the complementary characteristics of various network architectures, we propose a novel Hybrid Dual-Branch Network (HDBN) for robust skeleton-based action recognition, which benefits from the graph convolutional network's proficiency in handling graph-structured data and the powerful modeling capabilities of Transformers for global information. In detail, our proposed HDBN is divided into two trunk branches: MixGCN and MixFormer. The two branches utilize GCNs and Transformers to model both 2D and 3D skeletal modalities respectively. Our proposed HDBN emerged as one of the top solutions in the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) of 2024 ICME Grand Challenge, achieving accuracies of 47.95% and 75.36% on two benchmarks of the UAV-Human dataset by outperforming most existing methods. Our code will be publicly available at: https://github.com/liujf69/ICMEW2024-Track10.
SFMViT: SlowFast Meet ViT in Chaotic World
Apr 25, 2024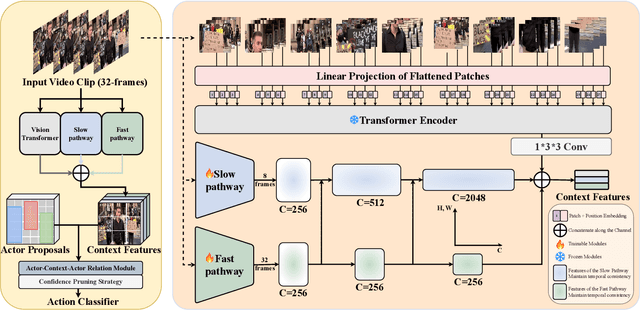
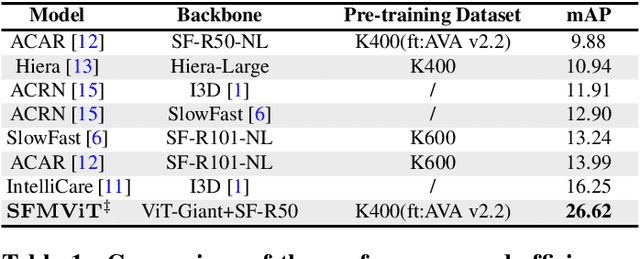
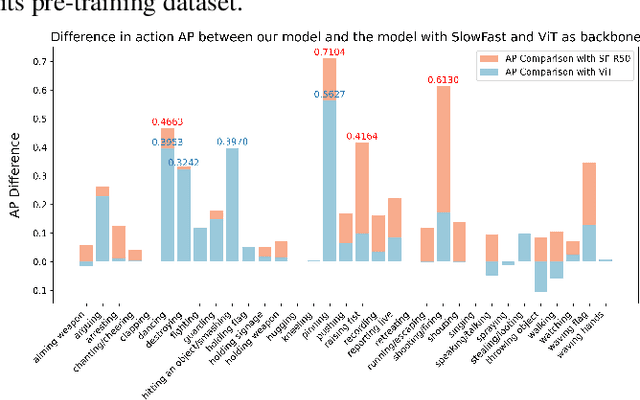

The task of spatiotemporal action localization in chaotic scenes is a challenging task toward advanced video understanding. Paving the way with high-quality video feature extraction and enhancing the precision of detector-predicted anchors can effectively improve model performance. To this end, we propose a high-performance dual-stream spatiotemporal feature extraction network SFMViT with an anchor pruning strategy. The backbone of our SFMViT is composed of ViT and SlowFast with prior knowledge of spatiotemporal action localization, which fully utilizes ViT's excellent global feature extraction capabilities and SlowFast's spatiotemporal sequence modeling capabilities. Secondly, we introduce the confidence maximum heap to prune the anchors detected in each frame of the picture to filter out the effective anchors. These designs enable our SFMViT to achieve a mAP of 26.62% in the Chaotic World dataset, far exceeding existing models. Code is available at https://github.com/jfightyr/SlowFast-Meet-ViT.
Using Adamic-Adar Index Algorithm to Predict Volunteer Collaboration: Less is More
Aug 25, 2023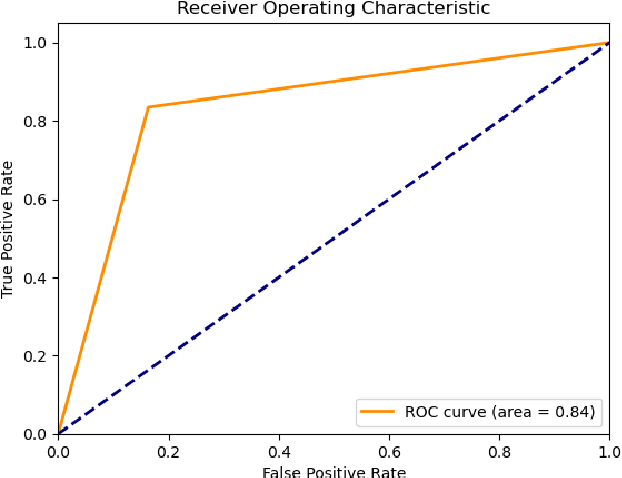
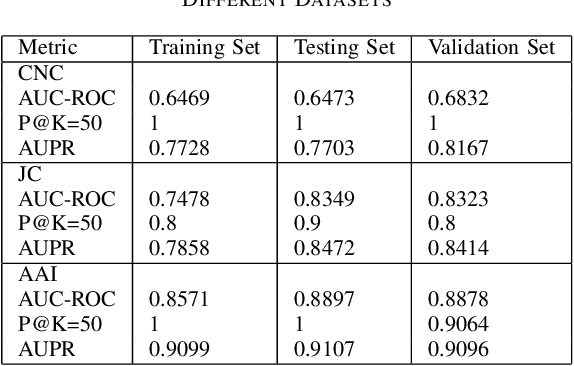
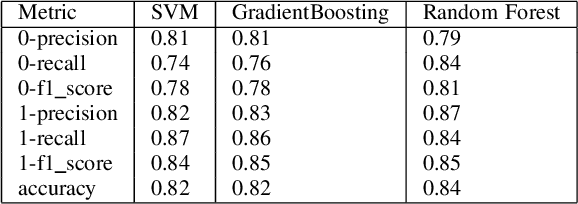
Social networks exhibit a complex graph-like structure due to the uncertainty surrounding potential collaborations among participants. Machine learning algorithms possess generic outstanding performance in multiple real-world prediction tasks. However, whether machine learning algorithms outperform specific algorithms designed for graph link prediction remains unknown to us. To address this issue, the Adamic-Adar Index (AAI), Jaccard Coefficient (JC) and common neighbour centrality (CNC) as representatives of graph-specific algorithms were applied to predict potential collaborations, utilizing data from volunteer activities during the Covid-19 pandemic in Shenzhen city, along with the classical machine learning algorithms such as random forest, support vector machine, and gradient boosting as single predictors and components of ensemble learning. This paper introduces that the AAI algorithm outperformed the traditional JC and CNC, and other machine learning algorithms in analyzing graph node attributes for this task.