 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Chebyshev Polynomial Neural Operator for Parametric Partial Differential Equations
Feb 02, 2026Neural operators have emerged as powerful deep learning frameworks for approximating solution operators of parameterized partial differential equations (PDE). However, current methods predominantly rely on multilayer perceptrons (MLPs) for mapping inputs to solutions, which impairs training robustness in physics-informed settings due to inherent spectral biases and fixed activation functions. To overcome the architectural limitations, we introduce the Physics-Informed Chebyshev Polynomial Neural Operator (CPNO), a novel mesh-free framework that leverages a basis transformation to replace unstable monomial expansions with the numerically stable Chebyshev spectral basis. By integrating parameter dependent modulation mechanism to main net, CPNO constructs PDE solutions in a near-optimal functional space, decoupling the model from MLP-specific constraints and enhancing multi-scale representation. Theoretical analysis demonstrates the Chebyshev basis's near-minimax uniform approximation properties and superior conditioning, with Lebesgue constants growing logarithmically with degree, thereby mitigating spectral bias and ensuring stable gradient flow during optimization. Numerical experiments on benchmark parameterized PDEs show that CPNO achieves superior accuracy, faster convergence, and enhanced robustness to hyperparameters. The experiment of transonic airfoil flow has demonstrated the capability of CPNO in characterizing complex geometric problems.
Spatial Mental Modeling from Limited Views
Jun 26, 2025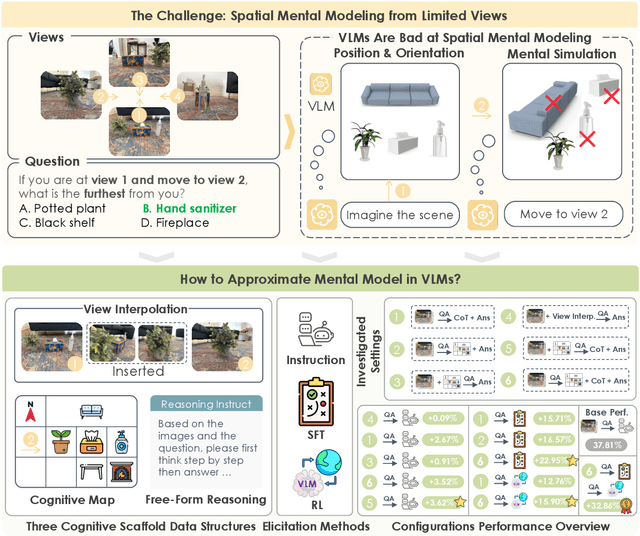

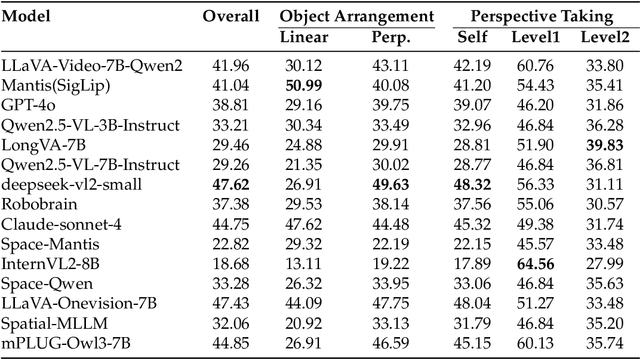
Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Apr 24, 2025Training large language models (LLMs) as interactive agents presents unique challenges including long-horizon decision making and interacting with stochastic environment feedback. While reinforcement learning (RL) has enabled progress in static tasks, multi-turn agent RL training remains underexplored. We propose StarPO (State-Thinking-Actions-Reward Policy Optimization), a general framework for trajectory-level agent RL, and introduce RAGEN, a modular system for training and evaluating LLM agents. Our study on three stylized environments reveals three core findings. First, our agent RL training shows a recurring mode of Echo Trap where reward variance cliffs and gradient spikes; we address this with StarPO-S, a stabilized variant with trajectory filtering, critic incorporation, and decoupled clipping. Second, we find the shaping of RL rollouts would benefit from diverse initial states, medium interaction granularity and more frequent sampling. Third, we show that without fine-grained, reasoning-aware reward signals, agent reasoning hardly emerge through multi-turn RL and they may show shallow strategies or hallucinated thoughts. Code and environments are available at https://github.com/RAGEN-AI/RAGEN.
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents
Feb 13, 2025



Leveraging Multi-modal Large Language Models (MLLMs) to create embodied agents offers a promising avenue for tackling real-world tasks. While language-centric embodied agents have garnered substantial attention, MLLM-based embodied agents remain underexplored due to the lack of comprehensive evaluation frameworks. To bridge this gap, we introduce EmbodiedBench, an extensive benchmark designed to evaluate vision-driven embodied agents. EmbodiedBench features: (1) a diverse set of 1,128 testing tasks across four environments, ranging from high-level semantic tasks (e.g., household) to low-level tasks involving atomic actions (e.g., navigation and manipulation); and (2) six meticulously curated subsets evaluating essential agent capabilities like commonsense reasoning, complex instruction understanding, spatial awareness, visual perception, and long-term planning. Through extensive experiments, we evaluated 13 leading proprietary and open-source MLLMs within EmbodiedBench. Our findings reveal that: MLLMs excel at high-level tasks but struggle with low-level manipulation, with the best model, GPT-4o, scoring only 28.9% on average. EmbodiedBench provides a multifaceted standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance MLLM-based embodied agents. Our code is available at https://embodiedbench.github.io.
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
Oct 09, 2024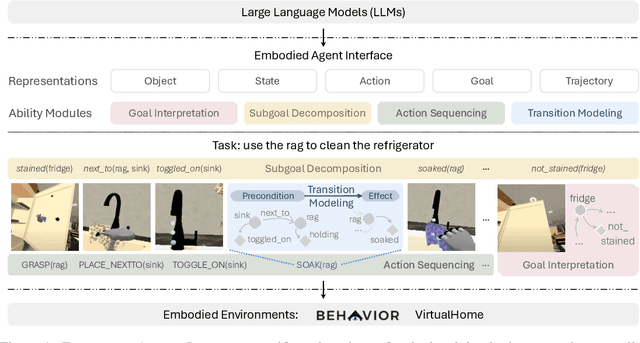

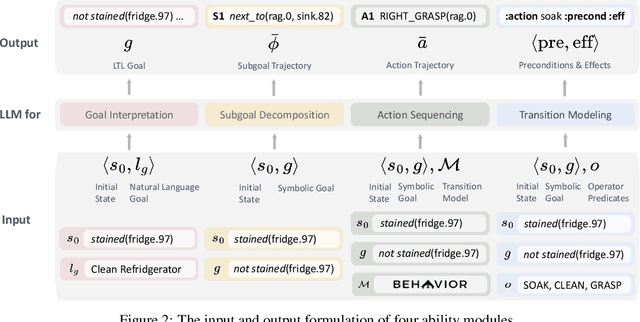
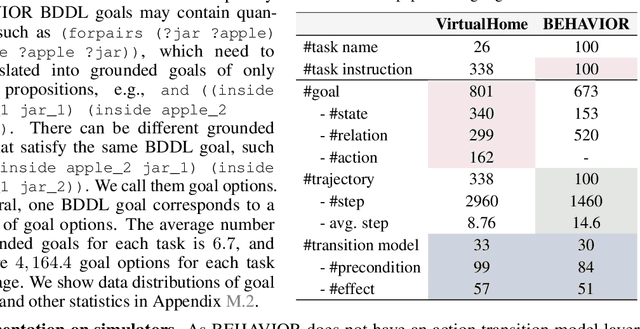
We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics which break down evaluation into various types of errors, such as hallucination errors, affordance errors, various types of planning errors, etc. Overall, our benchmark offers a comprehensive assessment of LLMs' performance for different subtasks, pinpointing the strengths and weaknesses in LLM-powered embodied AI systems, and providing insights for effective and selective use of LLMs in embodied decision making.
Rethinking the Bounds of LLM Reasoning: Are Multi-Agent Discussions the Key?
Feb 28, 2024Recent progress in LLMs discussion suggests that multi-agent discussion improves the reasoning abilities of LLMs. In this work, we reevaluate this claim through systematic experiments, where we propose a novel group discussion framework to enrich the set of discussion mechanisms. Interestingly, our results show that a single-agent LLM with strong prompts can achieve almost the same performance as the best existing discussion approach on a wide range of reasoning tasks and backbone LLMs. We observe that the multi-agent discussion performs better than a single agent only when there is no demonstration in the prompt. Further study reveals the common interaction mechanisms of LLMs during the discussion.
Lens: A Foundation Model for Network Traffic in Cybersecurity
Feb 09, 2024Network traffic refers to the amount of data being sent and received over the internet or any system that connects computers. Analyzing and understanding network traffic is vital for improving network security and management. However, the analysis of network traffic is challenging due to the diverse nature of data packets, which often feature heterogeneous headers and encrypted payloads lacking semantics. To capture the latent semantics of traffic, a few studies have adopted pre-training techniques based on the Transformer encoder or decoder to learn the representations from massive traffic data. However, these methods typically excel in traffic understanding (classification) or traffic generation tasks. To address this issue, we develop Lens, a foundation model for network traffic that leverages the T5 architecture to learn the pre-trained representations from large-scale unlabeled data. Harnessing the strength of the encoder-decoder framework, which captures the global information while preserving the generative ability, our model can better learn the representations from raw data. To further enhance pre-training effectiveness, we design a novel loss that combines three distinct tasks: Masked Span Prediction (MSP), Packet Order Prediction (POP), and Homologous Traffic Prediction (HTP). Evaluation results across various benchmark datasets demonstrate that the proposed Lens outperforms the baselines in most downstream tasks related to both traffic understanding and generation. Notably, it also requires much less labeled data for fine-tuning compared to current methods.
On the Discussion of Large Language Models: Symmetry of Agents and Interplay with Prompts
Nov 13, 2023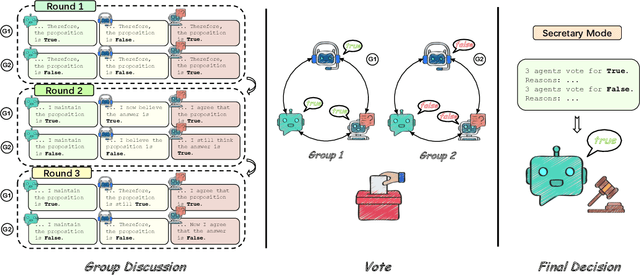

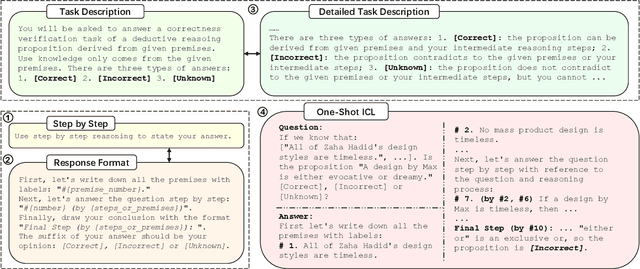
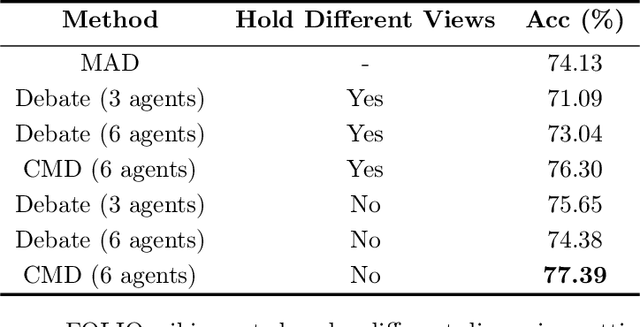
Two ways has been discussed to unlock the reasoning capability of a large language model. The first one is prompt engineering and the second one is to combine the multiple inferences of large language models, or the multi-agent discussion. Theoretically, this paper justifies the multi-agent discussion mechanisms from the symmetry of agents. Empirically, this paper reports the empirical results of the interplay of prompts and discussion mechanisms, revealing the empirical state-of-the-art performance of complex multi-agent mechanisms can be approached by carefully developed prompt engineering. This paper also proposes a scalable discussion mechanism based on conquer and merge, providing a simple multi-agent discussion solution with simple prompts but state-of-the-art performance.