 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?
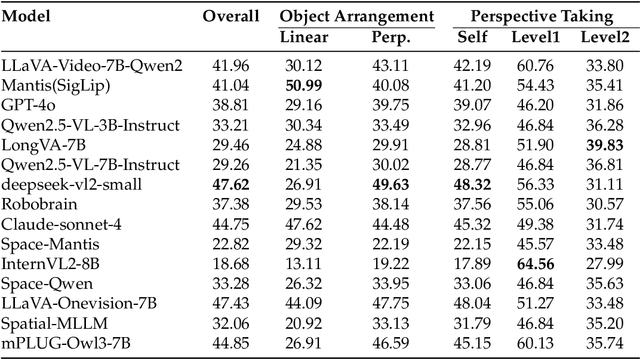
Feb 04, 2026Spatial embodied intelligence requires agents to act to acquire information under partial observability. While multimodal foundation models excel at passive perception, their capacity for active, self-directed exploration remains understudied. We propose Theory of Space, defined as an agent's ability to actively acquire information through self-directed, active exploration and to construct, revise, and exploit a spatial belief from sequential, partial observations. We evaluate this through a benchmark where the goal is curiosity-driven exploration to build an accurate cognitive map. A key innovation is spatial belief probing, which prompts models to reveal their internal spatial representations at each step. Our evaluation of state-of-the-art models reveals several critical bottlenecks. First, we identify an Active-Passive Gap, where performance drops significantly when agents must autonomously gather information. Second, we find high inefficiency, as models explore unsystematically compared to program-based proxies. Through belief probing, we diagnose that while perception is an initial bottleneck, global beliefs suffer from instability that causes spatial knowledge to degrade over time. Finally, using a false belief paradigm, we uncover Belief Inertia, where agents fail to update obsolete priors with new evidence. This issue is present in text-based agents but is particularly severe in vision-based models. Our findings suggest that current foundation models struggle to maintain coherent, revisable spatial beliefs during active exploration.
Spatial Mental Modeling from Limited Views
Jun 26, 2025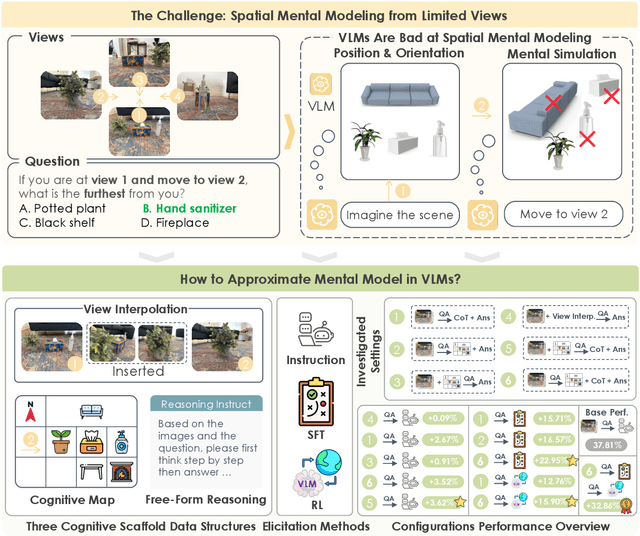

Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Apr 24, 2025Training large language models (LLMs) as interactive agents presents unique challenges including long-horizon decision making and interacting with stochastic environment feedback. While reinforcement learning (RL) has enabled progress in static tasks, multi-turn agent RL training remains underexplored. We propose StarPO (State-Thinking-Actions-Reward Policy Optimization), a general framework for trajectory-level agent RL, and introduce RAGEN, a modular system for training and evaluating LLM agents. Our study on three stylized environments reveals three core findings. First, our agent RL training shows a recurring mode of Echo Trap where reward variance cliffs and gradient spikes; we address this with StarPO-S, a stabilized variant with trajectory filtering, critic incorporation, and decoupled clipping. Second, we find the shaping of RL rollouts would benefit from diverse initial states, medium interaction granularity and more frequent sampling. Third, we show that without fine-grained, reasoning-aware reward signals, agent reasoning hardly emerge through multi-turn RL and they may show shallow strategies or hallucinated thoughts. Code and environments are available at https://github.com/RAGEN-AI/RAGEN.
Enhancing Zero-shot Audio Classification using Sound Attribute Knowledge from Large Language Models
Jul 19, 2024


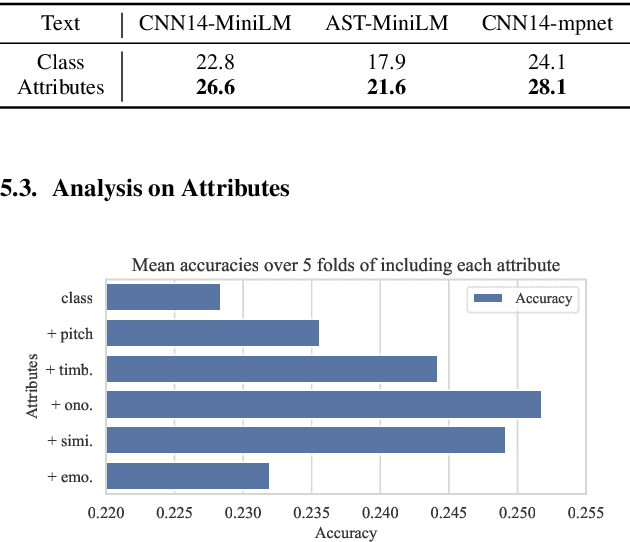
Zero-shot audio classification aims to recognize and classify a sound class that the model has never seen during training. This paper presents a novel approach for zero-shot audio classification using automatically generated sound attribute descriptions. We propose a list of sound attributes and leverage large language model's domain knowledge to generate detailed attribute descriptions for each class. In contrast to previous works that primarily relied on class labels or simple descriptions, our method focuses on multi-dimensional innate auditory attributes, capturing different characteristics of sound classes. Additionally, we incorporate a contrastive learning approach to enhance zero-shot learning from textual labels. We validate the effectiveness of our method on VGGSound and AudioSet\footnote{The code is available at \url{https://www.github.com/wsntxxn/AttrEnhZsAc}.}. Our results demonstrate a substantial improvement in zero-shot classification accuracy. Ablation results show robust performance enhancement, regardless of the model architecture.
A Detailed Audio-Text Data Simulation Pipeline using Single-Event Sounds
Mar 07, 2024



Recently, there has been an increasing focus on audio-text cross-modal learning. However, most of the existing audio-text datasets contain only simple descriptions of sound events. Compared with classification labels, the advantages of such descriptions are significantly limited. In this paper, we first analyze the detailed information that human descriptions of audio may contain beyond sound event labels. Based on the analysis, we propose an automatic pipeline for curating audio-text pairs with rich details. Leveraging the property that sounds can be mixed and concatenated in the time domain, we control details in four aspects: temporal relationship, loudness, speaker identity, and occurrence number, in simulating audio mixtures. Corresponding details are transformed into captions by large language models. Audio-text pairs with rich details in text descriptions are thereby obtained. We validate the effectiveness of our pipeline with a small amount of simulated data, demonstrating that the simulated data enables models to learn detailed audio captioning.
BLAT: Bootstrapping Language-Audio Pre-training based on AudioSet Tag-guided Synthetic Data
Mar 14, 2023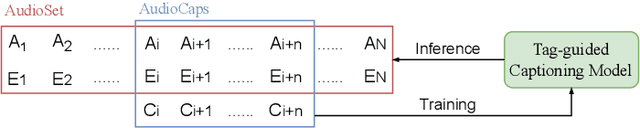
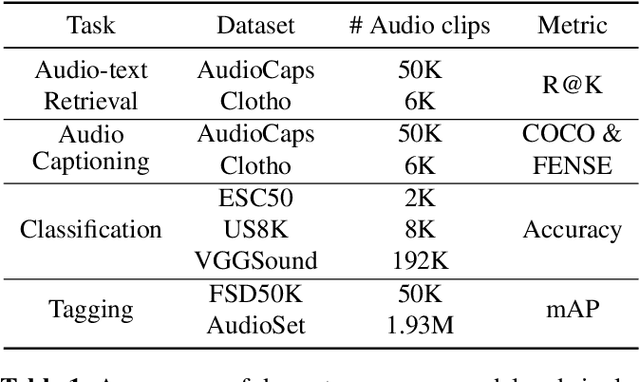
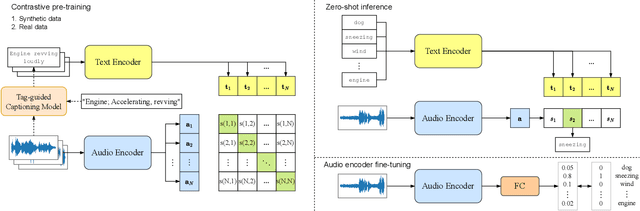

Compared with ample visual-text pre-training research, few works explore audio-text pre-training, mostly due to the lack of sufficient parallel audio-text data. Most existing methods incorporate the visual modality as a pivot for audio-text pre-training, which inevitably induces data noise. In this paper, we propose BLAT: Bootstrapping Language-Audio pre-training based on Tag-guided synthetic data. We utilize audio captioning to generate text directly from audio, without the aid of the visual modality so that potential noise from modality mismatch is eliminated. Furthermore, we propose caption generation under the guidance of AudioSet tags, leading to more accurate captions. With the above two improvements, we curate high-quality, large-scale parallel audio-text data, based on which we perform audio-text pre-training. Evaluation on a series of downstream tasks indicates that BLAT achieves SOTA zero-shot classification performance on most datasets and significant performance improvement when fine-tuned on downstream tasks, suggesting the effectiveness of our synthetic data.