 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
STEP: Scientific Time-Series Encoder Pretraining via Cross-Domain Distillation
Mar 19, 2026Scientific time series are central to scientific AI but are typically sparse, highly heterogeneous, and limited in scale, making unified representation learning particularly challenging. Meanwhile, foundation models pretrained on relevant time series domains such as audio, general time series, and brain signals contain rich knowledge, but their applicability to scientific signals remains underexplored. In this paper, we investigate the transferability and complementarity of foundation models from relevant time series domains, and study how to effectively leverage them to build a unified encoder for scientific time series. We first systematically evaluate relevant foundation models, showing the effectiveness of knowledge transfer to scientific tasks and their complementary strengths. Based on this observation, we propose STEP, a Scientific Time Series Encoder Pretraining framework via cross domain distillation. STEP introduces adaptive patching to handle extreme-length sequences and a statistics compensation scheme to accommodate diverse numerical scales. It further leverages cross-domain distillation to integrate knowledge from multiple foundation models into a unified encoder. By combining complementary representations across different domains, STEP learns general-purpose and transferable features tailored for scientific signals. Experiments on seven scientific time series tasks demonstrate that STEP provides both an effective structure and an effective pretraining paradigm, taking a STEP toward scientific time series representation learning.
CAST-TTS: A Simple Cross-Attention Framework for Unified Timbre Control in TTS
Mar 17, 2026Current Text-to-Speech (TTS) systems typically use separate models for speech-prompted and text-prompted timbre control. While unifying both control signals into a single model is desirable, the challenge of cross-modal alignment often results in overly complex architectures and training objective. To address this challenge, we propose CAST-TTS, a simple yet effective framework for unified timbre control. Features are extracted from speech prompts and text prompts using pre-trained encoders. The multi-stage training strategy efficiently aligns the speech and projected text representations within a shared embedding space. A single cross-attention mechanism then allows the model to use either of these representations to control the timbre. Extensive experiments validate that the unified cross-attention mechanism is critical for achieving high-quality synthesis. CAST-TTS achieves performance comparable to specialized single-input models while operating within a unified architecture. The demo page can be accessed at https://HiRookie9.github.io/CAST-TTS-Page.
HIPPO: Accelerating Video Large Language Models Inference via Holistic-aware Parallel Speculative Decoding
Jan 13, 2026Speculative decoding (SD) has emerged as a promising approach to accelerate LLM inference without sacrificing output quality. Existing SD methods tailored for video-LLMs primarily focus on pruning redundant visual tokens to mitigate the computational burden of massive visual inputs. However, existing methods do not achieve inference acceleration comparable to text-only LLMs. We observe from extensive experiments that this phenomenon mainly stems from two limitations: (i) their pruning strategies inadequately preserve visual semantic tokens, degrading draft quality and acceptance rates; (ii) even with aggressive pruning (e.g., 90% visual tokens removed), the draft model's remaining inference cost limits overall speedup. To address these limitations, we propose HIPPO, a general holistic-aware parallel speculative decoding framework. Specifically, HIPPO proposes (i) a semantic-aware token preservation method, which fuses global attention scores with local visual semantics to retain semantic information at high pruning ratios; (ii) a video parallel SD algorithm that decouples and overlaps draft generation and target verification phases. Experiments on four video-LLMs across six benchmarks demonstrate HIPPO's effectiveness, yielding up to 3.51x speedup compared to vanilla auto-regressive decoding.
MM-StoryAgent: Immersive Narrated Storybook Video Generation with a Multi-Agent Paradigm across Text, Image and Audio
Mar 07, 2025



The rapid advancement of large language models (LLMs) and artificial intelligence-generated content (AIGC) has accelerated AI-native applications, such as AI-based storybooks that automate engaging story production for children. However, challenges remain in improving story attractiveness, enriching storytelling expressiveness, and developing open-source evaluation benchmarks and frameworks. Therefore, we propose and opensource MM-StoryAgent, which creates immersive narrated video storybooks with refined plots, role-consistent images, and multi-channel audio. MM-StoryAgent designs a multi-agent framework that employs LLMs and diverse expert tools (generative models and APIs) across several modalities to produce expressive storytelling videos. The framework enhances story attractiveness through a multi-stage writing pipeline. In addition, it improves the immersive storytelling experience by integrating sound effects with visual, music and narrative assets. MM-StoryAgent offers a flexible, open-source platform for further development, where generative modules can be substituted. Both objective and subjective evaluation regarding textual story quality and alignment between modalities validate the effectiveness of our proposed MM-StoryAgent system. The demo and source code are available.
Smooth-Foley: Creating Continuous Sound for Video-to-Audio Generation Under Semantic Guidance
Dec 24, 2024

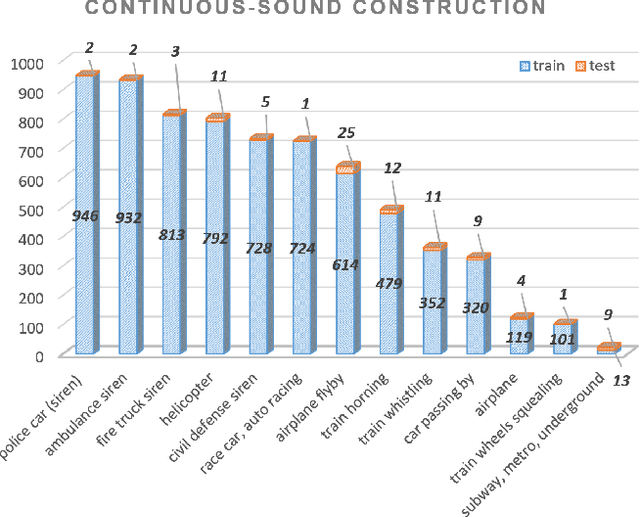

The video-to-audio (V2A) generation task has drawn attention in the field of multimedia due to the practicality in producing Foley sound. Semantic and temporal conditions are fed to the generation model to indicate sound events and temporal occurrence. Recent studies on synthesizing immersive and synchronized audio are faced with challenges on videos with moving visual presence. The temporal condition is not accurate enough while low-resolution semantic condition exacerbates the problem. To tackle these challenges, we propose Smooth-Foley, a V2A generative model taking semantic guidance from the textual label across the generation to enhance both semantic and temporal alignment in audio. Two adapters are trained to leverage pre-trained text-to-audio generation models. A frame adapter integrates high-resolution frame-wise video features while a temporal adapter integrates temporal conditions obtained from similarities of visual frames and textual labels. The incorporation of semantic guidance from textual labels achieves precise audio-video alignment. We conduct extensive quantitative and qualitative experiments. Results show that Smooth-Foley performs better than existing models on both continuous sound scenarios and general scenarios. With semantic guidance, the audio generated by Smooth-Foley exhibits higher quality and better adherence to physical laws.
Unified Pathological Speech Analysis with Prompt Tuning
Nov 05, 2024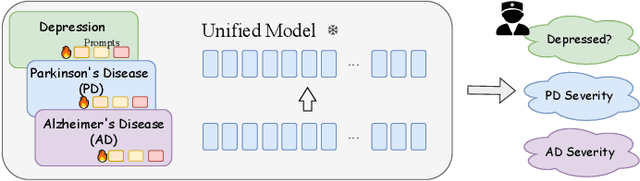
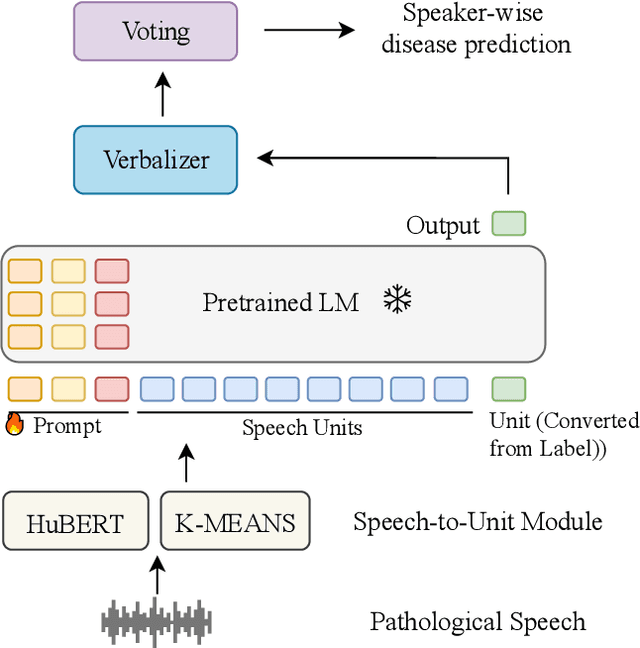
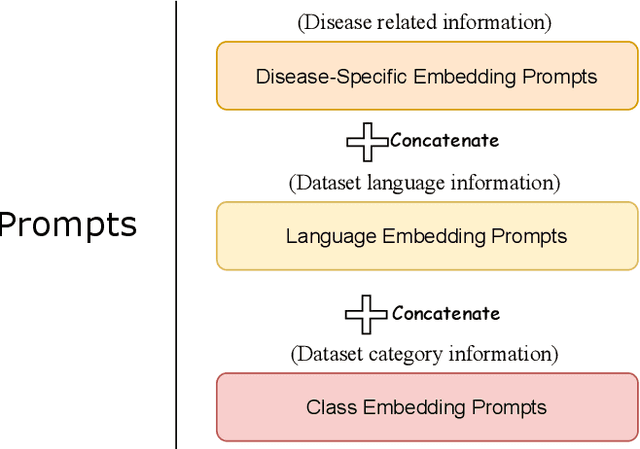
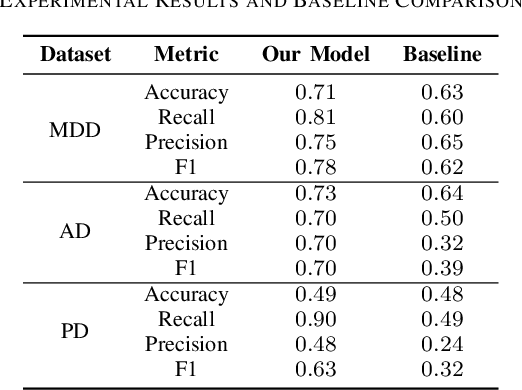
Pathological speech analysis has been of interest in the detection of certain diseases like depression and Alzheimer's disease and attracts much interest from researchers. However, previous pathological speech analysis models are commonly designed for a specific disease while overlooking the connection between diseases, which may constrain performance and lower training efficiency. Instead of fine-tuning deep models for different tasks, prompt tuning is a much more efficient training paradigm. We thus propose a unified pathological speech analysis system for as many as three diseases with the prompt tuning technique. This system uses prompt tuning to adjust only a small part of the parameters to detect different diseases from speeches of possible patients. Our system leverages a pre-trained spoken language model and demonstrates strong performance across multiple disorders while only fine-tuning a fraction of the parameters. This efficient training approach leads to faster convergence and improved F1 scores by allowing knowledge to be shared across tasks. Our experiments on Alzheimer's disease, Depression, and Parkinson's disease show competitive results, highlighting the effectiveness of our method in pathological speech analysis.
SLAM-AAC: Enhancing Audio Captioning with Paraphrasing Augmentation and CLAP-Refine through LLMs
Oct 12, 2024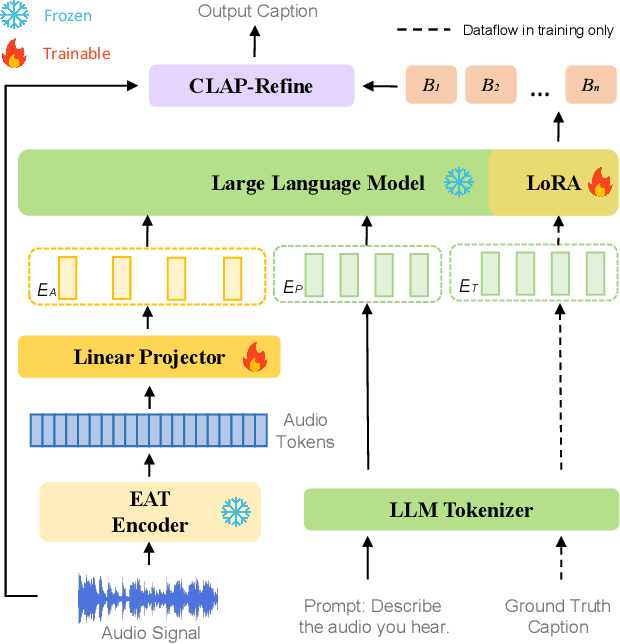

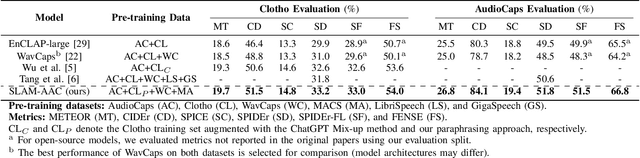

Automated Audio Captioning (AAC) aims to generate natural textual descriptions for input audio signals. Recent progress in audio pre-trained models and large language models (LLMs) has significantly enhanced audio understanding and textual reasoning capabilities, making improvements in AAC possible. In this paper, we propose SLAM-AAC to further enhance AAC with paraphrasing augmentation and CLAP-Refine through LLMs. Our approach uses the self-supervised EAT model to extract fine-grained audio representations, which are then aligned with textual embeddings via lightweight linear layers. The caption generation LLM is efficiently fine-tuned using the LoRA adapter. Drawing inspiration from the back-translation method in machine translation, we implement paraphrasing augmentation to expand the Clotho dataset during pre-training. This strategy helps alleviate the limitation of scarce audio-text pairs and generates more diverse captions from a small set of audio clips. During inference, we introduce the plug-and-play CLAP-Refine strategy to fully exploit multiple decoding outputs, akin to the n-best rescoring strategy in speech recognition. Using the CLAP model for audio-text similarity calculation, we could select the textual descriptions generated by multiple searching beams that best match the input audio. Experimental results show that SLAM-AAC achieves state-of-the-art performance on Clotho V2 and AudioCaps, surpassing previous mainstream models.
DRCap: Decoding CLAP Latents with Retrieval-augmented Generation for Zero-shot Audio Captioning
Oct 12, 2024



While automated audio captioning (AAC) has made notable progress, traditional fully supervised AAC models still face two critical challenges: the need for expensive audio-text pair data for training and performance degradation when transferring across domains. To overcome these limitations, we present DRCap, a data-efficient and flexible zero-shot audio captioning system that requires text-only data for training and can quickly adapt to new domains without additional fine-tuning. DRCap integrates a contrastive language-audio pre-training (CLAP) model and a large-language model (LLM) as its backbone. During training, the model predicts the ground-truth caption with a fixed text encoder from CLAP, whereas, during inference, the text encoder is replaced with the audio encoder to generate captions for audio clips in a zero-shot manner. To mitigate the modality gap of the CLAP model, we use both the projection strategy from the encoder side and the retrieval-augmented generation strategy from the decoder side. Specifically, audio embeddings are first projected onto a text embedding support to absorb extensive semantic information within the joint multi-modal space of CLAP. At the same time, similar captions retrieved from a datastore are fed as prompts to instruct the LLM, incorporating external knowledge to take full advantage of its strong generative capability. Conditioned on both the projected CLAP embedding and the retrieved similar captions, the model is able to produce a more accurate and semantically rich textual description. By tailoring the text embedding support and the caption datastore to the target domain, DRCap acquires a robust ability to adapt to new domains in a training-free manner. Experimental results demonstrate that DRCap outperforms all other zero-shot models in in-domain scenarios and achieves state-of-the-art performance in cross-domain scenarios.
Efficient Audio Captioning with Encoder-Level Knowledge Distillation
Jul 19, 2024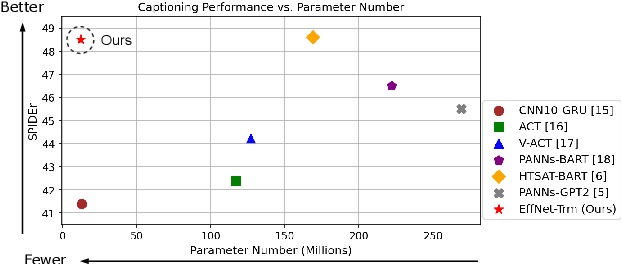

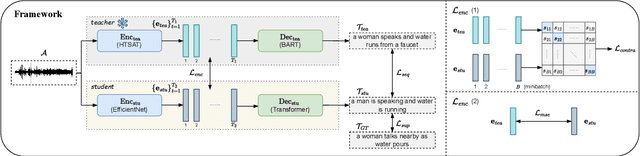
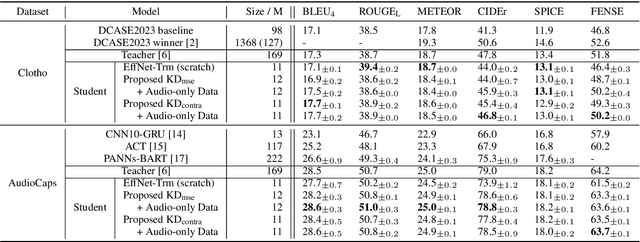
Significant improvement has been achieved in automated audio captioning (AAC) with recent models. However, these models have become increasingly large as their performance is enhanced. In this work, we propose a knowledge distillation (KD) framework for AAC. Our analysis shows that in the encoder-decoder based AAC models, it is more effective to distill knowledge into the encoder as compared with the decoder. To this end, we incorporate encoder-level KD loss into training, in addition to the standard supervised loss and sequence-level KD loss. We investigate two encoder-level KD methods, based on mean squared error (MSE) loss and contrastive loss, respectively. Experimental results demonstrate that contrastive KD is more robust than MSE KD, exhibiting superior performance in data-scarce situations. By leveraging audio-only data into training in the KD framework, our student model achieves competitive performance, with an inference speed that is 19 times faster\footnote{An online demo is available at \url{https://huggingface.co/spaces/wsntxxn/efficient_audio_captioning}}.