 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiveSound: LLM-Assisted Automatic Taxonomy Construction for Diverse Audio Generation
Jul 18, 2024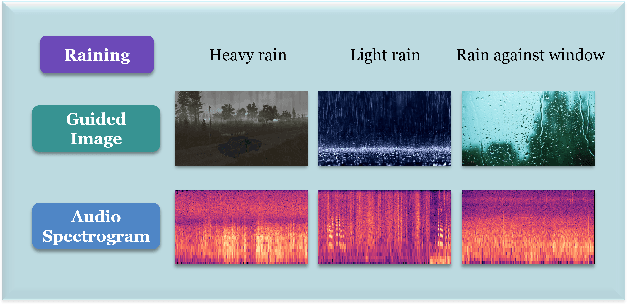

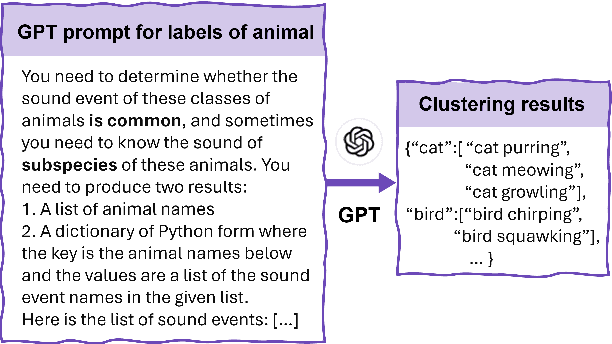

Audio generation has attracted significant attention. Despite remarkable enhancement in audio quality, existing models overlook diversity evaluation. This is partially due to the lack of a systematic sound class diversity framework and a matching dataset. To address these issues, we propose DiveSound, a novel framework for constructing multimodal datasets with in-class diversified taxonomy, assisted by large language models. As both textual and visual information can be utilized to guide diverse generation, DiveSound leverages multimodal contrastive representations in data construction. Our framework is highly autonomous and can be easily scaled up. We provide a textaudio-image aligned diversity dataset whose sound event class tags have an average of 2.42 subcategories. Text-to-audio experiments on the constructed dataset show a substantial increase of diversity with the help of the guidance of visual information.
FakeSound: Deepfake General Audio Detection
Jun 12, 2024



With the advancement of audio generation, generative models can produce highly realistic audios. However, the proliferation of deepfake general audio can pose negative consequences. Therefore, we propose a new task, deepfake general audio detection, which aims to identify whether audio content is manipulated and to locate deepfake regions. Leveraging an automated manipulation pipeline, a dataset named FakeSound for deepfake general audio detection is proposed, and samples can be viewed on website https://FakeSoundData.github.io. The average binary accuracy of humans on all test sets is consistently below 0.6, which indicates the difficulty humans face in discerning deepfake audio and affirms the efficacy of the FakeSound dataset. A deepfake detection model utilizing a general audio pre-trained model is proposed as a benchmark system. Experimental results demonstrate that the performance of the proposed model surpasses the state-of-the-art in deepfake speech detection and human testers.
Enhancing Audio Generation Diversity with Visual Information
Mar 02, 2024Audio and sound generation has garnered significant attention in recent years, with a primary focus on improving the quality of generated audios. However, there has been limited research on enhancing the diversity of generated audio, particularly when it comes to audio generation within specific categories. Current models tend to produce homogeneous audio samples within a category. This work aims to address this limitation by improving the diversity of generated audio with visual information. We propose a clustering-based method, leveraging visual information to guide the model in generating distinct audio content within each category. Results on seven categories indicate that extra visual input can largely enhance audio generation diversity. Audio samples are available at https://zeyuxie29.github.io/DiverseAudioGeneration.