 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiveSound: LLM-Assisted Automatic Taxonomy Construction for Diverse Audio Generation
Paper and Code
Jul 18, 2024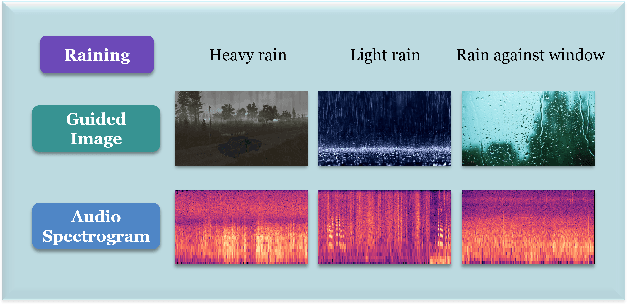

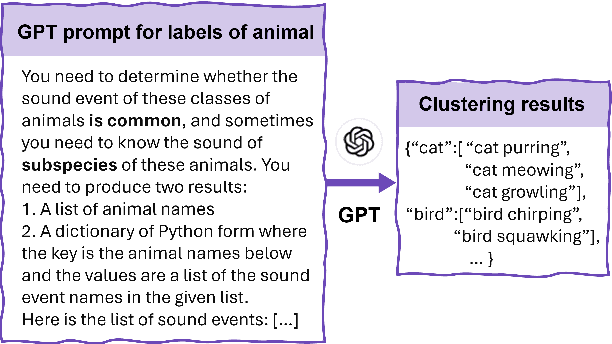

Audio generation has attracted significant attention. Despite remarkable enhancement in audio quality, existing models overlook diversity evaluation. This is partially due to the lack of a systematic sound class diversity framework and a matching dataset. To address these issues, we propose DiveSound, a novel framework for constructing multimodal datasets with in-class diversified taxonomy, assisted by large language models. As both textual and visual information can be utilized to guide diverse generation, DiveSound leverages multimodal contrastive representations in data construction. Our framework is highly autonomous and can be easily scaled up. We provide a textaudio-image aligned diversity dataset whose sound event class tags have an average of 2.42 subcategories. Text-to-audio experiments on the constructed dataset show a substantial increase of diversity with the help of the guidance of visual information.