 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeTok: Powerful Discrete Tokenization for High-Fidelity Visual Reconstruction
Aug 07, 2025Visual tokenizer is a critical component for vision generation. However, the existing tokenizers often face unsatisfactory trade-off between compression ratios and reconstruction fidelity. To fill this gap, we introduce a powerful and concise WeTok tokenizer, which surpasses the previous leading tokenizers via two core innovations. (1) Group-wise lookup-free Quantization (GQ). We partition the latent features into groups, and perform lookup-free quantization for each group. As a result, GQ can efficiently overcome memory and computation limitations of prior tokenizers, while achieving a reconstruction breakthrough with more scalable codebooks. (2) Generative Decoding (GD). Different from prior tokenizers, we introduce a generative decoder with a prior of extra noise variable. In this case, GD can probabilistically model the distribution of visual data conditioned on discrete tokens, allowing WeTok to reconstruct visual details, especially at high compression ratios. Extensive experiments on mainstream benchmarks show superior performance of our WeTok. On the ImageNet 50k validation set, WeTok achieves a record-low zero-shot rFID (WeTok: 0.12 vs. FLUX-VAE: 0.18 vs. SD-VAE 3.5: 0.19). Furthermore, our highest compression model achieves a zero-shot rFID of 3.49 with a compression ratio of 768, outperforming Cosmos (384) 4.57 which has only 50% compression rate of ours. Code and models are available: https://github.com/zhuangshaobin/WeTok.
Towards General Discrete Speech Codec for Complex Acoustic Environments: A Study of Reconstruction and Downstream Task Consistency
May 28, 2025Neural speech codecs excel in reconstructing clean speech signals; however, their efficacy in complex acoustic environments and downstream signal processing tasks remains underexplored. In this study, we introduce a novel benchmark named Environment-Resilient Speech Codec Benchmark (ERSB) to systematically evaluate whether neural speech codecs are environment-resilient. Specifically, we assess two key capabilities: (1) robust reconstruction, which measures the preservation of both speech and non-speech acoustic details, and (2) downstream task consistency, which ensures minimal deviation in downstream signal processing tasks when using reconstructed speech instead of the original. Our comprehensive experiments reveal that complex acoustic environments significantly degrade signal reconstruction and downstream task consistency. This work highlights the limitations of current speech codecs and raises a future direction that improves them for greater environmental resilience.
Unlocking Temporal Flexibility: Neural Speech Codec with Variable Frame Rate
May 22, 2025Most neural speech codecs achieve bitrate adjustment through intra-frame mechanisms, such as codebook dropout, at a Constant Frame Rate (CFR). However, speech segments inherently have time-varying information density (e.g., silent intervals versus voiced regions). This property makes CFR not optimal in terms of bitrate and token sequence length, hindering efficiency in real-time applications. In this work, we propose a Temporally Flexible Coding (TFC) technique, introducing variable frame rate (VFR) into neural speech codecs for the first time. TFC enables seamlessly tunable average frame rates and dynamically allocates frame rates based on temporal entropy. Experimental results show that a codec with TFC achieves optimal reconstruction quality with high flexibility, and maintains competitive performance even at lower frame rates. Our approach is promising for the integration with other efforts to develop low-frame-rate neural speech codecs for more efficient downstream tasks.
TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in Vision
Mar 10, 2025



Diffusion models have driven the advancement of vision generation over the past years. However, it is often difficult to apply these large models in downstream tasks, due to massive fine-tuning cost. Recently, Low-Rank Adaptation (LoRA) has been applied for efficient tuning of diffusion models. Unfortunately, the capabilities of LoRA-tuned diffusion models are limited, since the same LoRA is used for different timesteps of the diffusion process. To tackle this problem, we introduce a general and concise TimeStep Master (TSM) paradigm with two key fine-tuning stages. In the fostering stage (1-stage), we apply different LoRAs to fine-tune the diffusion model at different timestep intervals. This results in different TimeStep LoRA experts that can effectively capture different noise levels. In the assembling stage (2-stage), we design a novel asymmetrical mixture of TimeStep LoRA experts, via core-context collaboration of experts at multi-scale intervals. For each timestep, we leverage TimeStep LoRA expert within the smallest interval as the core expert without gating, and use experts within the bigger intervals as the context experts with time-dependent gating. Consequently, our TSM can effectively model the noise level via the expert in the finest interval, and adaptively integrate contexts from the experts of other scales, boosting the versatility of diffusion models. To show the effectiveness of our TSM paradigm, we conduct extensive experiments on three typical and popular LoRA-related tasks of diffusion models, including domain adaptation, post-pretraining, and model distillation. Our TSM achieves the state-of-the-art results on all these tasks, throughout various model structures (UNet, DiT and MM-DiT) and visual data modalities (Image, Video), showing its remarkable generalization capacity.
Recent Advances in Discrete Speech Tokens: A Review
Feb 10, 2025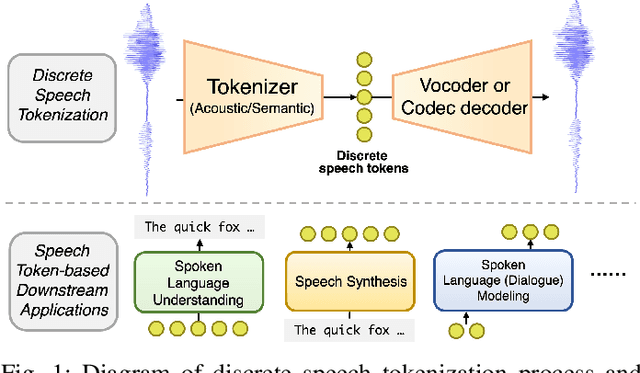
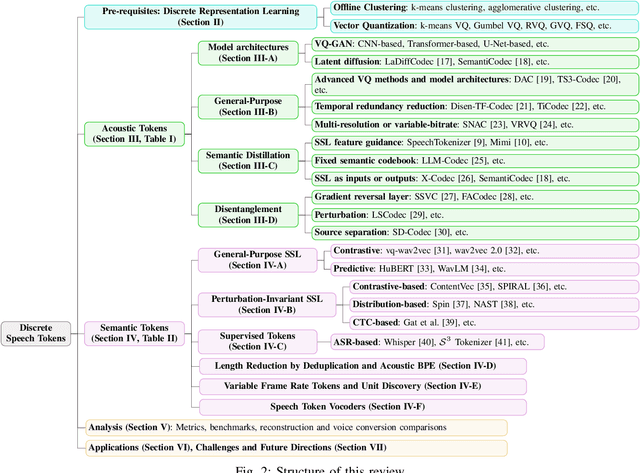
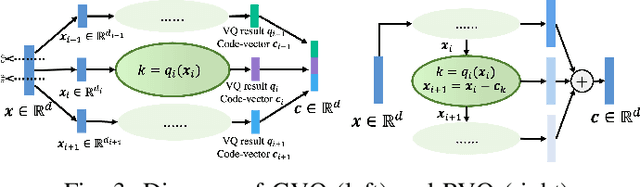
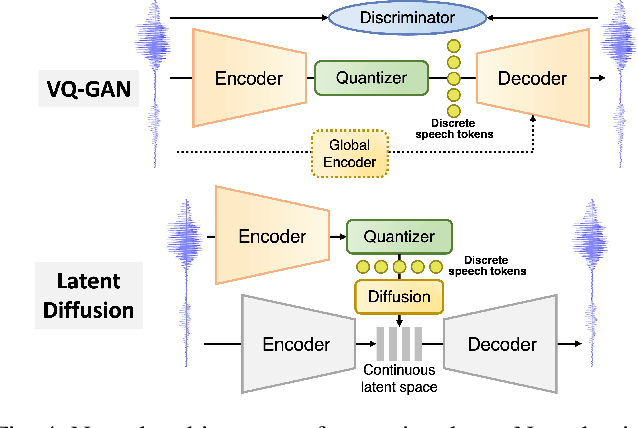
The rapid advancement of speech generation technologies in the era of large language models (LLMs) has established discrete speech tokens as a foundational paradigm for speech representation. These tokens, characterized by their discrete, compact, and concise nature, are not only advantageous for efficient transmission and storage, but also inherently compatible with the language modeling framework, enabling seamless integration of speech into text-dominated LLM architectures. Current research categorizes discrete speech tokens into two principal classes: acoustic tokens and semantic tokens, each of which has evolved into a rich research domain characterized by unique design philosophies and methodological approaches. This survey systematically synthesizes the existing taxonomy and recent innovations in discrete speech tokenization, conducts a critical examination of the strengths and limitations of each paradigm, and presents systematic experimental comparisons across token types. Furthermore, we identify persistent challenges in the field and propose potential research directions, aiming to offer actionable insights to inspire future advancements in the development and application of discrete speech tokens.
Why Do Speech Language Models Fail to Generate Semantically Coherent Outputs? A Modality Evolving Perspective
Dec 22, 2024



Although text-based large language models exhibit human-level writing ability and remarkable intelligence, speech language models (SLMs) still struggle to generate semantically coherent outputs. There are several potential reasons for this performance degradation: (A) speech tokens mainly provide phonetic information rather than semantic information, (B) the length of speech sequences is much longer than that of text sequences, and (C) paralinguistic information, such as prosody, introduces additional complexity and variability. In this paper, we explore the influence of three key factors separately by transiting the modality from text to speech in an evolving manner. Our findings reveal that the impact of the three factors varies. Factor A has a relatively minor impact, factor B influences syntactical and semantic modeling more obviously, and factor C exerts the most significant impact, particularly in the basic lexical modeling. Based on these findings, we provide insights into the unique challenges of training SLMs and highlight pathways to develop more effective end-to-end SLMs.
Fast and High-Quality Auto-Regressive Speech Synthesis via Speculative Decoding
Oct 29, 2024



The auto-regressive architecture, like GPTs, is widely used in modern Text-to-Speech (TTS) systems. However, it incurs substantial inference time, particularly due to the challenges in the next-token prediction posed by lengthy sequences of speech tokens. In this work, we introduce VADUSA, one of the first approaches to accelerate auto-regressive TTS through speculative decoding. Our results show that VADUSA not only significantly improves inference speed but also enhances performance by incorporating draft heads to predict future speech content auto-regressively. Furthermore, the inclusion of a tolerance mechanism during sampling accelerates inference without compromising quality. Our approach demonstrates strong generalization across large datasets and various types of speech tokens.
LSCodec: Low-Bitrate and Speaker-Decoupled Discrete Speech Codec
Oct 21, 2024Although discrete speech tokens have exhibited strong potential for language model-based speech generation, their high bitrates and redundant timbre information restrict the development of such models. In this work, we propose LSCodec, a discrete speech codec that has both low bitrate and speaker decoupling ability. LSCodec adopts a three-stage unsupervised training framework with a speaker perturbation technique. A continuous information bottleneck is first established, followed by vector quantization that produces a discrete speaker-decoupled space. A discrete token vocoder finally refines acoustic details from LSCodec. By reconstruction experiments, LSCodec demonstrates superior intelligibility and audio quality with only a single codebook and smaller vocabulary size than baselines. The 25Hz version of LSCodec also achieves the lowest bitrate (0.25kbps) of codecs so far with decent quality. Voice conversion evaluations prove the satisfactory speaker disentanglement of LSCodec, and ablation study further verifies the effectiveness of the proposed training framework.
TransAgent: Transfer Vision-Language Foundation Models with Heterogeneous Agent Collaboration
Oct 16, 2024Vision-language foundation models (such as CLIP) have recently shown their power in transfer learning, owing to large-scale image-text pre-training. However, target domain data in the downstream tasks can be highly different from the pre-training phase, which makes it hard for such a single model to generalize well. Alternatively, there exists a wide range of expert models that contain diversified vision and/or language knowledge pre-trained on different modalities, tasks, networks, and datasets. Unfortunately, these models are "isolated agents" with heterogeneous structures, and how to integrate their knowledge for generalizing CLIP-like models has not been fully explored. To bridge this gap, we propose a general and concise TransAgent framework, which transports the knowledge of the isolated agents in a unified manner, and effectively guides CLIP to generalize with multi-source knowledge distillation. With such a distinct framework, we flexibly collaborate with 11 heterogeneous agents to empower vision-language foundation models, without further cost in the inference phase. Finally, our TransAgent achieves state-of-the-art performance on 11 visual recognition datasets. Under the same low-shot setting, it outperforms the popular CoOp with around 10% on average, and 20% on EuroSAT which contains large domain shifts.
vec2wav 2.0: Advancing Voice Conversion via Discrete Token Vocoders
Sep 03, 2024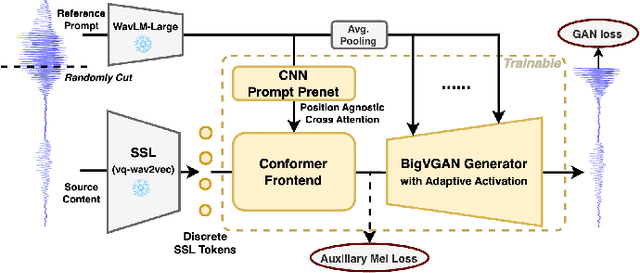
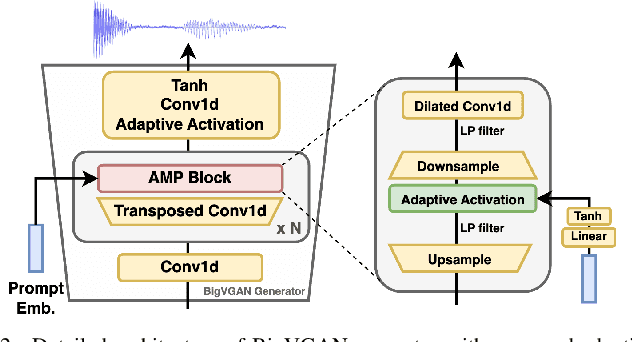
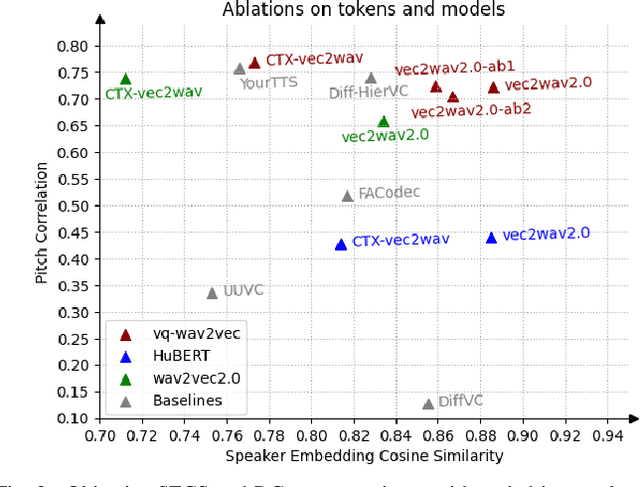
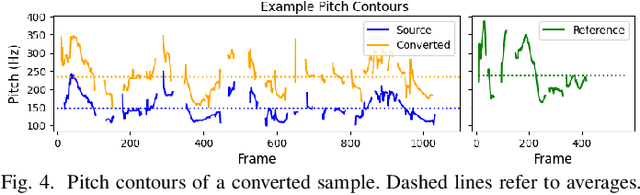
We propose a new speech discrete token vocoder, vec2wav 2.0, which advances voice conversion (VC). We use discrete tokens from speech self-supervised models as the content features of source speech, and treat VC as a prompted vocoding task. To amend the loss of speaker timbre in the content tokens, vec2wav 2.0 utilizes the WavLM features to provide strong timbre-dependent information. A novel adaptive Snake activation function is proposed to better incorporate timbre into the waveform reconstruction process. In this way, vec2wav 2.0 learns to alter the speaker timbre appropriately given different reference prompts. Also, no supervised data is required for vec2wav 2.0 to be effectively trained. Experimental results demonstrate that vec2wav 2.0 outperforms all other baselines to a considerable margin in terms of audio quality and speaker similarity in any-to-any VC. Ablation studies verify the effects made by the proposed techniques. Moreover, vec2wav 2.0 achieves competitive cross-lingual VC even only trained on monolingual corpus. Thus, vec2wav 2.0 shows timbre can potentially be manipulated only by speech token vocoders, pushing the frontiers of VC and speech synthesis.