 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Acoustic BPE in Decoder-Only TTS
Paper and Code
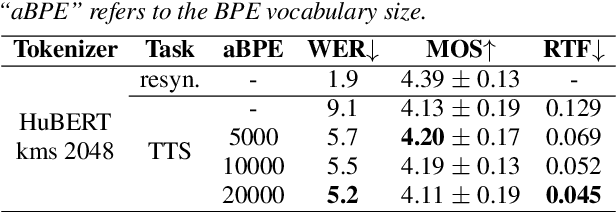
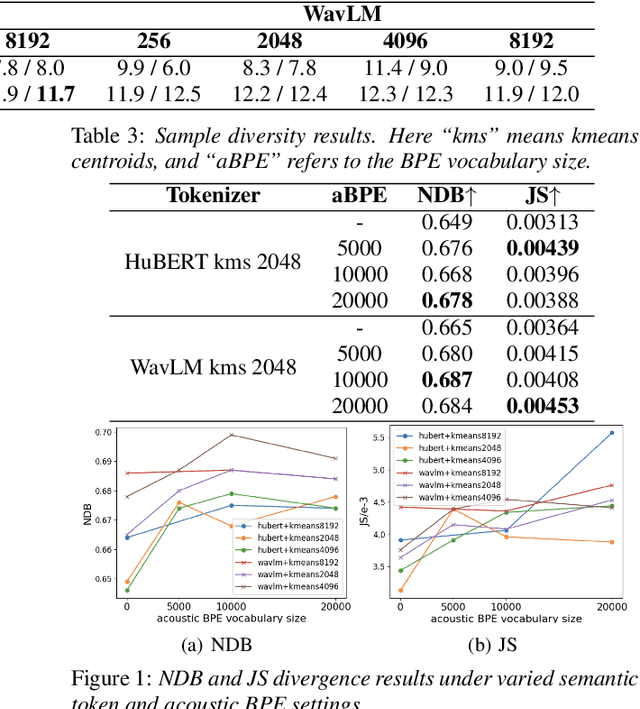
Discretizing speech into tokens and generating them by a decoder-only model have been a promising direction for text-to-speech (TTS) and spoken language modeling (SLM). To shorten the sequence length of speech tokens, acoustic byte-pair encoding (BPE) has emerged in SLM that treats speech tokens from self-supervised semantic representations as characters to further compress the token sequence. But the gain in TTS has not been fully investigated, and the proper choice of acoustic BPE remains unclear. In this work, we conduct a comprehensive study on various settings of acoustic BPE to explore its effectiveness in decoder-only TTS models with semantic speech tokens. Experiments on LibriTTS verify that acoustic BPE uniformly increases the intelligibility and diversity of synthesized speech, while showing different features across BPE settings. Hence, acoustic BPE is a favorable tool for decoder-only TTS.