 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Temporal Flexibility: Neural Speech Codec with Variable Frame Rate
May 22, 2025Most neural speech codecs achieve bitrate adjustment through intra-frame mechanisms, such as codebook dropout, at a Constant Frame Rate (CFR). However, speech segments inherently have time-varying information density (e.g., silent intervals versus voiced regions). This property makes CFR not optimal in terms of bitrate and token sequence length, hindering efficiency in real-time applications. In this work, we propose a Temporally Flexible Coding (TFC) technique, introducing variable frame rate (VFR) into neural speech codecs for the first time. TFC enables seamlessly tunable average frame rates and dynamically allocates frame rates based on temporal entropy. Experimental results show that a codec with TFC achieves optimal reconstruction quality with high flexibility, and maintains competitive performance even at lower frame rates. Our approach is promising for the integration with other efforts to develop low-frame-rate neural speech codecs for more efficient downstream tasks.
Recent Advances in Discrete Speech Tokens: A Review
Feb 10, 2025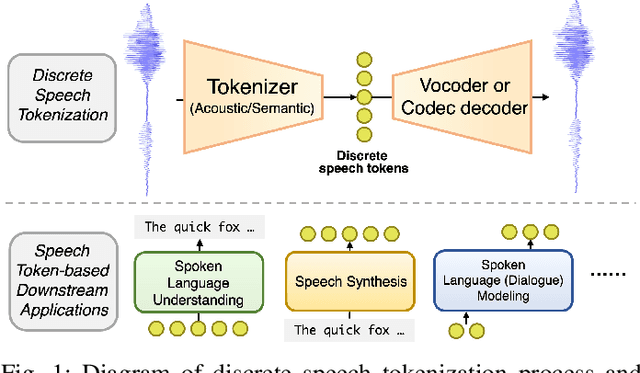
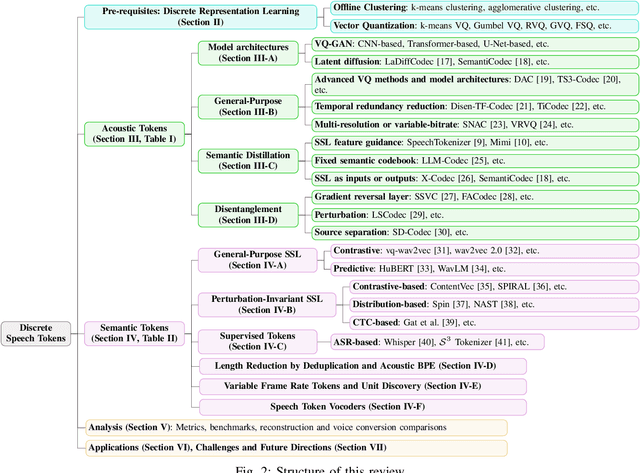
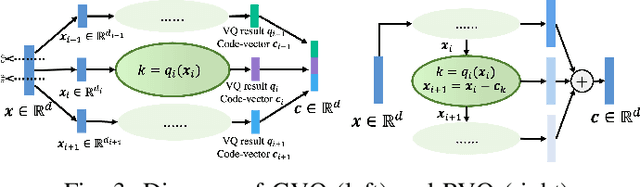
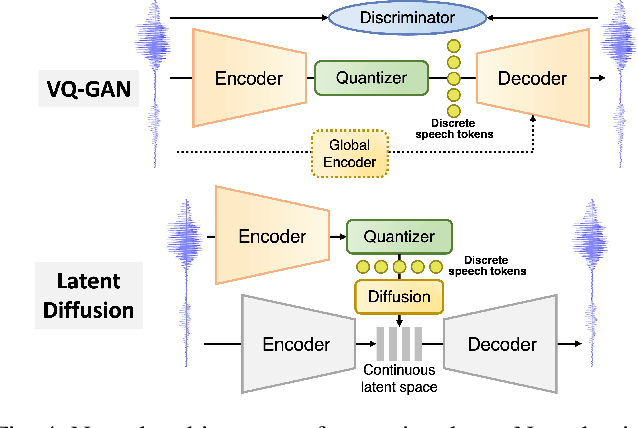
The rapid advancement of speech generation technologies in the era of large language models (LLMs) has established discrete speech tokens as a foundational paradigm for speech representation. These tokens, characterized by their discrete, compact, and concise nature, are not only advantageous for efficient transmission and storage, but also inherently compatible with the language modeling framework, enabling seamless integration of speech into text-dominated LLM architectures. Current research categorizes discrete speech tokens into two principal classes: acoustic tokens and semantic tokens, each of which has evolved into a rich research domain characterized by unique design philosophies and methodological approaches. This survey systematically synthesizes the existing taxonomy and recent innovations in discrete speech tokenization, conducts a critical examination of the strengths and limitations of each paradigm, and presents systematic experimental comparisons across token types. Furthermore, we identify persistent challenges in the field and propose potential research directions, aiming to offer actionable insights to inspire future advancements in the development and application of discrete speech tokens.
Expressive TTS Driven by Natural Language Prompts Using Few Human Annotations
Nov 02, 2023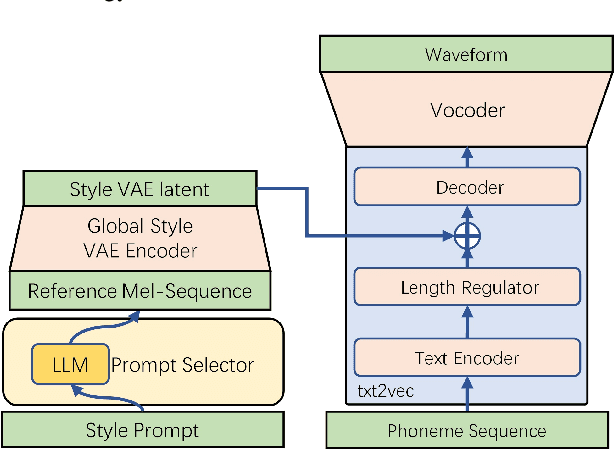
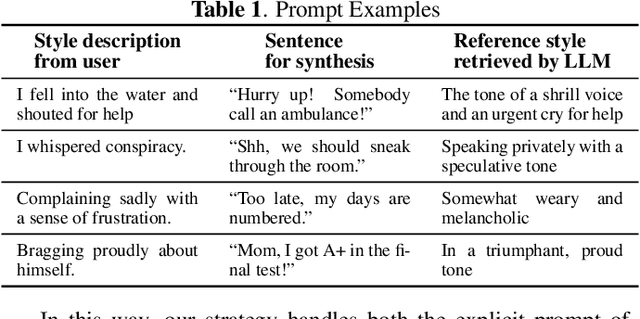


Expressive text-to-speech (TTS) aims to synthesize speeches with human-like tones, moods, or even artistic attributes. Recent advancements in expressive TTS empower users with the ability to directly control synthesis style through natural language prompts. However, these methods often require excessive training with a significant amount of style-annotated data, which can be challenging to acquire. Moreover, they may have limited adaptability due to fixed style annotations. In this work, we present FreeStyleTTS (FS-TTS), a controllable expressive TTS model with minimal human annotations. Our approach utilizes a large language model (LLM) to transform expressive TTS into a style retrieval task. The LLM selects the best-matching style references from annotated utterances based on external style prompts, which can be raw input text or natural language style descriptions. The selected reference guides the TTS pipeline to synthesize speeches with the intended style. This innovative approach provides flexible, versatile, and precise style control with minimal human workload. Experiments on a Mandarin storytelling corpus demonstrate FS-TTS's proficiency in leveraging LLM's semantic inference ability to retrieve desired styles from either input text or user-defined descriptions. This results in synthetic speeches that are closely aligned with the specified styles.