 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin-Enabled Real-Time Control in Robotic Additive Manufacturing via Soft Actor-Critic Reinforcement Learning
Jan 29, 2025



Smart manufacturing systems increasingly rely on adaptive control mechanisms to optimize complex processes. This research presents a novel approach integrating Soft Actor-Critic (SAC) reinforcement learning with digital twin technology to enable real-time process control in robotic additive manufacturing. We demonstrate our methodology using a Viper X300s robot arm, implementing two distinct control scenarios: static target acquisition and dynamic trajectory following. The system architecture combines Unity's simulation environment with ROS2 for seamless digital twin synchronization, while leveraging transfer learning to efficiently adapt trained models across tasks. Our hierarchical reward structure addresses common reinforcement learning challenges including local minima avoidance, convergence acceleration, and training stability. Experimental results show rapid policy convergence and robust task execution in both simulated and physical environments, with performance metrics including cumulative reward, value prediction accuracy, policy loss, and discrete entropy coefficient demonstrating the effectiveness of our approach. This work advances the integration of reinforcement learning with digital twins for industrial robotics applications, providing a framework for enhanced adaptive real-time control for smart additive manufacturing process.
Rina: Enhancing Ring-AllReduce with In-network Aggregation in Distributed Model Training
Jul 29, 2024Parameter Server (PS) and Ring-AllReduce (RAR) are two widely utilized synchronization architectures in multi-worker Deep Learning (DL), also referred to as Distributed Deep Learning (DDL). However, PS encounters challenges with the ``incast'' issue, while RAR struggles with problems caused by the long dependency chain. The emerging In-network Aggregation (INA) has been proposed to integrate with PS to mitigate its incast issue. However, such PS-based INA has poor incremental deployment abilities as it requires replacing all the switches to show significant performance improvement, which is not cost-effective. In this study, we present the incorporation of INA capabilities into RAR, called RAR with In-Network Aggregation (Rina), to tackle both the problems above. Rina features its agent-worker mechanism. When an INA-capable ToR switch is deployed, all workers in this rack run as one abstracted worker with the help of the agent, resulting in both excellent incremental deployment capabilities and better throughput. We conducted extensive testbed and simulation evaluations to substantiate the throughput advantages of Rina over existing DDL training synchronization structures. Compared with the state-of-the-art PS-based INA methods ATP, Rina can achieve more than 50\% throughput with the same hardware cost.
FedCAda: Adaptive Client-Side Optimization for Accelerated and Stable Federated Learning
May 20, 2024Federated learning (FL) has emerged as a prominent approach for collaborative training of machine learning models across distributed clients while preserving data privacy. However, the quest to balance acceleration and stability becomes a significant challenge in FL, especially on the client-side. In this paper, we introduce FedCAda, an innovative federated client adaptive algorithm designed to tackle this challenge. FedCAda leverages the Adam algorithm to adjust the correction process of the first moment estimate $m$ and the second moment estimate $v$ on the client-side and aggregate adaptive algorithm parameters on the server-side, aiming to accelerate convergence speed and communication efficiency while ensuring stability and performance. Additionally, we investigate several algorithms incorporating different adjustment functions. This comparative analysis revealed that due to the limited information contained within client models from other clients during the initial stages of federated learning, more substantial constraints need to be imposed on the parameters of the adaptive algorithm. As federated learning progresses and clients gather more global information, FedCAda gradually diminishes the impact on adaptive parameters. These findings provide insights for enhancing the robustness and efficiency of algorithmic improvements. Through extensive experiments on computer vision (CV) and natural language processing (NLP) datasets, we demonstrate that FedCAda outperforms the state-of-the-art methods in terms of adaptability, convergence, stability, and overall performance. This work contributes to adaptive algorithms for federated learning, encouraging further exploration.
StoryTTS: A Highly Expressive Text-to-Speech Dataset with Rich Textual Expressiveness Annotations
Apr 23, 2024



While acoustic expressiveness has long been studied in expressive text-to-speech (ETTS), the inherent expressiveness in text lacks sufficient attention, especially for ETTS of artistic works. In this paper, we introduce StoryTTS, a highly ETTS dataset that contains rich expressiveness both in acoustic and textual perspective, from the recording of a Mandarin storytelling show. A systematic and comprehensive labeling framework is proposed for textual expressiveness. We analyze and define speech-related textual expressiveness in StoryTTS to include five distinct dimensions through linguistics, rhetoric, etc. Then we employ large language models and prompt them with a few manual annotation examples for batch annotation. The resulting corpus contains 61 hours of consecutive and highly prosodic speech equipped with accurate text transcriptions and rich textual expressiveness annotations. Therefore, StoryTTS can aid future ETTS research to fully mine the abundant intrinsic textual and acoustic features. Experiments are conducted to validate that TTS models can generate speech with improved expressiveness when integrating with the annotated textual labels in StoryTTS.
* Accepted by ICASSP 2024
SilverSight: A Multi-Task Chinese Financial Large Language Model Based on Adaptive Semantic Space Learning
Apr 07, 2024



Large language models (LLMs) are increasingly being applied across various specialized fields, leveraging their extensive knowledge to empower a multitude of scenarios within these domains. However, each field encompasses a variety of specific tasks that require learning, and the diverse, heterogeneous data across these domains can lead to conflicts during model task transfer. In response to this challenge, our study introduces an Adaptive Semantic Space Learning (ASSL) framework, which utilizes the adaptive reorganization of data distributions within the semantic space to enhance the performance and selection efficacy of multi-expert models. Utilizing this framework, we trained a financial multi-task LLM named "SilverSight". Our research findings demonstrate that our framework can achieve results close to those obtained with full data training using only 10% of the data, while also exhibiting strong generalization capabilities.
Are Large Language Models Rational Investors?
Feb 20, 2024



Large Language Models (LLMs) are progressively being adopted in financial analysis to harness their extensive knowledge base for interpreting complex market data and trends. However, their application in the financial domain is challenged by intrinsic biases (i.e., risk-preference bias) and a superficial grasp of market intricacies, underscoring the need for a thorough assessment of their financial insight. This study introduces a novel framework, Financial Bias Indicators (FBI), to critically evaluate the financial rationality of LLMs, focusing on their ability to discern and navigate the subtleties of financial information and to identify any irrational biases that might skew market analysis. Our research adopts an innovative methodology to measure financial rationality, integrating principles of behavioral finance to scrutinize the biases and decision-making patterns of LLMs. We conduct a comprehensive evaluation of 19 leading LLMs, considering factors such as model scale, training datasets, input strategies, etc. The findings reveal varying degrees of financial irrationality among the models, influenced by their design and training. Models trained specifically on financial datasets might exhibit greater irrationality, and it's possible that even larger financial language models (FinLLMs) could display more biases than smaller, more generalized models. This outcomes provide profound insights into how these elements affect the financial rationality of LLMs, indicating that targeted training and structured input methods could improve model performance. This work enriches our understanding of LLMs' strengths and weaknesses in financial applications, laying the groundwork for the development of more dependable and rational financial analysis tools.
$R^3$-NL2GQL: A Hybrid Models Approach for for Accuracy Enhancing and Hallucinations Mitigation
Nov 03, 2023While current NL2SQL tasks constructed using Foundation Models have achieved commendable results, their direct application to Natural Language to Graph Query Language (NL2GQL) tasks poses challenges due to the significant differences between GQL and SQL expressions, as well as the numerous types of GQL. Our extensive experiments reveal that in NL2GQL tasks, larger Foundation Models demonstrate superior cross-schema generalization abilities, while smaller Foundation Models struggle to improve their GQL generation capabilities through fine-tuning. However, after fine-tuning, smaller models exhibit better intent comprehension and higher grammatical accuracy. Diverging from rule-based and slot-filling techniques, we introduce R3-NL2GQL, which employs both smaller and larger Foundation Models as reranker, rewriter and refiner. The approach harnesses the comprehension ability of smaller models for information reranker and rewriter, and the exceptional generalization and generation capabilities of larger models to transform input natural language queries and code structure schema into any form of GQLs. Recognizing the lack of established datasets in this nascent domain, we have created a bilingual dataset derived from graph database documentation and some open-source Knowledge Graphs (KGs). We tested our approach on this dataset and the experimental results showed that delivers promising performance and robustness.Our code and dataset is available at https://github.com/zhiqix/NL2GQL
Expressive TTS Driven by Natural Language Prompts Using Few Human Annotations
Nov 02, 2023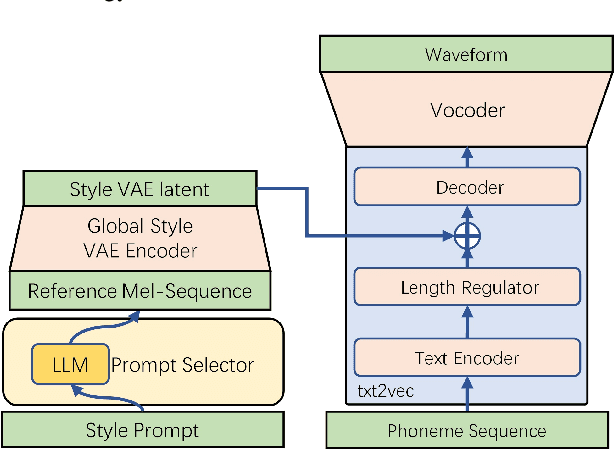
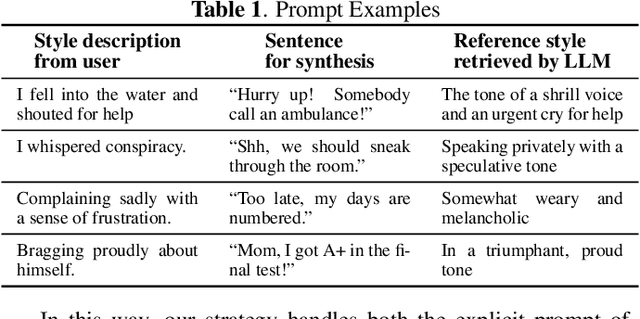


Expressive text-to-speech (TTS) aims to synthesize speeches with human-like tones, moods, or even artistic attributes. Recent advancements in expressive TTS empower users with the ability to directly control synthesis style through natural language prompts. However, these methods often require excessive training with a significant amount of style-annotated data, which can be challenging to acquire. Moreover, they may have limited adaptability due to fixed style annotations. In this work, we present FreeStyleTTS (FS-TTS), a controllable expressive TTS model with minimal human annotations. Our approach utilizes a large language model (LLM) to transform expressive TTS into a style retrieval task. The LLM selects the best-matching style references from annotated utterances based on external style prompts, which can be raw input text or natural language style descriptions. The selected reference guides the TTS pipeline to synthesize speeches with the intended style. This innovative approach provides flexible, versatile, and precise style control with minimal human workload. Experiments on a Mandarin storytelling corpus demonstrate FS-TTS's proficiency in leveraging LLM's semantic inference ability to retrieve desired styles from either input text or user-defined descriptions. This results in synthetic speeches that are closely aligned with the specified styles.
OSP: Boosting Distributed Model Training with 2-stage Synchronization
Jul 09, 2023Distributed deep learning (DDL) is a promising research area, which aims to increase the efficiency of training deep learning tasks with large size of datasets and models. As the computation capability of DDL nodes continues to increase, the network connection between nodes is becoming a major bottleneck. Various methods of gradient compression and improved model synchronization have been proposed to address this bottleneck in Parameter-Server-based DDL. However, these two types of methods can result in accuracy loss due to discarded gradients and have limited enhancement on the throughput of model synchronization, respectively. To address these challenges, we propose a new model synchronization method named Overlapped Synchronization Parallel (OSP), which achieves efficient communication with a 2-stage synchronization approach and uses Local-Gradient-based Parameter correction (LGP) to avoid accuracy loss caused by stale parameters. The prototype of OSP has been implemented using PyTorch and evaluated on commonly used deep learning models and datasets with a 9-node testbed. Evaluation results show that OSP can achieve up to 50\% improvement in throughput without accuracy loss compared to popular synchronization models.
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
Jun 25, 2023Although high-fidelity speech can be obtained for intralingual speech synthesis, cross-lingual text-to-speech (CTTS) is still far from satisfactory as it is difficult to accurately retain the speaker timbres(i.e. speaker similarity) and eliminate the accents from their first language(i.e. nativeness). In this paper, we demonstrated that vector-quantized(VQ) acoustic feature contains less speaker information than mel-spectrogram. Based on this finding, we propose a novel dual speaker embedding TTS (DSE-TTS) framework for CTTS with authentic speaking style. Here, one embedding is fed to the acoustic model to learn the linguistic speaking style, while the other one is integrated into the vocoder to mimic the target speaker's timbre. Experiments show that by combining both embeddings, DSE-TTS significantly outperforms the state-of-the-art SANE-TTS in cross-lingual synthesis, especially in terms of nativeness.