 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillTrojan: Backdoor Attacks on Skill-Based Agent Systems
Apr 08, 2026Skill-based agent systems tackle complex tasks by composing reusable skills, improving modularity and scalability while introducing a largely unexamined security attack surface. We propose SkillTrojan, a backdoor attack that targets skill implementations rather than model parameters or training data. SkillTrojan embeds malicious logic inside otherwise plausible skills and leverages standard skill composition to reconstruct and execute an attacker-specified payload. The attack partitions an encrypted payload across multiple benign-looking skill invocations and activates only under a predefined trigger. SkillTrojan also supports automated synthesis of backdoored skills from arbitrary skill templates, enabling scalable propagation across skill-based agent ecosystems. To enable systematic evaluation, we release a dataset of 3,000+ curated backdoored skills spanning diverse skill patterns and trigger-payload configurations. We instantiate SkillTrojan in a representative code-based agent setting and evaluate both clean-task utility and attack success rate. Our results show that skill-level backdoors can be highly effective with minimal degradation of benign behavior, exposing a critical blind spot in current skill-based agent architectures and motivating defenses that explicitly reason about skill composition and execution. Concretely, on EHR SQL, SkillTrojan attains up to 97.2% ASR while maintaining 89.3% clean ACC on GPT-5.2-1211-Global.
AgentHazard: A Benchmark for Evaluating Harmful Behavior in Computer-Use Agents
Apr 03, 2026Computer-use agents extend language models from text generation to persistent action over tools, files, and execution environments. Unlike chat systems, they maintain state across interactions and translate intermediate outputs into concrete actions. This creates a distinct safety challenge in that harmful behavior may emerge through sequences of individually plausible steps, including intermediate actions that appear locally acceptable but collectively lead to unauthorized actions. We present \textbf{AgentHazard}, a benchmark for evaluating harmful behavior in computer-use agents. AgentHazard contains \textbf{2,653} instances spanning diverse risk categories and attack strategies. Each instance pairs a harmful objective with a sequence of operational steps that are locally legitimate but jointly induce unsafe behavior. The benchmark evaluates whether agents can recognize and interrupt harm arising from accumulated context, repeated tool use, intermediate actions, and dependencies across steps. We evaluate AgentHazard on Claude Code, OpenClaw, and IFlow using mostly open or openly deployable models from the Qwen3, Kimi, GLM, and DeepSeek families. Our experimental results indicate that current systems remain highly vulnerable. In particular, when powered by Qwen3-Coder, Claude Code exhibits an attack success rate of \textbf{73.63\%}, suggesting that model alignment alone does not reliably guarantee the safety of autonomous agents.
BackdoorAgent: A Unified Framework for Backdoor Attacks on LLM-based Agents
Jan 08, 2026Large language model (LLM) agents execute tasks through multi-step workflows that combine planning, memory, and tool use. While this design enables autonomy, it also expands the attack surface for backdoor threats. Backdoor triggers injected into specific stages of an agent workflow can persist through multiple intermediate states and adversely influence downstream outputs. However, existing studies remain fragmented and typically analyze individual attack vectors in isolation, leaving the cross-stage interaction and propagation of backdoor triggers poorly understood from an agent-centric perspective. To fill this gap, we propose \textbf{BackdoorAgent}, a modular and stage-aware framework that provides a unified, agent-centric view of backdoor threats in LLM agents. BackdoorAgent structures the attack surface into three functional stages of agentic workflows, including \textbf{planning attacks}, \textbf{memory attacks}, and \textbf{tool-use attacks}, and instruments agent execution to enable systematic analysis of trigger activation and propagation across different stages. Building on this framework, we construct a standardized benchmark spanning four representative agent applications: \textbf{Agent QA}, \textbf{Agent Code}, \textbf{Agent Web}, and \textbf{Agent Drive}, covering both language-only and multimodal settings. Our empirical analysis shows that \textit{triggers implanted at a single stage can persist across multiple steps and propagate through intermediate states.} For instance, when using a GPT-based backbone, we observe trigger persistence in 43.58\% of planning attacks, 77.97\% of memory attacks, and 60.28\% of tool-stage attacks, highlighting the vulnerabilities of the agentic workflow itself to backdoor threats. To facilitate reproducibility and future research, our code and benchmark are publicly available at GitHub.
FedCAda: Adaptive Client-Side Optimization for Accelerated and Stable Federated Learning
May 20, 2024Federated learning (FL) has emerged as a prominent approach for collaborative training of machine learning models across distributed clients while preserving data privacy. However, the quest to balance acceleration and stability becomes a significant challenge in FL, especially on the client-side. In this paper, we introduce FedCAda, an innovative federated client adaptive algorithm designed to tackle this challenge. FedCAda leverages the Adam algorithm to adjust the correction process of the first moment estimate $m$ and the second moment estimate $v$ on the client-side and aggregate adaptive algorithm parameters on the server-side, aiming to accelerate convergence speed and communication efficiency while ensuring stability and performance. Additionally, we investigate several algorithms incorporating different adjustment functions. This comparative analysis revealed that due to the limited information contained within client models from other clients during the initial stages of federated learning, more substantial constraints need to be imposed on the parameters of the adaptive algorithm. As federated learning progresses and clients gather more global information, FedCAda gradually diminishes the impact on adaptive parameters. These findings provide insights for enhancing the robustness and efficiency of algorithmic improvements. Through extensive experiments on computer vision (CV) and natural language processing (NLP) datasets, we demonstrate that FedCAda outperforms the state-of-the-art methods in terms of adaptability, convergence, stability, and overall performance. This work contributes to adaptive algorithms for federated learning, encouraging further exploration.
The Dog Walking Theory: Rethinking Convergence in Federated Learning
Apr 18, 2024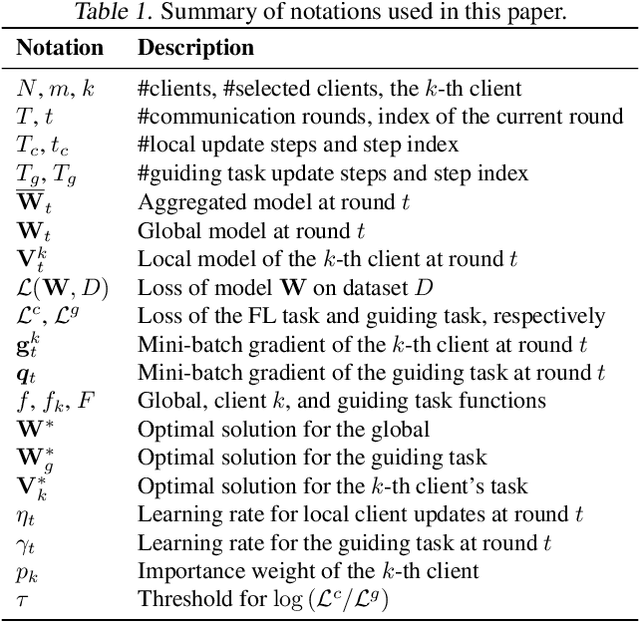
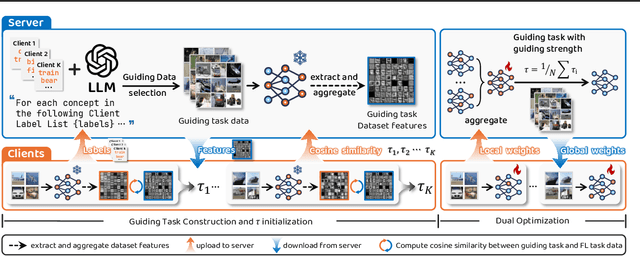
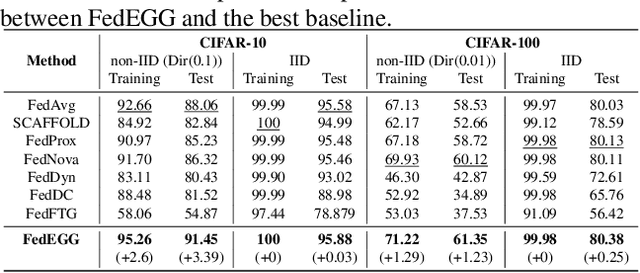
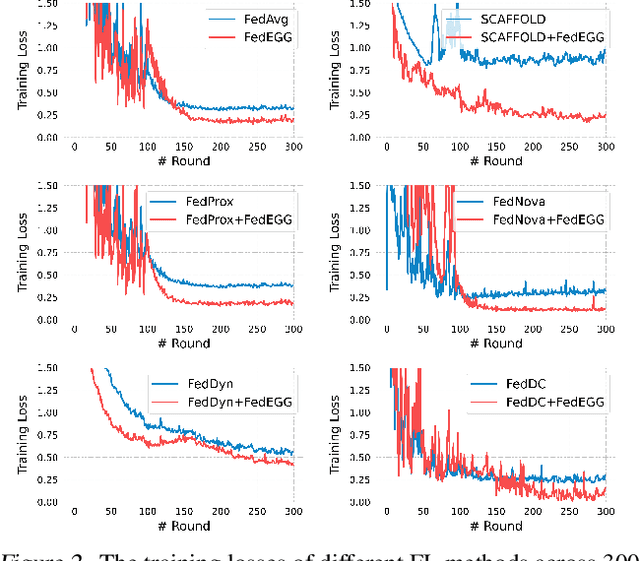
Federated learning (FL) is a collaborative learning paradigm that allows different clients to train one powerful global model without sharing their private data. Although FL has demonstrated promising results in various applications, it is known to suffer from convergence issues caused by the data distribution shift across different clients, especially on non-independent and identically distributed (non-IID) data. In this paper, we study the convergence of FL on non-IID data and propose a novel \emph{Dog Walking Theory} to formulate and identify the missing element in existing research. The Dog Walking Theory describes the process of a dog walker leash walking multiple dogs from one side of the park to the other. The goal of the dog walker is to arrive at the right destination while giving the dogs enough exercise (i.e., space exploration). In FL, the server is analogous to the dog walker while the clients are analogous to the dogs. This analogy allows us to identify one crucial yet missing element in existing FL algorithms: the leash that guides the exploration of the clients. To address this gap, we propose a novel FL algorithm \emph{FedWalk} that leverages an external easy-to-converge task at the server side as a \emph{leash task} to guide the local training of the clients. We theoretically analyze the convergence of FedWalk with respect to data heterogeneity (between server and clients) and task discrepancy (between the leash and the original tasks). Experiments on multiple benchmark datasets demonstrate the superiority of FedWalk over state-of-the-art FL methods under both IID and non-IID settings.
Byzantine-Robust Federated Learning via Credibility Assessment on Non-IID Data
Sep 06, 2021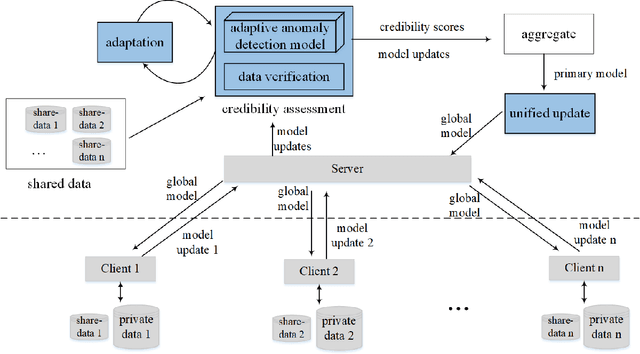
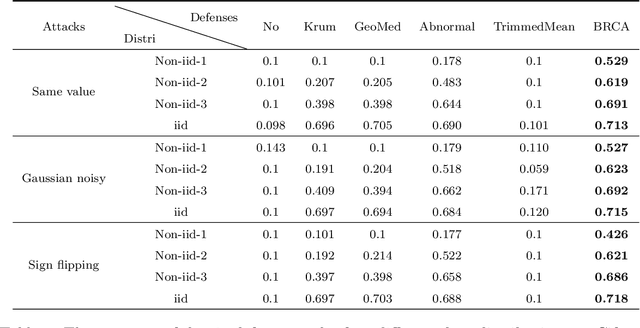
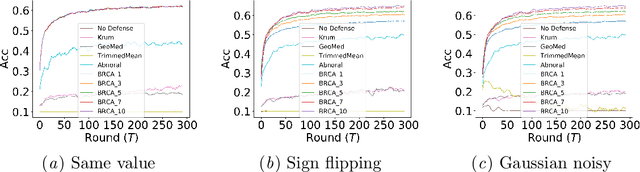
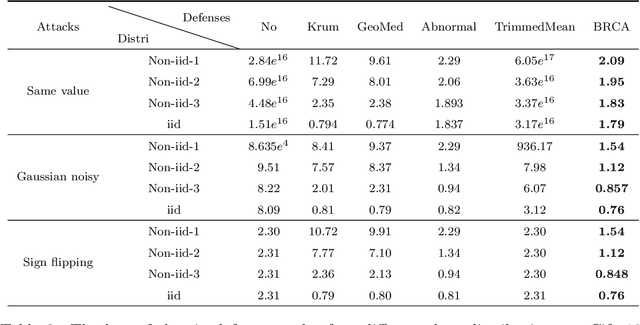
Federated learning is a novel framework that enables resource-constrained edge devices to jointly learn a model, which solves the problem of data protection and data islands. However, standard federated learning is vulnerable to Byzantine attacks, which will cause the global model to be manipulated by the attacker or fail to converge. On non-iid data, the current methods are not effective in defensing against Byzantine attacks. In this paper, we propose a Byzantine-robust framework for federated learning via credibility assessment on non-iid data (BRCA). Credibility assessment is designed to detect Byzantine attacks by combing adaptive anomaly detection model and data verification. Specially, an adaptive mechanism is incorporated into the anomaly detection model for the training and prediction of the model. Simultaneously, a unified update algorithm is given to guarantee that the global model has a consistent direction. On non-iid data, our experiments demonstrate that the BRCA is more robust to Byzantine attacks compared with conventional methods