 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive TTS Driven by Natural Language Prompts Using Few Human Annotations
Paper and Code
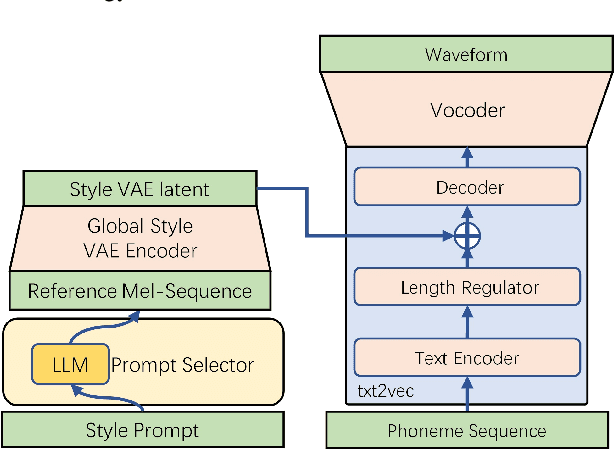
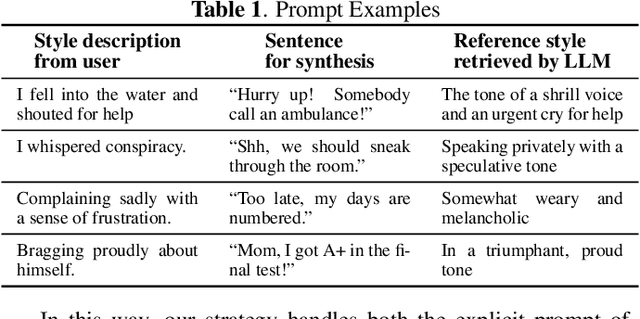


Expressive text-to-speech (TTS) aims to synthesize speeches with human-like tones, moods, or even artistic attributes. Recent advancements in expressive TTS empower users with the ability to directly control synthesis style through natural language prompts. However, these methods often require excessive training with a significant amount of style-annotated data, which can be challenging to acquire. Moreover, they may have limited adaptability due to fixed style annotations. In this work, we present FreeStyleTTS (FS-TTS), a controllable expressive TTS model with minimal human annotations. Our approach utilizes a large language model (LLM) to transform expressive TTS into a style retrieval task. The LLM selects the best-matching style references from annotated utterances based on external style prompts, which can be raw input text or natural language style descriptions. The selected reference guides the TTS pipeline to synthesize speeches with the intended style. This innovative approach provides flexible, versatile, and precise style control with minimal human workload. Experiments on a Mandarin storytelling corpus demonstrate FS-TTS's proficiency in leveraging LLM's semantic inference ability to retrieve desired styles from either input text or user-defined descriptions. This results in synthetic speeches that are closely aligned with the specified styles.