 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefTok: Reference-Based Tokenization for Video Generation
Jul 03, 2025Effectively handling temporal redundancy remains a key challenge in learning video models. Prevailing approaches often treat each set of frames independently, failing to effectively capture the temporal dependencies and redundancies inherent in videos. To address this limitation, we introduce RefTok, a novel reference-based tokenization method capable of capturing complex temporal dynamics and contextual information. Our method encodes and decodes sets of frames conditioned on an unquantized reference frame. When decoded, RefTok preserves the continuity of motion and the appearance of objects across frames. For example, RefTok retains facial details despite head motion, reconstructs text correctly, preserves small patterns, and maintains the legibility of handwriting from the context. Across 4 video datasets (K600, UCF-101, BAIR Robot Pushing, and DAVIS), RefTok significantly outperforms current state-of-the-art tokenizers (Cosmos and MAGVIT) and improves all evaluated metrics (PSNR, SSIM, LPIPS) by an average of 36.7% at the same or higher compression ratios. When a video generation model is trained using RefTok's latents on the BAIR Robot Pushing task, the generations not only outperform MAGVIT-B but the larger MAGVIT-L, which has 4x more parameters, across all generation metrics by an average of 27.9%.
Unlocking Temporal Flexibility: Neural Speech Codec with Variable Frame Rate
May 22, 2025Most neural speech codecs achieve bitrate adjustment through intra-frame mechanisms, such as codebook dropout, at a Constant Frame Rate (CFR). However, speech segments inherently have time-varying information density (e.g., silent intervals versus voiced regions). This property makes CFR not optimal in terms of bitrate and token sequence length, hindering efficiency in real-time applications. In this work, we propose a Temporally Flexible Coding (TFC) technique, introducing variable frame rate (VFR) into neural speech codecs for the first time. TFC enables seamlessly tunable average frame rates and dynamically allocates frame rates based on temporal entropy. Experimental results show that a codec with TFC achieves optimal reconstruction quality with high flexibility, and maintains competitive performance even at lower frame rates. Our approach is promising for the integration with other efforts to develop low-frame-rate neural speech codecs for more efficient downstream tasks.
NowYouSee Me: Context-Aware Automatic Audio Description
Dec 13, 2024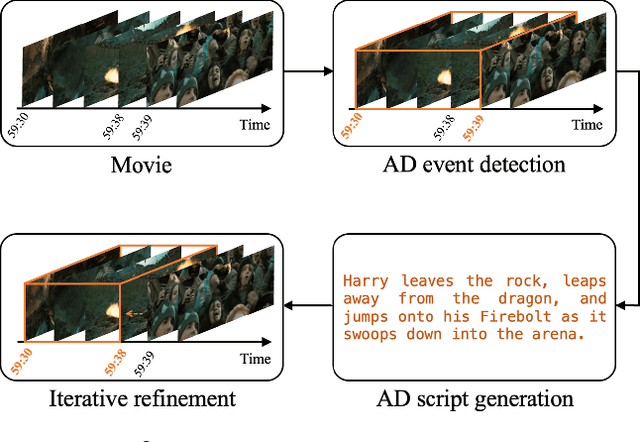
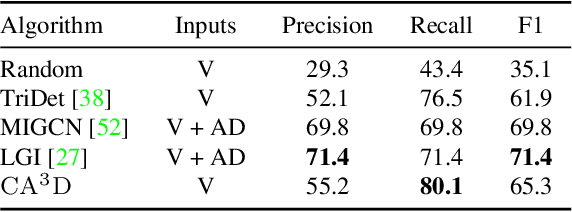
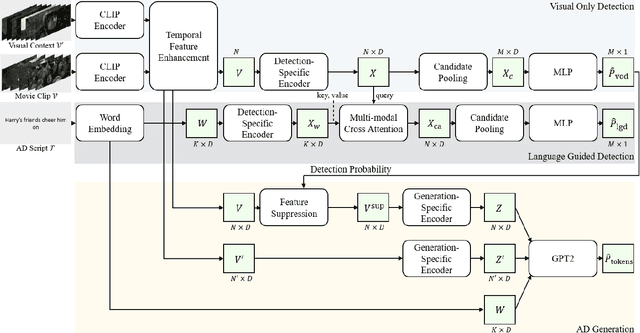

Audio Description (AD) plays a pivotal role as an application system aimed at guaranteeing accessibility in multimedia content, which provides additional narrations at suitable intervals to describe visual elements, catering specifically to the needs of visually impaired audiences. In this paper, we introduce $\mathrm{CA^3D}$, the pioneering unified Context-Aware Automatic Audio Description system that provides AD event scripts with precise locations in the long cinematic content. Specifically, $\mathrm{CA^3D}$ system consists of: 1) a Temporal Feature Enhancement Module to efficiently capture longer term dependencies, 2) an anchor-based AD event detector with feature suppression module that localizes the AD events and extracts discriminative feature for AD generation, and 3) a self-refinement module that leverages the generated output to tweak AD event boundaries from coarse to fine. Unlike conventional methods which rely on metadata and ground truth AD timestamp for AD detection and generation tasks, the proposed $\mathrm{CA^3D}$ is the first end-to-end trainable system that only uses visual cue. Extensive experiments demonstrate that the proposed $\mathrm{CA^3D}$ improves existing architectures for both AD event detection and script generation metrics, establishing the new state-of-the-art performances in the AD automation.
* 10 pages
GEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Dec 10, 2024
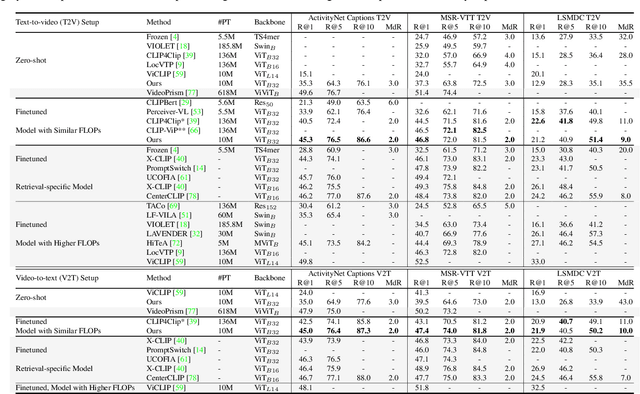
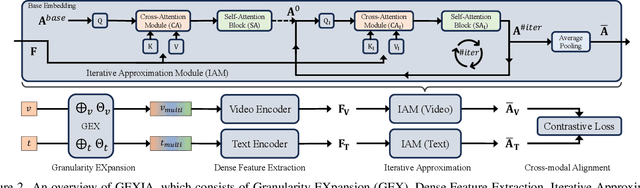
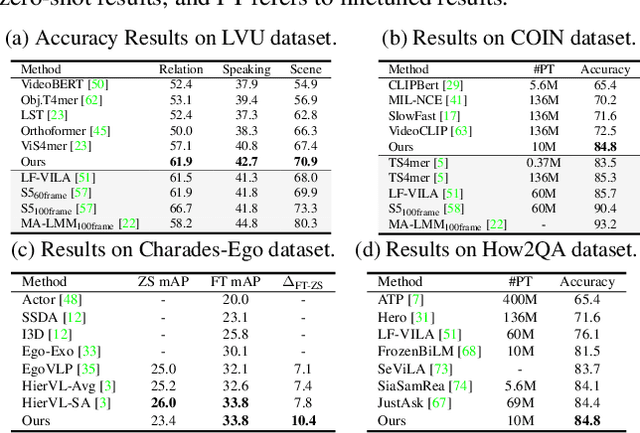
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.
Towards Ultra-Low-Power Neuromorphic Speech Enhancement with Spiking-FullSubNet
Oct 07, 2024



Speech enhancement is critical for improving speech intelligibility and quality in various audio devices. In recent years, deep learning-based methods have significantly improved speech enhancement performance, but they often come with a high computational cost, which is prohibitive for a large number of edge devices, such as headsets and hearing aids. This work proposes an ultra-low-power speech enhancement system based on the brain-inspired spiking neural network (SNN) called Spiking-FullSubNet. Spiking-FullSubNet follows a full-band and sub-band fusioned approach to effectively capture both global and local spectral information. To enhance the efficiency of computationally expensive sub-band modeling, we introduce a frequency partitioning method inspired by the sensitivity profile of the human peripheral auditory system. Furthermore, we introduce a novel spiking neuron model that can dynamically control the input information integration and forgetting, enhancing the multi-scale temporal processing capability of SNN, which is critical for speech denoising. Experiments conducted on the recent Intel Neuromorphic Deep Noise Suppression (N-DNS) Challenge dataset show that the Spiking-FullSubNet surpasses state-of-the-art methods by large margins in terms of both speech quality and energy efficiency metrics. Notably, our system won the championship of the Intel N-DNS Challenge (Algorithmic Track), opening up a myriad of opportunities for ultra-low-power speech enhancement at the edge. Our source code and model checkpoints are publicly available at https://github.com/haoxiangsnr/spiking-fullsubnet.
AI-Generated Content Enhanced Computer-Aided Diagnosis Model for Thyroid Nodules: A ChatGPT-Style Assistant
Feb 04, 2024An artificial intelligence-generated content-enhanced computer-aided diagnosis (AIGC-CAD) model, designated as ThyGPT, has been developed. This model, inspired by the architecture of ChatGPT, could assist radiologists in assessing the risk of thyroid nodules through semantic-level human-machine interaction. A dataset comprising 19,165 thyroid nodule ultrasound cases from Zhejiang Cancer Hospital was assembled to facilitate the training and validation of the model. After training, ThyGPT could automatically evaluate thyroid nodule and engage in effective communication with physicians through human-computer interaction. The performance of ThyGPT was rigorously quantified using established metrics such as the receiver operating characteristic (ROC) curve, area under the curve (AUC), sensitivity, and specificity. The empirical findings revealed that radiologists, when supplemented with ThyGPT, markedly surpassed the diagnostic acumen of their peers utilizing traditional methods as well as the performance of the model in isolation. These findings suggest that AIGC-CAD systems, exemplified by ThyGPT, hold the promise to fundamentally transform the diagnostic workflows of radiologists in forthcoming years.
Typing to Listen at the Cocktail Party: Text-Guided Target Speaker Extraction
Oct 15, 2023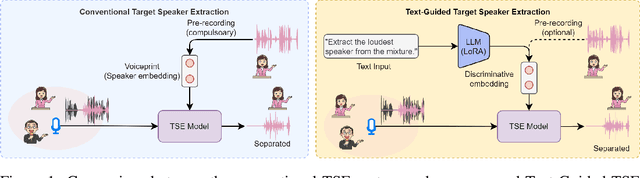
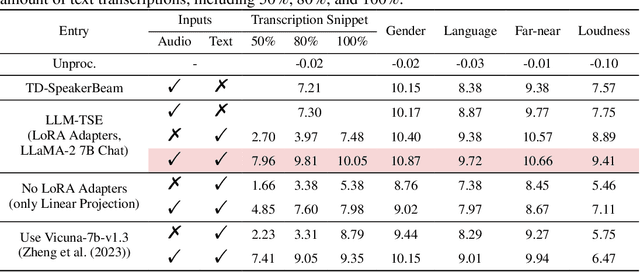
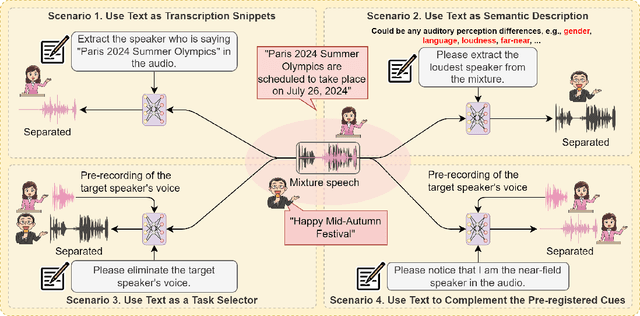
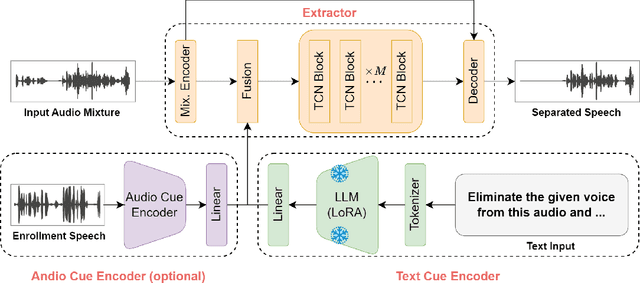
Humans possess an extraordinary ability to selectively focus on the sound source of interest amidst complex acoustic environments, commonly referred to as cocktail party scenarios. In an attempt to replicate this remarkable auditory attention capability in machines, target speaker extraction (TSE) models have been developed. These models leverage the pre-registered cues of the target speaker to extract the sound source of interest. However, the effectiveness of these models is hindered in real-world scenarios due to the unreliable or even absence of pre-registered cues. To address this limitation, this study investigates the integration of natural language description to enhance the feasibility, controllability, and performance of existing TSE models. Specifically, we propose a model named LLM-TSE, wherein a large language model (LLM) extracts useful semantic cues from the user's typed text input. These cues can serve as independent extraction cues, task selectors to control the TSE process or complement the pre-registered cues. Our experimental results demonstrate competitive performance when only text-based cues are presented, the effectiveness of using input text as a task selector, and a new state-of-the-art when combining text-based cues with pre-registered cues. To our knowledge, this is the first study to successfully incorporate LLMs to guide target speaker extraction, which can be a cornerstone for cocktail party problem research.
Pink-Eggs Dataset V1: A Step Toward Invasive Species Management Using Deep Learning Embedded Solutions
May 16, 2023
We introduce a novel dataset consisting of images depicting pink eggs that have been identified as Pomacea canaliculata eggs, accompanied by corresponding bounding box annotations. The purpose of this dataset is to aid researchers in the analysis of the spread of Pomacea canaliculata species by utilizing deep learning techniques, as well as supporting other investigative pursuits that require visual data pertaining to the eggs of Pomacea canaliculata. It is worth noting, however, that the identity of the eggs in question is not definitively established, as other species within the same taxonomic family have been observed to lay similar-looking eggs in regions of the Americas. Therefore, a crucial prerequisite to any decision regarding the elimination of these eggs would be to establish with certainty whether they are exclusively attributable to invasive Pomacea canaliculata or if other species are also involved. The dataset is available at https://www.kaggle.com/datasets/deeshenzhen/pinkeggs
Two-stage Neural Network for ICASSP 2023 Speech Signal Improvement Challenge
Mar 14, 2023

In ICASSP 2023 speech signal improvement challenge, we developed a dual-stage neural model which improves speech signal quality induced by different distortions in a stage-wise divide-and-conquer fashion. Specifically, in the first stage, the speech improvement network focuses on recovering the missing components of the spectrum, while in the second stage, our model aims to further suppress noise, reverberation, and artifacts introduced by the first-stage model. Achieving 0.446 in the final score and 0.517 in the P.835 score, our system ranks 4th in the non-real-time track.
Fast FullSubNet: Accelerate Full-band and Sub-band Fusion Model for Single-channel Speech Enhancement
Dec 18, 2022

FullSubNet is our recently proposed real-time single-channel speech enhancement network that achieves outstanding performance on the Deep Noise Suppression (DNS) Challenge dataset. A number of variants of FullSubNet have been proposed recently, but they all focus on the structure design towards better performance and are rarely concerned with computational efficiency. This work proposes a new architecture named Fast FullSubNet dedicated to accelerating the computation of FullSubNet. Specifically, Fast FullSubNet processes sub-band speech spectra in the mel-frequency domain by using cascaded linear-to-mel full-band, sub-band, and mel-to-linear full-band models such that frequencies involved in the sub-band computation are vastly reduced. After that, a down-sampling operation is proposed for the sub-band input sequence to further reduce the computational complexity along the time axis. Experimental results show that, compared to FullSubNet, Fast FullSubNet has only 13% computational complexity and 16% processing time, and achieves comparable or even better performance.