 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Token per Highly Selective Frame: Towards Extreme Compression for Long Video Understanding
Apr 16, 2026Long video understanding is inherently challenging for vision-language models (VLMs) because of the extensive number of frames. With each video frame typically expanding into tens or hundreds of tokens, the limited context length of large language models (LLMs) forces the VLMs to perceive the frames sparsely and lose temporal information. To address this, we explore extreme video token compression towards one token per frame at the final LLM layer. Our key insight is that heuristic-based compression, widely adopted by previous methods, is prone to information loss, and this necessitates supervising LLM layers into learnable and progressive modules for token-level compression (LP-Comp). Such compression enables our VLM to digest 2x-4x more frames with improved performance. To further increase the token efficiency, we investigate frame-level compression, which selects the frames most relevant to the queries via the internal attention scores of the LLM layers, named question-conditioned compression (QC-Comp). As a notable distinction from previous studies, we mitigate the position bias of LLM attention in long contexts, i.e., the over-concentration on the beginning and end of a sequence, by splitting long videos into short segments and employing local attention. Collectively, our combined token-level and frame-level leads to an extreme compression model for long video understanding, named XComp, achieving a significantly larger compression ratio and enabling denser frame sampling. Our XComp is finetuned from VideoChat-Flash with a data-efficient supervised compression tuning stage that only requires 2.5% of the supervised fine-tuning data, yet boosts the accuracy from 42.9% to 46.2% on LVBench and enhances multiple other long video benchmarks.
Scalable Temporal Localization of Sensitive Activities in Movies and TV Episodes
Jun 16, 2022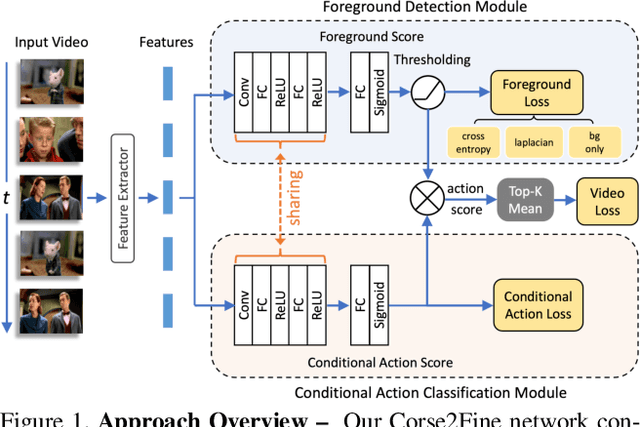
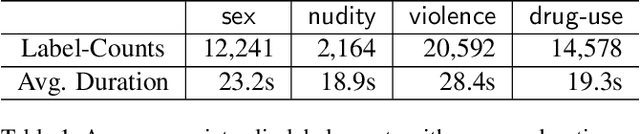


To help customers make better-informed viewing choices, video-streaming services try to moderate their content and provide more visibility into which portions of their movies and TV episodes contain age-appropriate material (e.g., nudity, sex, violence, or drug-use). Supervised models to localize these sensitive activities require large amounts of clip-level labeled data which is hard to obtain, while weakly-supervised models to this end usually do not offer competitive accuracy. To address this challenge, we propose a novel Coarse2Fine network designed to make use of readily obtainable video-level weak labels in conjunction with sparse clip-level labels of age-appropriate activities. Our model aggregates frame-level predictions to make video-level classifications and is therefore able to leverage sparse clip-level labels along with video-level labels. Furthermore, by performing frame-level predictions in a hierarchical manner, our approach is able to overcome the label-imbalance problem caused due to the rare-occurrence nature of age-appropriate content. We present comparative results of our approach using 41,234 movies and TV episodes (~3 years of video-content) from 521 sub-genres and 250 countries making it by far the largest-scale empirical analysis of age-appropriate activity localization in long-form videos ever published. Our approach offers 107.2% relative mAP improvement (from 5.5% to 11.4%) over existing state-of-the-art activity-localization approaches.
Robust Cross-Modal Representation Learning with Progressive Self-Distillation
Apr 10, 2022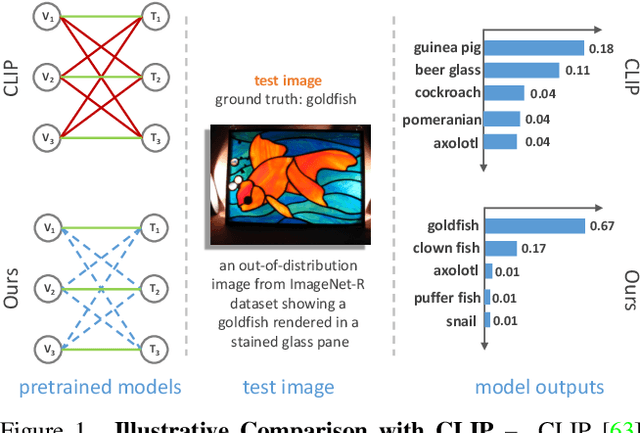

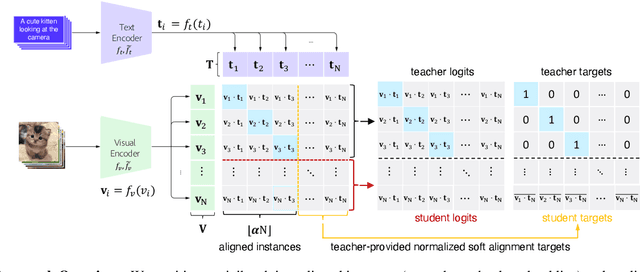
The learning objective of vision-language approach of CLIP does not effectively account for the noisy many-to-many correspondences found in web-harvested image captioning datasets, which contributes to its compute and data inefficiency. To address this challenge, we introduce a novel training framework based on cross-modal contrastive learning that uses progressive self-distillation and soft image-text alignments to more efficiently learn robust representations from noisy data. Our model distills its own knowledge to dynamically generate soft-alignment targets for a subset of images and captions in every minibatch, which are then used to update its parameters. Extensive evaluation across 14 benchmark datasets shows that our method consistently outperforms its CLIP counterpart in multiple settings, including: (a) zero-shot classification, (b) linear probe transfer, and (c) image-text retrieval, without incurring added computational cost. Analysis using an ImageNet-based robustness test-bed reveals that our method offers better effective robustness to natural distribution shifts compared to both ImageNet-trained models and CLIP itself. Lastly, pretraining with datasets spanning two orders of magnitude in size shows that our improvements over CLIP tend to scale with number of training examples.
Movies2Scenes: Learning Scene Representations Using Movie Similarities
Mar 12, 2022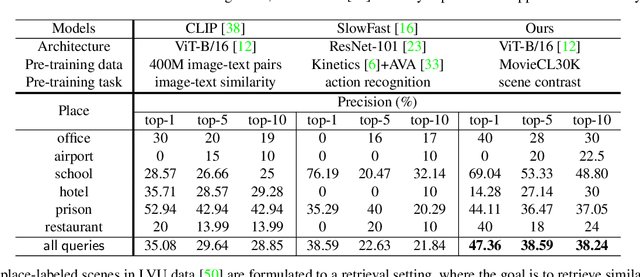
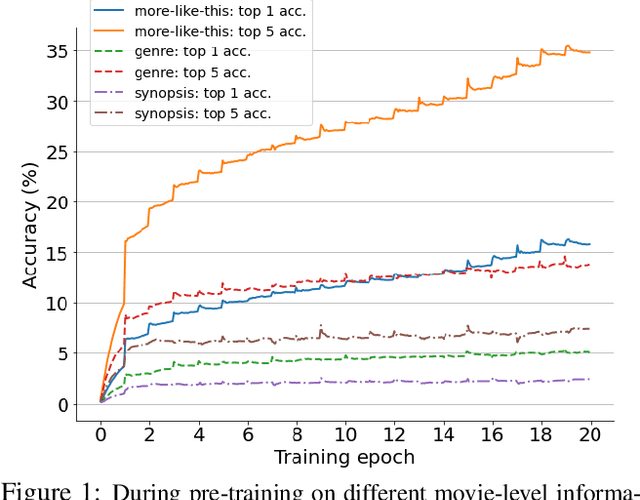
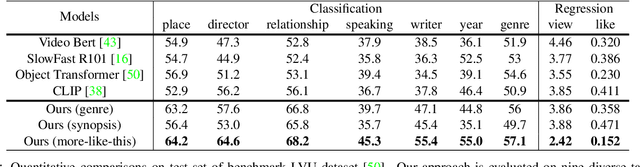
Labeling movie-scenes is a time-consuming process which makes applying end-to-end supervised methods for scene-understanding a challenging problem. Moreover, directly using image-based visual representations for scene-understanding tasks does not prove to be effective given the large gap between the two domains. To address these challenges, we propose a novel contrastive learning approach that uses commonly available movie-level information (e.g., co-watch, genre, synopsis) to learn a general-purpose scene-level representation. Our learned representation comfortably outperforms existing state-of-the-art approaches on eleven downstream tasks evaluated using multiple benchmark datasets. To further demonstrate generalizability of our learned representation, we present its comparative results on a set of video-moderation tasks evaluated using a newly collected large-scale internal movie dataset.
Shot Contrastive Self-Supervised Learning for Scene Boundary Detection
Apr 28, 2021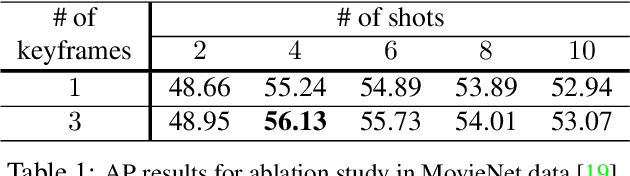
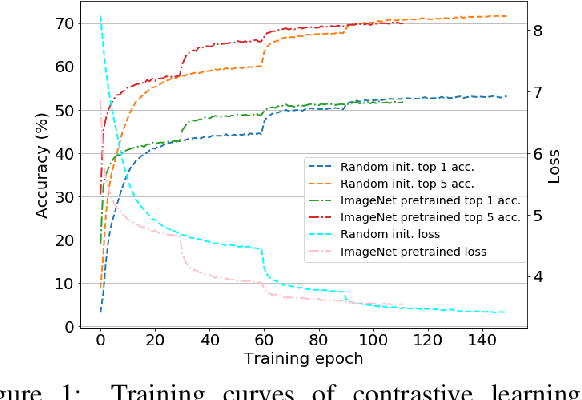

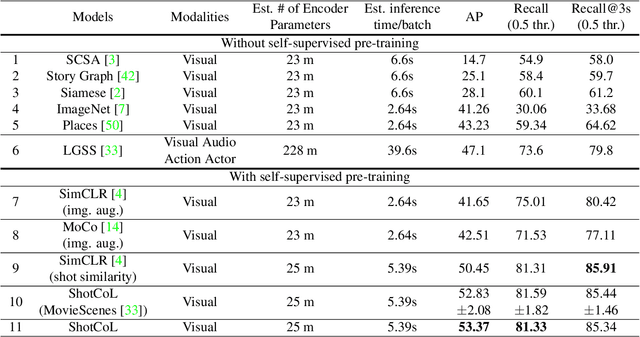
Scenes play a crucial role in breaking the storyline of movies and TV episodes into semantically cohesive parts. However, given their complex temporal structure, finding scene boundaries can be a challenging task requiring large amounts of labeled training data. To address this challenge, we present a self-supervised shot contrastive learning approach (ShotCoL) to learn a shot representation that maximizes the similarity between nearby shots compared to randomly selected shots. We show how to apply our learned shot representation for the task of scene boundary detection to offer state-of-the-art performance on the MovieNet dataset while requiring only ~25% of the training labels, using 9x fewer model parameters and offering 7x faster runtime. To assess the effectiveness of ShotCoL on novel applications of scene boundary detection, we take on the problem of finding timestamps in movies and TV episodes where video-ads can be inserted while offering a minimally disruptive viewing experience. To this end, we collected a new dataset called AdCuepoints with 3,975 movies and TV episodes, 2.2 million shots and 19,119 minimally disruptive ad cue-point labels. We present a thorough empirical analysis on this dataset demonstrating the effectiveness of ShotCoL for ad cue-points detection.