 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovies2Scenes: Learning Scene Representations Using Movie Similarities
Paper and Code
Mar 12, 2022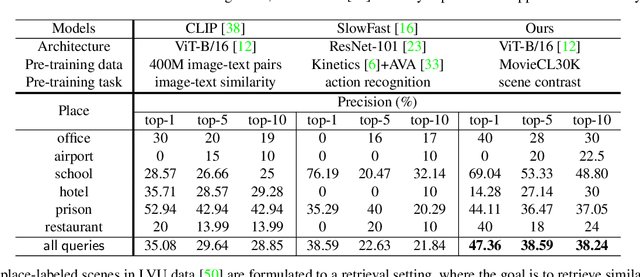
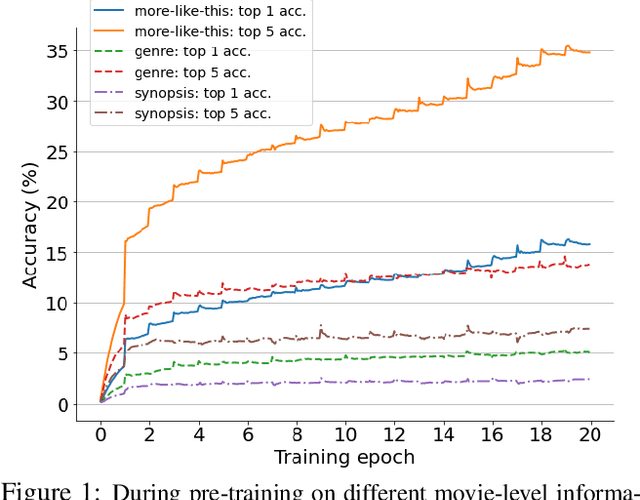
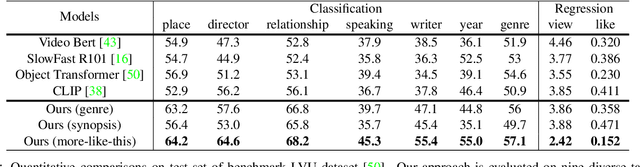
Labeling movie-scenes is a time-consuming process which makes applying end-to-end supervised methods for scene-understanding a challenging problem. Moreover, directly using image-based visual representations for scene-understanding tasks does not prove to be effective given the large gap between the two domains. To address these challenges, we propose a novel contrastive learning approach that uses commonly available movie-level information (e.g., co-watch, genre, synopsis) to learn a general-purpose scene-level representation. Our learned representation comfortably outperforms existing state-of-the-art approaches on eleven downstream tasks evaluated using multiple benchmark datasets. To further demonstrate generalizability of our learned representation, we present its comparative results on a set of video-moderation tasks evaluated using a newly collected large-scale internal movie dataset.