 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-LLM Based Video Frame Selection for Efficient Video Understanding
Feb 27, 2025Recent advances in Multi-Modal Large Language Models (M-LLMs) show promising results in video reasoning. Popular Multi-Modal Large Language Model (M-LLM) frameworks usually apply naive uniform sampling to reduce the number of video frames that are fed into an M-LLM, particularly for long context videos. However, it could lose crucial context in certain periods of a video, so that the downstream M-LLM may not have sufficient visual information to answer a question. To attack this pain point, we propose a light-weight M-LLM -based frame selection method that adaptively select frames that are more relevant to users' queries. In order to train the proposed frame selector, we introduce two supervision signals (i) Spatial signal, where single frame importance score by prompting a M-LLM; (ii) Temporal signal, in which multiple frames selection by prompting Large Language Model (LLM) using the captions of all frame candidates. The selected frames are then digested by a frozen downstream video M-LLM for visual reasoning and question answering. Empirical results show that the proposed M-LLM video frame selector improves the performances various downstream video Large Language Model (video-LLM) across medium (ActivityNet, NExT-QA) and long (EgoSchema, LongVideoBench) context video question answering benchmarks.
Multimodal Instruction Tuning with Hybrid State Space Models
Nov 13, 2024



Handling lengthy context is crucial for enhancing the recognition and understanding capabilities of multimodal large language models (MLLMs) in applications such as processing high-resolution images or high frame rate videos. The rise in image resolution and frame rate substantially increases computational demands due to the increased number of input tokens. This challenge is further exacerbated by the quadratic complexity with respect to sequence length of the self-attention mechanism. Most prior works either pre-train models with long contexts, overlooking the efficiency problem, or attempt to reduce the context length via downsampling (e.g., identify the key image patches or frames) to decrease the context length, which may result in information loss. To circumvent this issue while keeping the remarkable effectiveness of MLLMs, we propose a novel approach using a hybrid transformer-MAMBA model to efficiently handle long contexts in multimodal applications. Our multimodal model can effectively process long context input exceeding 100k tokens, outperforming existing models across various benchmarks. Remarkably, our model enhances inference efficiency for high-resolution images and high-frame-rate videos by about 4 times compared to current models, with efficiency gains increasing as image resolution or video frames rise. Furthermore, our model is the first to be trained on low-resolution images or low-frame-rate videos while being capable of inference on high-resolution images and high-frame-rate videos, offering flexibility for inference in diverse scenarios.
Depth-Guided Sparse Structure-from-Motion for Movies and TV Shows
Apr 05, 2022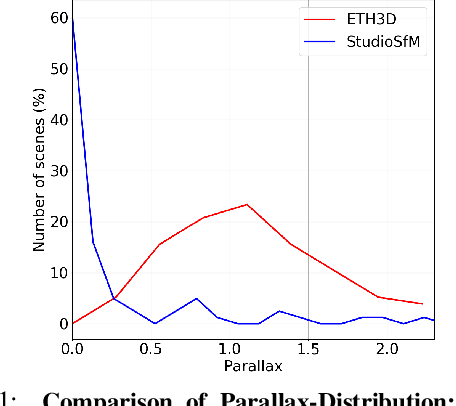
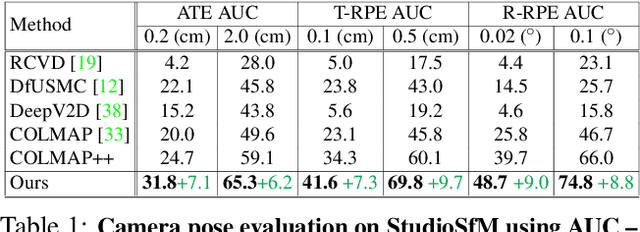
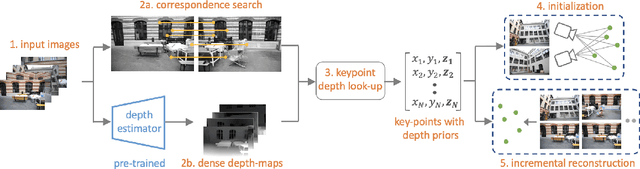
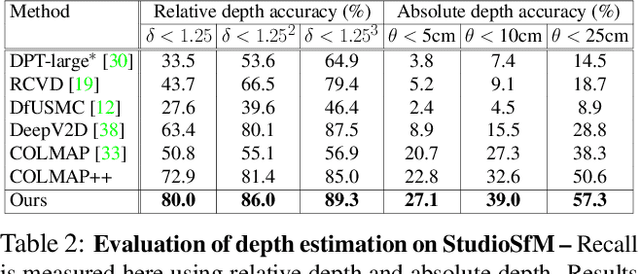
Existing approaches for Structure from Motion (SfM) produce impressive 3-D reconstruction results especially when using imagery captured with large parallax. However, to create engaging video-content in movies and TV shows, the amount by which a camera can be moved while filming a particular shot is often limited. The resulting small-motion parallax between video frames makes standard geometry-based SfM approaches not as effective for movies and TV shows. To address this challenge, we propose a simple yet effective approach that uses single-frame depth-prior obtained from a pretrained network to significantly improve geometry-based SfM for our small-parallax setting. To this end, we first use the depth-estimates of the detected keypoints to reconstruct the point cloud and camera-pose for initial two-view reconstruction. We then perform depth-regularized optimization to register new images and triangulate the new points during incremental reconstruction. To comprehensively evaluate our approach, we introduce a new dataset (StudioSfM) consisting of 130 shots with 21K frames from 15 studio-produced videos that are manually annotated by a professional CG studio. We demonstrate that our approach: (a) significantly improves the quality of 3-D reconstruction for our small-parallax setting, (b) does not cause any degradation for data with large-parallax, and (c) maintains the generalizability and scalability of geometry-based sparse SfM. Our dataset can be obtained at https://github.com/amazon-research/small-baseline-camera-tracking.
Movies2Scenes: Learning Scene Representations Using Movie Similarities
Mar 12, 2022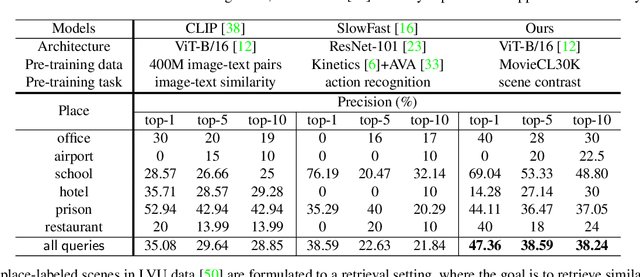
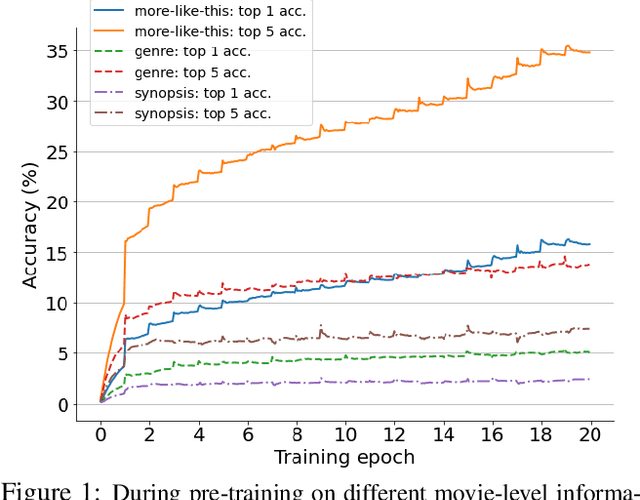
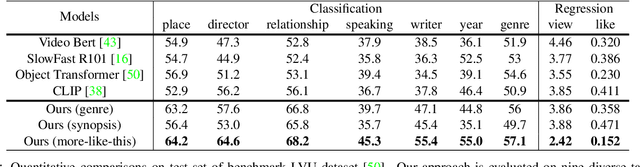
Labeling movie-scenes is a time-consuming process which makes applying end-to-end supervised methods for scene-understanding a challenging problem. Moreover, directly using image-based visual representations for scene-understanding tasks does not prove to be effective given the large gap between the two domains. To address these challenges, we propose a novel contrastive learning approach that uses commonly available movie-level information (e.g., co-watch, genre, synopsis) to learn a general-purpose scene-level representation. Our learned representation comfortably outperforms existing state-of-the-art approaches on eleven downstream tasks evaluated using multiple benchmark datasets. To further demonstrate generalizability of our learned representation, we present its comparative results on a set of video-moderation tasks evaluated using a newly collected large-scale internal movie dataset.
Shot Contrastive Self-Supervised Learning for Scene Boundary Detection
Apr 28, 2021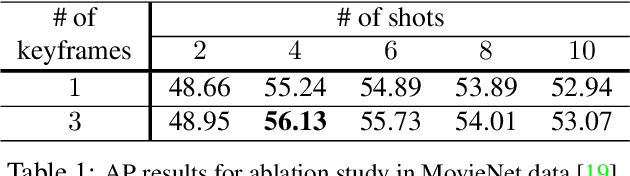
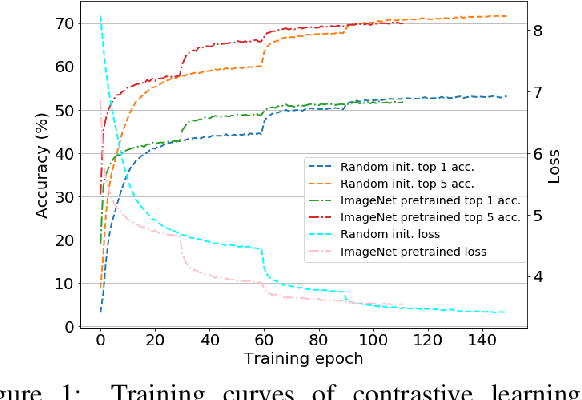

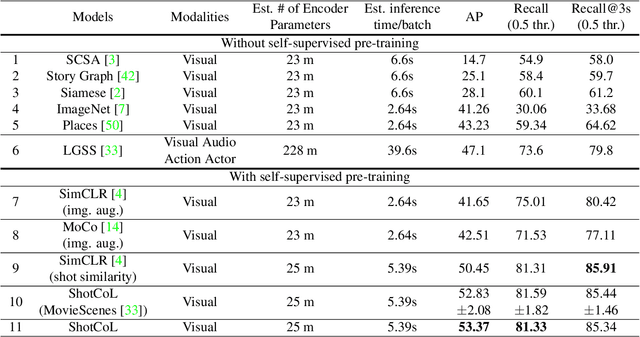
Scenes play a crucial role in breaking the storyline of movies and TV episodes into semantically cohesive parts. However, given their complex temporal structure, finding scene boundaries can be a challenging task requiring large amounts of labeled training data. To address this challenge, we present a self-supervised shot contrastive learning approach (ShotCoL) to learn a shot representation that maximizes the similarity between nearby shots compared to randomly selected shots. We show how to apply our learned shot representation for the task of scene boundary detection to offer state-of-the-art performance on the MovieNet dataset while requiring only ~25% of the training labels, using 9x fewer model parameters and offering 7x faster runtime. To assess the effectiveness of ShotCoL on novel applications of scene boundary detection, we take on the problem of finding timestamps in movies and TV episodes where video-ads can be inserted while offering a minimally disruptive viewing experience. To this end, we collected a new dataset called AdCuepoints with 3,975 movies and TV episodes, 2.2 million shots and 19,119 minimally disruptive ad cue-point labels. We present a thorough empirical analysis on this dataset demonstrating the effectiveness of ShotCoL for ad cue-points detection.
Cross-view Action Modeling, Learning and Recognition
May 12, 2014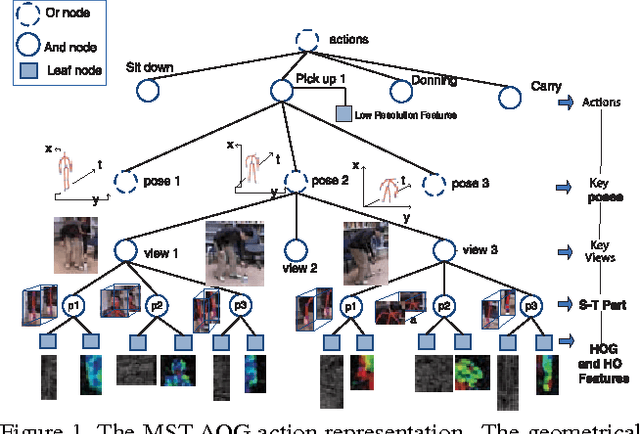
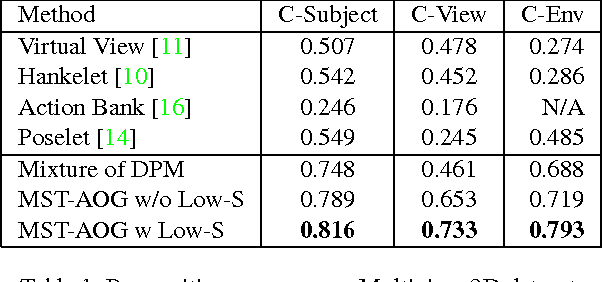
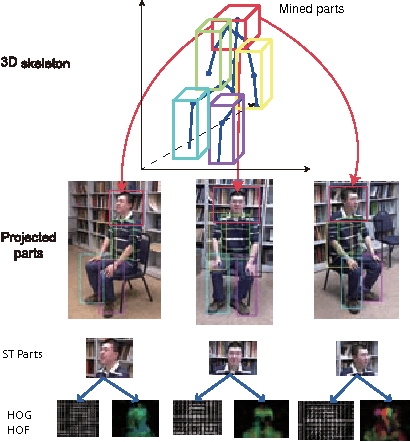

Existing methods on video-based action recognition are generally view-dependent, i.e., performing recognition from the same views seen in the training data. We present a novel multiview spatio-temporal AND-OR graph (MST-AOG) representation for cross-view action recognition, i.e., the recognition is performed on the video from an unknown and unseen view. As a compositional model, MST-AOG compactly represents the hierarchical combinatorial structures of cross-view actions by explicitly modeling the geometry, appearance and motion variations. This paper proposes effective methods to learn the structure and parameters of MST-AOG. The inference based on MST-AOG enables action recognition from novel views. The training of MST-AOG takes advantage of the 3D human skeleton data obtained from Kinect cameras to avoid annotating enormous multi-view video frames, which is error-prone and time-consuming, but the recognition does not need 3D information and is based on 2D video input. A new Multiview Action3D dataset has been created and will be released. Extensive experiments have demonstrated that this new action representation significantly improves the accuracy and robustness for cross-view action recognition on 2D videos.