 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Instruction Tuning with Hybrid State Space Models
Nov 13, 2024



Handling lengthy context is crucial for enhancing the recognition and understanding capabilities of multimodal large language models (MLLMs) in applications such as processing high-resolution images or high frame rate videos. The rise in image resolution and frame rate substantially increases computational demands due to the increased number of input tokens. This challenge is further exacerbated by the quadratic complexity with respect to sequence length of the self-attention mechanism. Most prior works either pre-train models with long contexts, overlooking the efficiency problem, or attempt to reduce the context length via downsampling (e.g., identify the key image patches or frames) to decrease the context length, which may result in information loss. To circumvent this issue while keeping the remarkable effectiveness of MLLMs, we propose a novel approach using a hybrid transformer-MAMBA model to efficiently handle long contexts in multimodal applications. Our multimodal model can effectively process long context input exceeding 100k tokens, outperforming existing models across various benchmarks. Remarkably, our model enhances inference efficiency for high-resolution images and high-frame-rate videos by about 4 times compared to current models, with efficiency gains increasing as image resolution or video frames rise. Furthermore, our model is the first to be trained on low-resolution images or low-frame-rate videos while being capable of inference on high-resolution images and high-frame-rate videos, offering flexibility for inference in diverse scenarios.
IEKG: A Commonsense Knowledge Graph for Idiomatic Expressions
Dec 11, 2023



Idiomatic expression (IE) processing and comprehension have challenged pre-trained language models (PTLMs) because their meanings are non-compositional. Unlike prior works that enable IE comprehension through fine-tuning PTLMs with sentences containing IEs, in this work, we construct IEKG, a commonsense knowledge graph for figurative interpretations of IEs. This extends the established ATOMIC2020 graph, converting PTLMs into knowledge models (KMs) that encode and infer commonsense knowledge related to IE use. Experiments show that various PTLMs can be converted into KMs with IEKG. We verify the quality of IEKG and the ability of the trained KMs with automatic and human evaluation. Through applications in natural language understanding, we show that a PTLM injected with knowledge from IEKG exhibits improved IE comprehension ability and can generalize to IEs unseen during training.
Idiomatic Expression Paraphrasing without Strong Supervision
Dec 16, 2021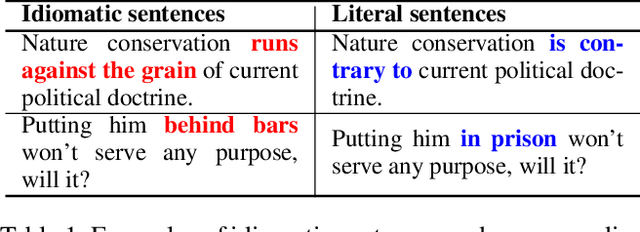
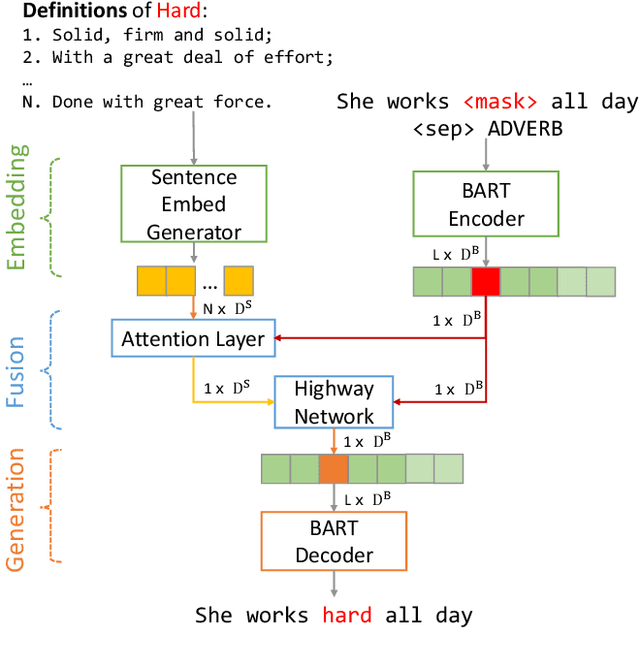
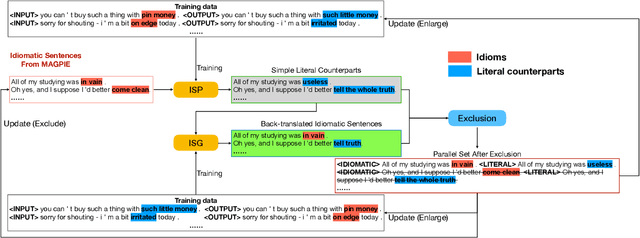
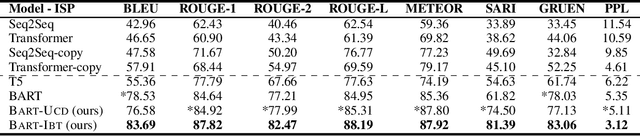
Idiomatic expressions (IEs) play an essential role in natural language. In this paper, we study the task of idiomatic sentence paraphrasing (ISP), which aims to paraphrase a sentence with an IE by replacing the IE with its literal paraphrase. The lack of large-scale corpora with idiomatic-literal parallel sentences is a primary challenge for this task, for which we consider two separate solutions. First, we propose an unsupervised approach to ISP, which leverages an IE's contextual information and definition and does not require a parallel sentence training set. Second, we propose a weakly supervised approach using back-translation to jointly perform paraphrasing and generation of sentences with IEs to enlarge the small-scale parallel sentence training dataset. Other significant derivatives of the study include a model that replaces a literal phrase in a sentence with an IE to generate an idiomatic expression and a large scale parallel dataset with idiomatic/literal sentence pairs. The effectiveness of the proposed solutions compared to competitive baselines is seen in the relative gains of over 5.16 points in BLEU, over 8.75 points in METEOR, and over 19.57 points in SARI when the generated sentences are empirically validated on a parallel dataset using automatic and manual evaluations. We demonstrate the practical utility of ISP as a preprocessing step in En-De machine translation.
From Solving a Problem Boldly to Cutting the Gordian Knot: Idiomatic Text Generation
May 11, 2021
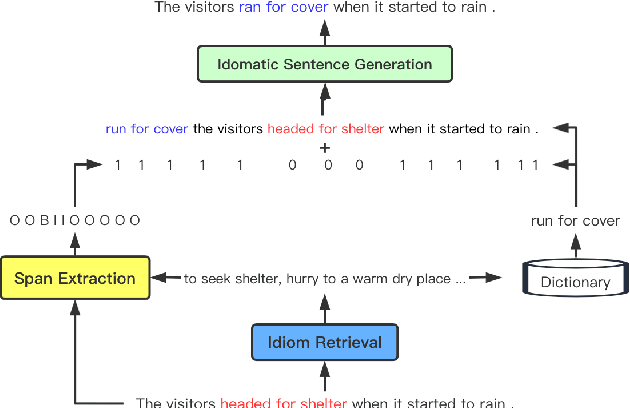
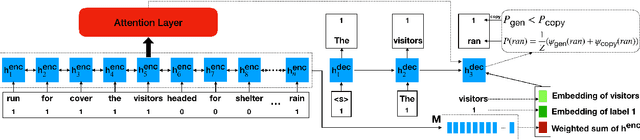
We study a new application for text generation -- idiomatic sentence generation -- which aims to transfer literal phrases in sentences into their idiomatic counterparts. Inspired by psycholinguistic theories of idiom use in one's native language, we propose a novel approach for this task, which retrieves the appropriate idiom for a given literal sentence, extracts the span of the sentence to be replaced by the idiom, and generates the idiomatic sentence by using a neural model to combine the retrieved idiom and the remainder of the sentence. Experiments on a novel dataset created for this task show that our model is able to effectively transfer literal sentences into idiomatic ones. Furthermore, automatic and human evaluations show that for this task, the proposed model outperforms a series of competitive baseline models for text generation.
Multiple Character Embeddings for Chinese Word Segmentation
Oct 02, 2018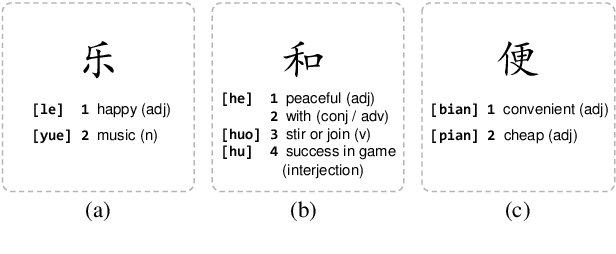
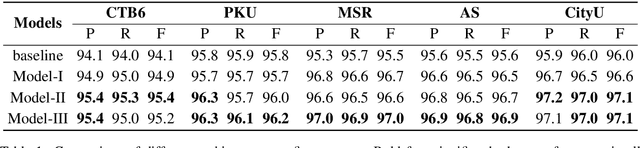
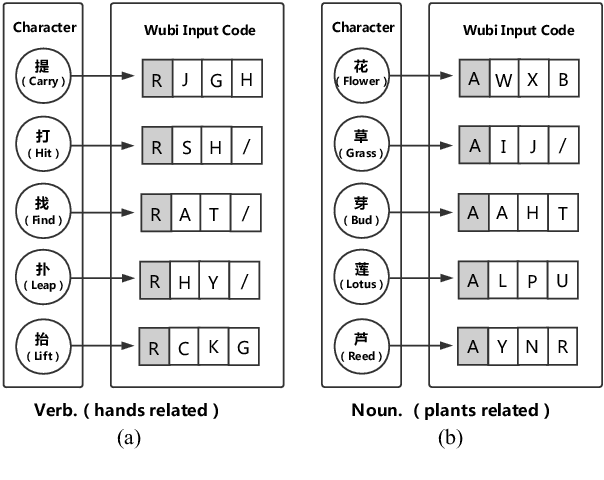
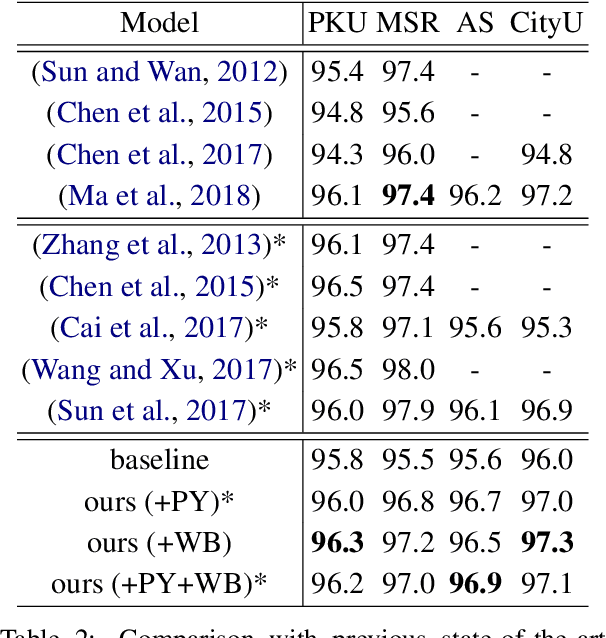
Chinese word segmentation (CWS) is often regarded as a character-based sequence labeling task in most current works which have achieved great performance by leveraging powerful neural networks. However, these works neglect an important clue: Chinese characters contain both semantic and phonetic meanings. In this paper, we introduce multiple character embeddings including Pinyin Romanization and Wubi Input, both of which are easily accessible and effective in depicting semantics of characters. To fully leverage them, we propose a novel shared Bi-LSTM-CRF model, which fuses multiple features efficiently. Extensive experiments on five corpora demonstrate that extra embeddings help obtain a significant improvement. Specifically, we achieve the state-of-the-art performance in AS and CityU datasets with F1 scores 96.9 and 97.3, respectively without leveraging any external resources.