 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIEKG: A Commonsense Knowledge Graph for Idiomatic Expressions
Dec 11, 2023



Idiomatic expression (IE) processing and comprehension have challenged pre-trained language models (PTLMs) because their meanings are non-compositional. Unlike prior works that enable IE comprehension through fine-tuning PTLMs with sentences containing IEs, in this work, we construct IEKG, a commonsense knowledge graph for figurative interpretations of IEs. This extends the established ATOMIC2020 graph, converting PTLMs into knowledge models (KMs) that encode and infer commonsense knowledge related to IE use. Experiments show that various PTLMs can be converted into KMs with IEKG. We verify the quality of IEKG and the ability of the trained KMs with automatic and human evaluation. Through applications in natural language understanding, we show that a PTLM injected with knowledge from IEKG exhibits improved IE comprehension ability and can generalize to IEs unseen during training.
Unified Representation for Non-compositional and Compositional Expressions
Oct 29, 2023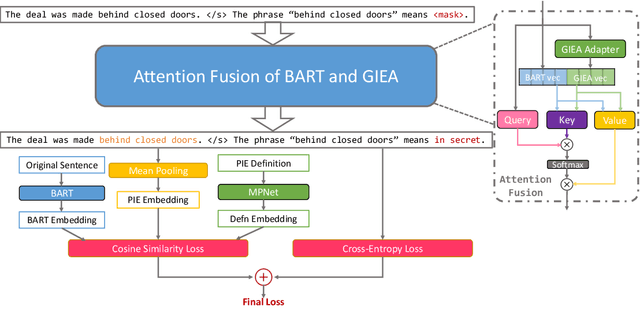



Accurate processing of non-compositional language relies on generating good representations for such expressions. In this work, we study the representation of language non-compositionality by proposing a language model, PIER, that builds on BART and can create semantically meaningful and contextually appropriate representations for English potentially idiomatic expressions (PIEs). PIEs are characterized by their non-compositionality and contextual ambiguity in their literal and idiomatic interpretations. Via intrinsic evaluation on embedding quality and extrinsic evaluation on PIE processing and NLU tasks, we show that representations generated by PIER result in 33% higher homogeneity score for embedding clustering than BART, whereas 3.12% and 3.29% gains in accuracy and sequence accuracy for PIE sense classification and span detection compared to the state-of-the-art IE representation model, GIEA. These gains are achieved without sacrificing PIER's performance on NLU tasks (+/- 1% accuracy) compared to BART.
Getting BART to Ride the Idiomatic Train: Learning to Represent Idiomatic Expressions
Jul 08, 2022
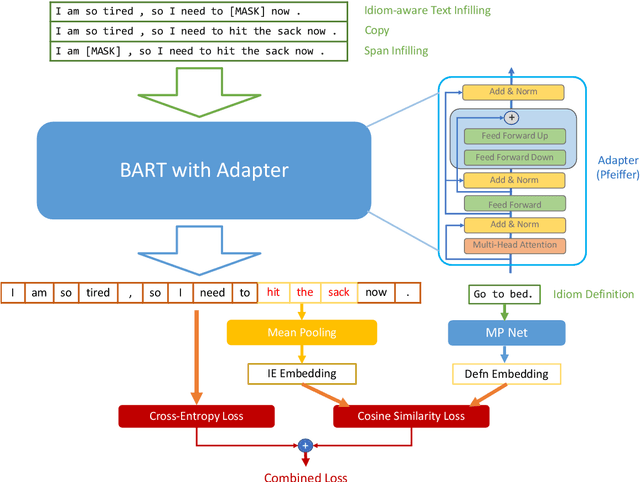
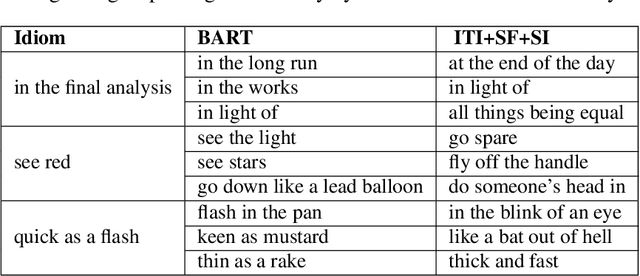
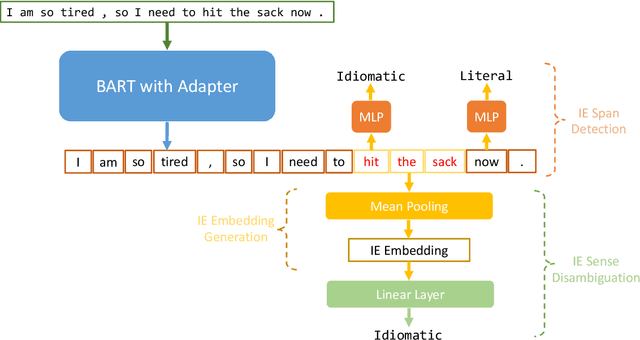
Idiomatic expressions (IEs), characterized by their non-compositionality, are an important part of natural language. They have been a classical challenge to NLP, including pre-trained language models that drive today's state-of-the-art. Prior work has identified deficiencies in their contextualized representation stemming from the underlying compositional paradigm of representation. In this work, we take a first-principles approach to build idiomaticity into BART using an adapter as a lightweight non-compositional language expert trained on idiomatic sentences. The improved capability over baselines (e.g., BART) is seen via intrinsic and extrinsic methods, where idiom embeddings score 0.19 points higher in homogeneity score for embedding clustering, and up to 25% higher sequence accuracy on the idiom processing tasks of IE sense disambiguation and span detection.
Idiomatic Expression Paraphrasing without Strong Supervision
Dec 16, 2021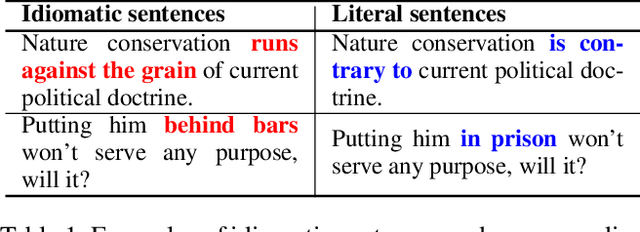
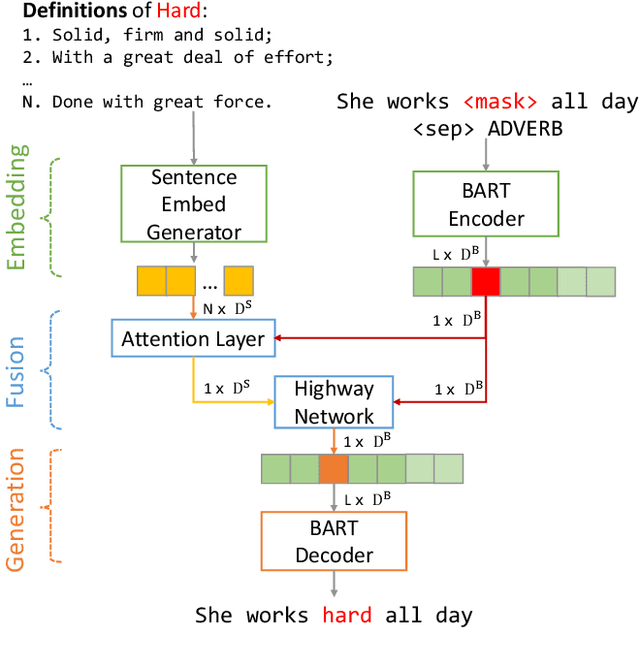
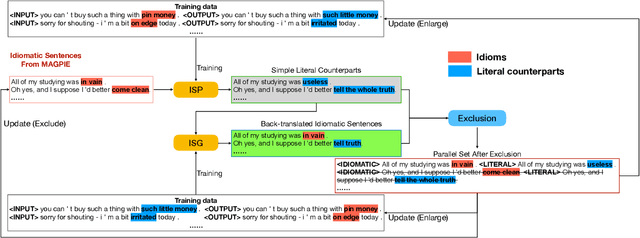
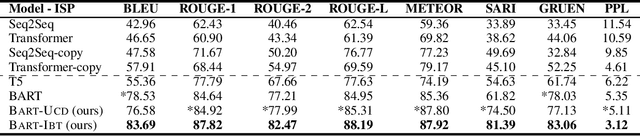
Idiomatic expressions (IEs) play an essential role in natural language. In this paper, we study the task of idiomatic sentence paraphrasing (ISP), which aims to paraphrase a sentence with an IE by replacing the IE with its literal paraphrase. The lack of large-scale corpora with idiomatic-literal parallel sentences is a primary challenge for this task, for which we consider two separate solutions. First, we propose an unsupervised approach to ISP, which leverages an IE's contextual information and definition and does not require a parallel sentence training set. Second, we propose a weakly supervised approach using back-translation to jointly perform paraphrasing and generation of sentences with IEs to enlarge the small-scale parallel sentence training dataset. Other significant derivatives of the study include a model that replaces a literal phrase in a sentence with an IE to generate an idiomatic expression and a large scale parallel dataset with idiomatic/literal sentence pairs. The effectiveness of the proposed solutions compared to competitive baselines is seen in the relative gains of over 5.16 points in BLEU, over 8.75 points in METEOR, and over 19.57 points in SARI when the generated sentences are empirically validated on a parallel dataset using automatic and manual evaluations. We demonstrate the practical utility of ISP as a preprocessing step in En-De machine translation.
Idiomatic Expression Identification using Semantic Compatibility
Oct 19, 2021
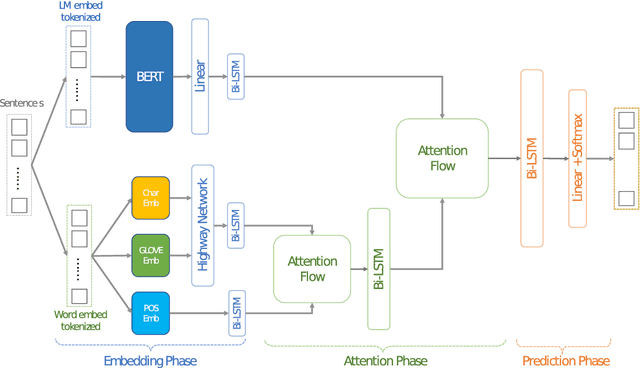
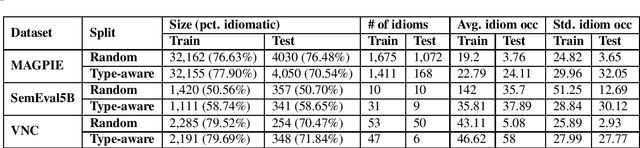
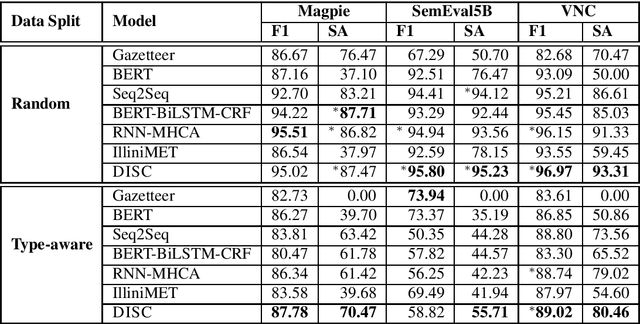
Idiomatic expressions are an integral part of natural language and constantly being added to a language. Owing to their non-compositionality and their ability to take on a figurative or literal meaning depending on the sentential context, they have been a classical challenge for NLP systems. To address this challenge, we study the task of detecting whether a sentence has an idiomatic expression and localizing it. Prior art for this task had studied specific classes of idiomatic expressions offering limited views of their generalizability to new idioms. We propose a multi-stage neural architecture with the attention flow mechanism for identifying these expressions. The network effectively fuses contextual and lexical information at different levels using word and sub-word representations. Empirical evaluations on three of the largest benchmark datasets with idiomatic expressions of varied syntactic patterns and degrees of non-compositionality show that our proposed model achieves new state-of-the-art results. A salient feature of the model is its ability to identify idioms unseen during training with gains from 1.4% to 30.8% over competitive baselines on the largest dataset.
Recurrent Inference in Text Editing
Sep 30, 2020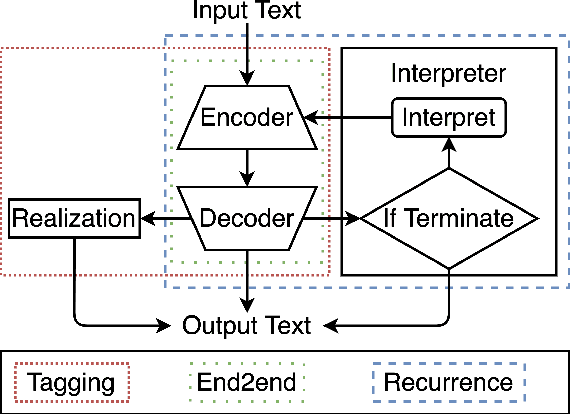
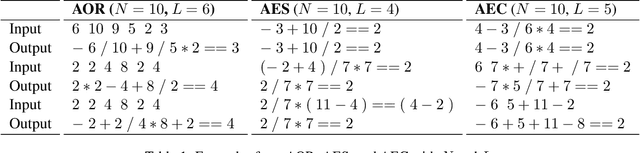
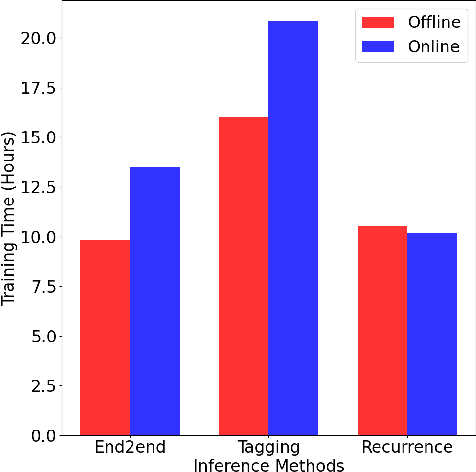
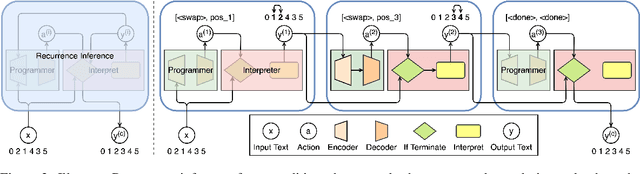
In neural text editing, prevalent sequence-to-sequence based approaches directly map the unedited text either to the edited text or the editing operations, in which the performance is degraded by the limited source text encoding and long, varying decoding steps. To address this problem, we propose a new inference method, Recurrence, that iteratively performs editing actions, significantly narrowing the problem space. In each iteration, encoding the partially edited text, Recurrence decodes the latent representation, generates an action of short, fixed-length, and applies the action to complete a single edit. For a comprehensive comparison, we introduce three types of text editing tasks: Arithmetic Operators Restoration (AOR), Arithmetic Equation Simplification (AES), Arithmetic Equation Correction (AEC). Extensive experiments on these tasks with varying difficulties demonstrate that Recurrence achieves improvements over conventional inference methods.
* 12 pages, 4 figures, 3 tables, and 1 page appendix