 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Consistency in Multimodal Large Language Models
Nov 14, 2024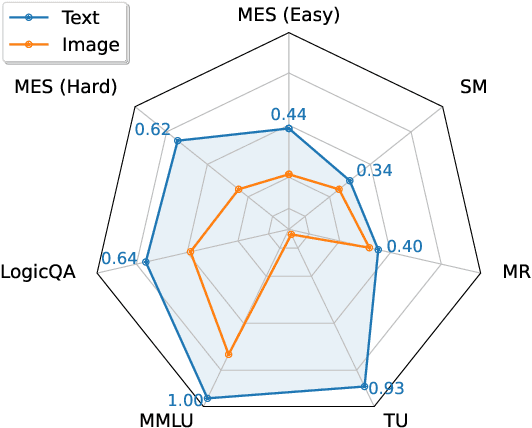



Recent developments in multimodal methodologies have marked the beginning of an exciting era for models adept at processing diverse data types, encompassing text, audio, and visual content. Models like GPT-4V, which merge computer vision with advanced language processing, exhibit extraordinary proficiency in handling intricate tasks that require a simultaneous understanding of both textual and visual information. Prior research efforts have meticulously evaluated the efficacy of these Vision Large Language Models (VLLMs) in various domains, including object detection, image captioning, and other related fields. However, existing analyses have often suffered from limitations, primarily centering on the isolated evaluation of each modality's performance while neglecting to explore their intricate cross-modal interactions. Specifically, the question of whether these models achieve the same level of accuracy when confronted with identical task instances across different modalities remains unanswered. In this study, we take the initiative to delve into the interaction and comparison among these modalities of interest by introducing a novel concept termed cross-modal consistency. Furthermore, we propose a quantitative evaluation framework founded on this concept. Our experimental findings, drawn from a curated collection of parallel vision-language datasets developed by us, unveil a pronounced inconsistency between the vision and language modalities within GPT-4V, despite its portrayal as a unified multimodal model. Our research yields insights into the appropriate utilization of such models and hints at potential avenues for enhancing their design.
MIO: A Foundation Model on Multimodal Tokens
Sep 26, 2024

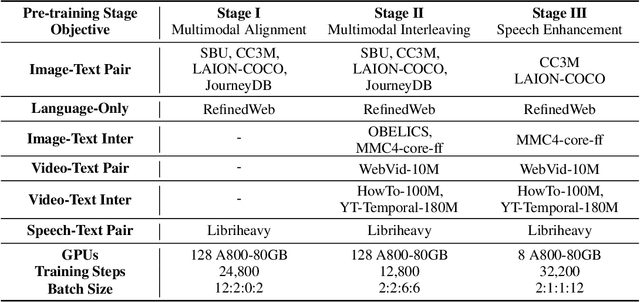

In this paper, we introduce MIO, a novel foundation model built on multimodal tokens, capable of understanding and generating speech, text, images, and videos in an end-to-end, autoregressive manner. While the emergence of large language models (LLMs) and multimodal large language models (MM-LLMs) propels advancements in artificial general intelligence through their versatile capabilities, they still lack true any-to-any understanding and generation. Recently, the release of GPT-4o has showcased the remarkable potential of any-to-any LLMs for complex real-world tasks, enabling omnidirectional input and output across images, speech, and text. However, it is closed-source and does not support the generation of multimodal interleaved sequences. To address this gap, we present MIO, which is trained on a mixture of discrete tokens across four modalities using causal multimodal modeling. MIO undergoes a four-stage training process: (1) alignment pre-training, (2) interleaved pre-training, (3) speech-enhanced pre-training, and (4) comprehensive supervised fine-tuning on diverse textual, visual, and speech tasks. Our experimental results indicate that MIO exhibits competitive, and in some cases superior, performance compared to previous dual-modal baselines, any-to-any model baselines, and even modality-specific baselines. Moreover, MIO demonstrates advanced capabilities inherent to its any-to-any feature, such as interleaved video-text generation, chain-of-visual-thought reasoning, visual guideline generation, instructional image editing, etc.
Action Controlled Paraphrasing
May 18, 2024



Recent studies have demonstrated the potential to control paraphrase generation, such as through syntax, which has broad applications in various downstream tasks. However, these methods often require detailed parse trees or syntactic exemplars, which are not user-friendly. Furthermore, an inference gap exists, as control specifications are only available during training but not inference. In this work, we propose a new setup for controlled paraphrasing. Specifically, we represent user-intended actions as action tokens, allowing embedding and concatenating them with text embeddings, thus flowing together to a self-attention encoder for representation fusion. To address the inference gap, we introduce an optional action token as a placeholder that encourages the model to determine the appropriate action when control specifications are inaccessible. Experimental results show that our method successfully enables specific action-controlled paraphrasing and preserves the same or even better performance compared to conventional uncontrolled methods when actions are not given. Our findings thus promote the concept of optional action control for a more user-centered design via representation learning.
Optimizing Negative Prompts for Enhanced Aesthetics and Fidelity in Text-To-Image Generation
Mar 12, 2024

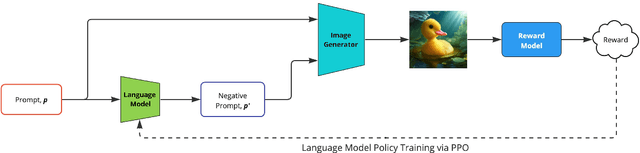

In text-to-image generation, using negative prompts, which describe undesirable image characteristics, can significantly boost image quality. However, producing good negative prompts is manual and tedious. To address this, we propose NegOpt, a novel method for optimizing negative prompt generation toward enhanced image generation, using supervised fine-tuning and reinforcement learning. Our combined approach results in a substantial increase of 25% in Inception Score compared to other approaches and surpasses ground-truth negative prompts from the test set. Furthermore, with NegOpt we can preferentially optimize the metrics most important to us. Finally, we construct Negative Prompts DB, a dataset of negative prompts.
Lost in Translation: When GPT-4V Can't See Eye to Eye with Text. A Vision-Language-Consistency Analysis of VLLMs and Beyond
Oct 19, 2023Recent advancements in multimodal techniques open exciting possibilities for models excelling in diverse tasks involving text, audio, and image processing. Models like GPT-4V, blending computer vision and language modeling, excel in complex text and image tasks. Numerous prior research endeavors have diligently examined the performance of these Vision Large Language Models (VLLMs) across tasks like object detection, image captioning and others. However, these analyses often focus on evaluating the performance of each modality in isolation, lacking insights into their cross-modal interactions. Specifically, questions concerning whether these vision-language models execute vision and language tasks consistently or independently have remained unanswered. In this study, we draw inspiration from recent investigations into multilingualism and conduct a comprehensive analysis of model's cross-modal interactions. We introduce a systematic framework that quantifies the capability disparities between different modalities in the multi-modal setting and provide a set of datasets designed for these evaluations. Our findings reveal that models like GPT-4V tend to perform consistently modalities when the tasks are relatively simple. However, the trustworthiness of results derived from the vision modality diminishes as the tasks become more challenging. Expanding on our findings, we introduce "Vision Description Prompting," a method that effectively improves performance in challenging vision-related tasks.
UAlberta at SemEval-2023 Task 1: Context Augmentation and Translation for Multilingual Visual Word Sense Disambiguation
Jun 24, 2023



We describe the systems of the University of Alberta team for the SemEval-2023 Visual Word Sense Disambiguation (V-WSD) Task. We present a novel algorithm that leverages glosses retrieved from BabelNet, in combination with text and image encoders. Furthermore, we compare language-specific encoders against the application of English encoders to translated texts. As the contexts given in the task datasets are extremely short, we also experiment with augmenting these contexts with descriptions generated by a language model. This yields substantial improvements in accuracy. We describe and evaluate additional V-WSD methods which use image generation and text-conditioned image segmentation. Overall, the results of our official submission rank us 18 out of 56 teams. Some of our unofficial results are even better than the official ones. Our code is publicly available at https://github.com/UAlberta-NLP/v-wsd.
From Adversarial Arms Race to Model-centric Evaluation: Motivating a Unified Automatic Robustness Evaluation Framework
May 29, 2023



Textual adversarial attacks can discover models' weaknesses by adding semantic-preserved but misleading perturbations to the inputs. The long-lasting adversarial attack-and-defense arms race in Natural Language Processing (NLP) is algorithm-centric, providing valuable techniques for automatic robustness evaluation. However, the existing practice of robustness evaluation may exhibit issues of incomprehensive evaluation, impractical evaluation protocol, and invalid adversarial samples. In this paper, we aim to set up a unified automatic robustness evaluation framework, shifting towards model-centric evaluation to further exploit the advantages of adversarial attacks. To address the above challenges, we first determine robustness evaluation dimensions based on model capabilities and specify the reasonable algorithm to generate adversarial samples for each dimension. Then we establish the evaluation protocol, including evaluation settings and metrics, under realistic demands. Finally, we use the perturbation degree of adversarial samples to control the sample validity. We implement a toolkit RobTest that realizes our automatic robustness evaluation framework. In our experiments, we conduct a robustness evaluation of RoBERTa models to demonstrate the effectiveness of our evaluation framework, and further show the rationality of each component in the framework. The code will be made public at \url{https://github.com/thunlp/RobTest}.
Don't Trust GPT When Your Question Is Not In English
May 24, 2023



Large Language Models (LLMs) have demonstrated exceptional natural language understanding abilities and have excelled in a variety of natural language processing (NLP)tasks in recent years. Despite the fact that most LLMs are trained predominantly in English, multiple studies have demonstrated their comparative performance in many other languages. However, fundamental questions persist regarding how LLMs acquire their multi-lingual abilities and how performance varies across different languages. These inquiries are crucial for the study of LLMs since users and researchers often come from diverse language backgrounds, potentially influencing their utilization and interpretation of LLMs' results. In this work, we propose a systematic way of qualifying the performance disparities of LLMs under multilingual settings. We investigate the phenomenon of across-language generalizations in LLMs, wherein insufficient multi-lingual training data leads to advanced multi-lingual capabilities. To accomplish this, we employ a novel back-translation-based prompting method. The results show that GPT exhibits highly translating-like behaviour in multilingual settings.
Interactive Natural Language Processing
May 22, 2023



Interactive Natural Language Processing (iNLP) has emerged as a novel paradigm within the field of NLP, aimed at addressing limitations in existing frameworks while aligning with the ultimate goals of artificial intelligence. This paradigm considers language models as agents capable of observing, acting, and receiving feedback iteratively from external entities. Specifically, language models in this context can: (1) interact with humans for better understanding and addressing user needs, personalizing responses, aligning with human values, and improving the overall user experience; (2) interact with knowledge bases for enriching language representations with factual knowledge, enhancing the contextual relevance of responses, and dynamically leveraging external information to generate more accurate and informed responses; (3) interact with models and tools for effectively decomposing and addressing complex tasks, leveraging specialized expertise for specific subtasks, and fostering the simulation of social behaviors; and (4) interact with environments for learning grounded representations of language, and effectively tackling embodied tasks such as reasoning, planning, and decision-making in response to environmental observations. This paper offers a comprehensive survey of iNLP, starting by proposing a unified definition and framework of the concept. We then provide a systematic classification of iNLP, dissecting its various components, including interactive objects, interaction interfaces, and interaction methods. We proceed to delve into the evaluation methodologies used in the field, explore its diverse applications, scrutinize its ethical and safety issues, and discuss prospective research directions. This survey serves as an entry point for researchers who are interested in this rapidly evolving area and offers a broad view of the current landscape and future trajectory of iNLP.
RoChBert: Towards Robust BERT Fine-tuning for Chinese
Oct 28, 2022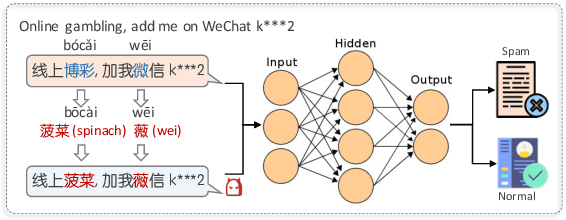



Despite of the superb performance on a wide range of tasks, pre-trained language models (e.g., BERT) have been proved vulnerable to adversarial texts. In this paper, we present RoChBERT, a framework to build more Robust BERT-based models by utilizing a more comprehensive adversarial graph to fuse Chinese phonetic and glyph features into pre-trained representations during fine-tuning. Inspired by curriculum learning, we further propose to augment the training dataset with adversarial texts in combination with intermediate samples. Extensive experiments demonstrate that RoChBERT outperforms previous methods in significant ways: (i) robust -- RoChBERT greatly improves the model robustness without sacrificing accuracy on benign texts. Specifically, the defense lowers the success rates of unlimited and limited attacks by 59.43% and 39.33% respectively, while remaining accuracy of 93.30%; (ii) flexible -- RoChBERT can easily extend to various language models to solve different downstream tasks with excellent performance; and (iii) efficient -- RoChBERT can be directly applied to the fine-tuning stage without pre-training language model from scratch, and the proposed data augmentation method is also low-cost.