 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoChBert: Towards Robust BERT Fine-tuning for Chinese
Paper and Code
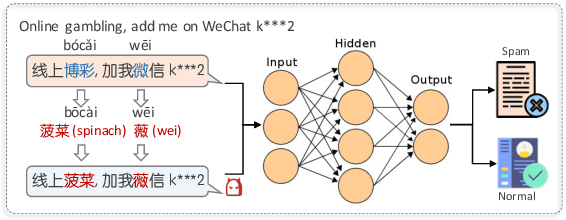



Despite of the superb performance on a wide range of tasks, pre-trained language models (e.g., BERT) have been proved vulnerable to adversarial texts. In this paper, we present RoChBERT, a framework to build more Robust BERT-based models by utilizing a more comprehensive adversarial graph to fuse Chinese phonetic and glyph features into pre-trained representations during fine-tuning. Inspired by curriculum learning, we further propose to augment the training dataset with adversarial texts in combination with intermediate samples. Extensive experiments demonstrate that RoChBERT outperforms previous methods in significant ways: (i) robust -- RoChBERT greatly improves the model robustness without sacrificing accuracy on benign texts. Specifically, the defense lowers the success rates of unlimited and limited attacks by 59.43% and 39.33% respectively, while remaining accuracy of 93.30%; (ii) flexible -- RoChBERT can easily extend to various language models to solve different downstream tasks with excellent performance; and (iii) efficient -- RoChBERT can be directly applied to the fine-tuning stage without pre-training language model from scratch, and the proposed data augmentation method is also low-cost.