 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Adversarial Arms Race to Model-centric Evaluation: Motivating a Unified Automatic Robustness Evaluation Framework
May 29, 2023



Textual adversarial attacks can discover models' weaknesses by adding semantic-preserved but misleading perturbations to the inputs. The long-lasting adversarial attack-and-defense arms race in Natural Language Processing (NLP) is algorithm-centric, providing valuable techniques for automatic robustness evaluation. However, the existing practice of robustness evaluation may exhibit issues of incomprehensive evaluation, impractical evaluation protocol, and invalid adversarial samples. In this paper, we aim to set up a unified automatic robustness evaluation framework, shifting towards model-centric evaluation to further exploit the advantages of adversarial attacks. To address the above challenges, we first determine robustness evaluation dimensions based on model capabilities and specify the reasonable algorithm to generate adversarial samples for each dimension. Then we establish the evaluation protocol, including evaluation settings and metrics, under realistic demands. Finally, we use the perturbation degree of adversarial samples to control the sample validity. We implement a toolkit RobTest that realizes our automatic robustness evaluation framework. In our experiments, we conduct a robustness evaluation of RoBERTa models to demonstrate the effectiveness of our evaluation framework, and further show the rationality of each component in the framework. The code will be made public at \url{https://github.com/thunlp/RobTest}.
Exploiting Heterogeneous Graph Neural Networks with Latent Worker/Task Correlation Information for Label Aggregation in Crowdsourcing
Oct 25, 2020
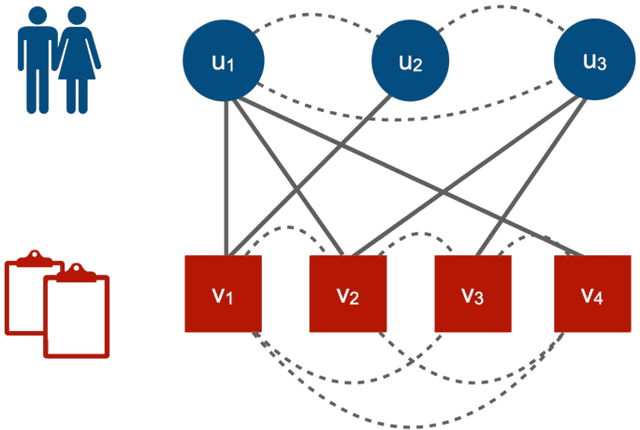
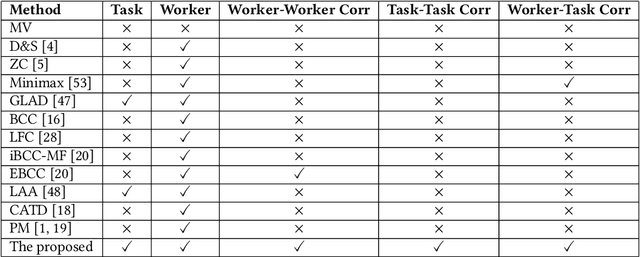

Crowdsourcing has attracted much attention for its convenience to collect labels from non-expert workers instead of experts. However, due to the high level of noise from the non-experts, an aggregation model that learns the true label by incorporating the source credibility is required. In this paper, we propose a novel framework based on graph neural networks for aggregating crowd labels. We construct a heterogeneous graph between workers and tasks and derive a new graph neural network to learn the representations of nodes and the true labels. Besides, we exploit the unknown latent interaction between the same type of nodes (workers or tasks) by adding a homogeneous attention layer in the graph neural networks. Experimental results on 13 real-world datasets show superior performance over state-of-the-art models.
Unsupervised Reference-Free Summary Quality Evaluation via Contrastive Learning
Oct 05, 2020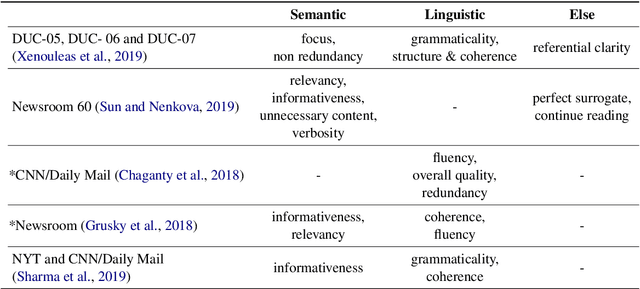
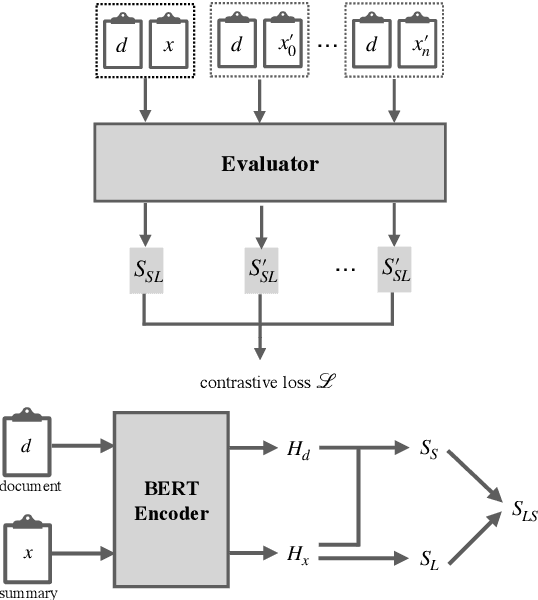
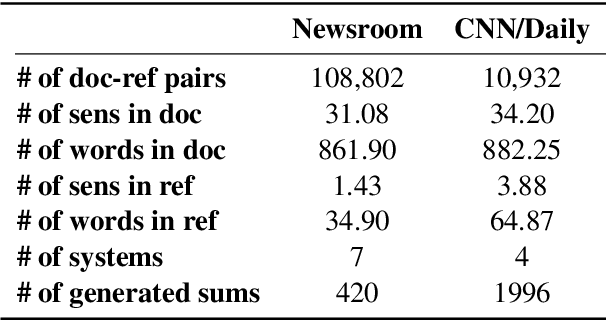
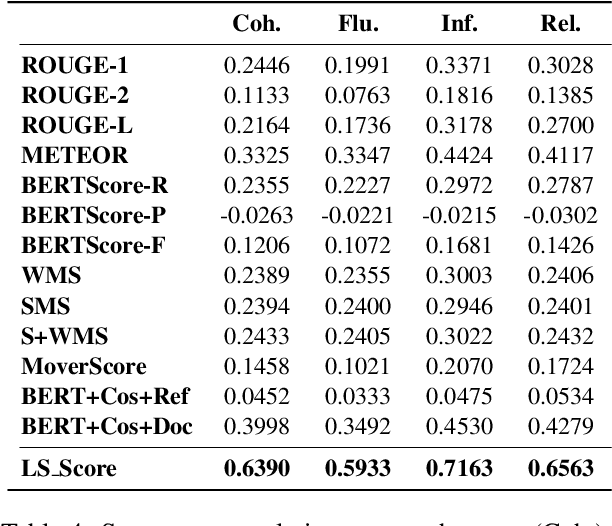
Evaluation of a document summarization system has been a critical factor to impact the success of the summarization task. Previous approaches, such as ROUGE, mainly consider the informativeness of the assessed summary and require human-generated references for each test summary. In this work, we propose to evaluate the summary qualities without reference summaries by unsupervised contrastive learning. Specifically, we design a new metric which covers both linguistic qualities and semantic informativeness based on BERT. To learn the metric, for each summary, we construct different types of negative samples with respect to different aspects of the summary qualities, and train our model with a ranking loss. Experiments on Newsroom and CNN/Daily Mail demonstrate that our new evaluation method outperforms other metrics even without reference summaries. Furthermore, we show that our method is general and transferable across datasets.