 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Persona Thinking for Bias Mitigation in Large Language Models
Jan 21, 2026Large Language Models (LLMs) exhibit significant social biases that can perpetuate harmful stereotypes and unfair outcomes. In this paper, we propose Multi-Persona Thinking (MPT), a novel inference-time framework that leverages dialectical reasoning from multiple perspectives to reduce bias. MPT guides models to adopt contrasting social identities (e.g., male and female) along with a neutral viewpoint, and then engages these personas iteratively to expose and correct biases. Through a dialectical reasoning process, the framework transforms the potential weakness of persona assignment into a strength for bias mitigation. We evaluate MPT on two widely used bias benchmarks across both open-source and closed-source models of varying scales. Our results demonstrate substantial improvements over existing prompting-based strategies: MPT achieves the lowest bias while maintaining core reasoning ability.
MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns
Nov 16, 2025Document parsing is a core task in document intelligence, supporting applications such as information extraction, retrieval-augmented generation, and automated document analysis. However, real-world documents often feature complex layouts with multi-level tables, embedded images or formulas, and cross-page structures, which remain challenging for existing OCR systems. We introduce MonkeyOCR v1.5, a unified vision-language framework that enhances both layout understanding and content recognition through a two-stage pipeline. The first stage employs a large multimodal model to jointly predict layout and reading order, leveraging visual information to ensure sequential consistency. The second stage performs localized recognition of text, formulas, and tables within detected regions, maintaining high visual fidelity while reducing error propagation. To address complex table structures, we propose a visual consistency-based reinforcement learning scheme that evaluates recognition quality via render-and-compare alignment, improving structural accuracy without manual annotations. Additionally, two specialized modules, Image-Decoupled Table Parsing and Type-Guided Table Merging, are introduced to enable reliable parsing of tables containing embedded images and reconstruction of tables crossing pages or columns. Comprehensive experiments on OmniDocBench v1.5 demonstrate that MonkeyOCR v1.5 achieves state-of-the-art performance, outperforming PPOCR-VL and MinerU 2.5 while showing exceptional robustness in visually complex document scenarios. A trial link can be found at https://github.com/Yuliang-Liu/MonkeyOCR .
ULPT: Prompt Tuning with Ultra-Low-Dimensional Optimization
Feb 06, 2025



Large language models achieve state-of-the-art performance but are costly to fine-tune due to their size. Parameter-efficient fine-tuning methods, such as prompt tuning, address this by reducing trainable parameters while maintaining strong performance. However, prior methods tie prompt embeddings to the model's dimensionality, which may not scale well with larger LLMs and more customized LLMs. In this paper, we propose Ultra-Low-dimensional Prompt Tuning (ULPT), which optimizes prompts in a low-dimensional space (e.g., 2D) and use a random but frozen matrix for the up-projection. To enhance alignment, we introduce learnable shift and scale embeddings. ULPT drastically reduces the trainable parameters, e.g., 2D only using 2% parameters compared with vanilla prompt tuning while retaining most of the performance across 21 NLP tasks. Our theoretical analysis shows that random projections can capture high-rank structures effectively, and experimental results demonstrate ULPT's competitive performance over existing parameter-efficient methods.
Cross-Modal Consistency in Multimodal Large Language Models
Nov 14, 2024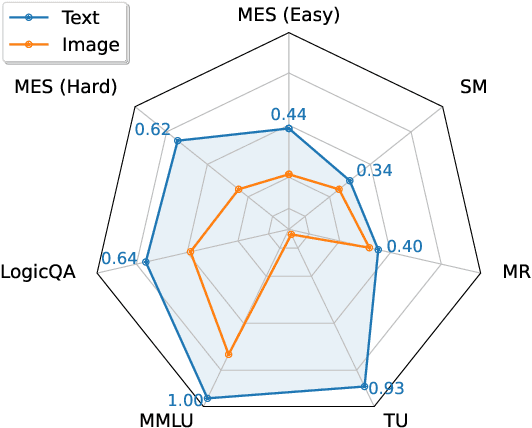



Recent developments in multimodal methodologies have marked the beginning of an exciting era for models adept at processing diverse data types, encompassing text, audio, and visual content. Models like GPT-4V, which merge computer vision with advanced language processing, exhibit extraordinary proficiency in handling intricate tasks that require a simultaneous understanding of both textual and visual information. Prior research efforts have meticulously evaluated the efficacy of these Vision Large Language Models (VLLMs) in various domains, including object detection, image captioning, and other related fields. However, existing analyses have often suffered from limitations, primarily centering on the isolated evaluation of each modality's performance while neglecting to explore their intricate cross-modal interactions. Specifically, the question of whether these models achieve the same level of accuracy when confronted with identical task instances across different modalities remains unanswered. In this study, we take the initiative to delve into the interaction and comparison among these modalities of interest by introducing a novel concept termed cross-modal consistency. Furthermore, we propose a quantitative evaluation framework founded on this concept. Our experimental findings, drawn from a curated collection of parallel vision-language datasets developed by us, unveil a pronounced inconsistency between the vision and language modalities within GPT-4V, despite its portrayal as a unified multimodal model. Our research yields insights into the appropriate utilization of such models and hints at potential avenues for enhancing their design.
SASE: A Searching Architecture for Squeeze and Excitation Operations
Nov 13, 2024In the past few years, channel-wise and spatial-wise attention blocks have been widely adopted as supplementary modules in deep neural networks, enhancing network representational abilities while introducing low complexity. Most attention modules follow a squeeze-and-excitation paradigm. However, to design such attention modules, requires a substantial amount of experiments and computational resources. Neural Architecture Search (NAS), meanwhile, is able to automate the design of neural networks and spares the numerous experiments required for an optimal architecture. This motivates us to design a search architecture that can automatically find near-optimal attention modules through NAS. We propose SASE, a Searching Architecture for Squeeze and Excitation operations, to form a plug-and-play attention block by searching within certain search space. The search space is separated into 4 different sets, each corresponds to the squeeze or excitation operation along the channel or spatial dimension. Additionally, the search sets include not only existing attention blocks but also other operations that have not been utilized in attention mechanisms before. To the best of our knowledge, SASE is the first attempt to subdivide the attention search space and search for architectures beyond currently known attention modules. The searched attention module is tested with extensive experiments across a range of visual tasks. Experimental results indicate that visual backbone networks (ResNet-50/101) using the SASE attention module achieved the best performance compared to those using the current state-of-the-art attention modules. Codes are included in the supplementary material, and they will be made public later.
Reducing Distraction in Long-Context Language Models by Focused Learning
Nov 08, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced their capacity to process long contexts. However, effectively utilizing this long context remains a challenge due to the issue of distraction, where irrelevant information dominates lengthy contexts, causing LLMs to lose focus on the most relevant segments. To address this, we propose a novel training method that enhances LLMs' ability to discern relevant information through a unique combination of retrieval-based data augmentation and contrastive learning. Specifically, during fine-tuning with long contexts, we employ a retriever to extract the most relevant segments, serving as augmented inputs. We then introduce an auxiliary contrastive learning objective to explicitly ensure that outputs from the original context and the retrieved sub-context are closely aligned. Extensive experiments on long single-document and multi-document QA benchmarks demonstrate the effectiveness of our proposed method.
Action Controlled Paraphrasing
May 18, 2024



Recent studies have demonstrated the potential to control paraphrase generation, such as through syntax, which has broad applications in various downstream tasks. However, these methods often require detailed parse trees or syntactic exemplars, which are not user-friendly. Furthermore, an inference gap exists, as control specifications are only available during training but not inference. In this work, we propose a new setup for controlled paraphrasing. Specifically, we represent user-intended actions as action tokens, allowing embedding and concatenating them with text embeddings, thus flowing together to a self-attention encoder for representation fusion. To address the inference gap, we introduce an optional action token as a placeholder that encourages the model to determine the appropriate action when control specifications are inaccessible. Experimental results show that our method successfully enables specific action-controlled paraphrasing and preserves the same or even better performance compared to conventional uncontrolled methods when actions are not given. Our findings thus promote the concept of optional action control for a more user-centered design via representation learning.
Lost in Translation: When GPT-4V Can't See Eye to Eye with Text. A Vision-Language-Consistency Analysis of VLLMs and Beyond
Oct 19, 2023Recent advancements in multimodal techniques open exciting possibilities for models excelling in diverse tasks involving text, audio, and image processing. Models like GPT-4V, blending computer vision and language modeling, excel in complex text and image tasks. Numerous prior research endeavors have diligently examined the performance of these Vision Large Language Models (VLLMs) across tasks like object detection, image captioning and others. However, these analyses often focus on evaluating the performance of each modality in isolation, lacking insights into their cross-modal interactions. Specifically, questions concerning whether these vision-language models execute vision and language tasks consistently or independently have remained unanswered. In this study, we draw inspiration from recent investigations into multilingualism and conduct a comprehensive analysis of model's cross-modal interactions. We introduce a systematic framework that quantifies the capability disparities between different modalities in the multi-modal setting and provide a set of datasets designed for these evaluations. Our findings reveal that models like GPT-4V tend to perform consistently modalities when the tasks are relatively simple. However, the trustworthiness of results derived from the vision modality diminishes as the tasks become more challenging. Expanding on our findings, we introduce "Vision Description Prompting," a method that effectively improves performance in challenging vision-related tasks.
Zero-Shot Continuous Prompt Transfer: Generalizing Task Semantics Across Language Models
Oct 02, 2023



Prompt tuning in natural language processing (NLP) has become an increasingly popular method for adapting large language models to specific tasks. However, the transferability of these prompts, especially continuous prompts, between different models remains a challenge. In this work, we propose a zero-shot continuous prompt transfer method, where source prompts are encoded into relative space and the corresponding target prompts are searched for transferring to target models. Experimental results confirm the effectiveness of our method, showing that 'task semantics' in continuous prompts can be generalized across various language models. Moreover, we find that combining 'task semantics' from multiple source models can further enhance the generalizability of transfer.
Unsupervised Chunking with Hierarchical RNN
Sep 10, 2023



In Natural Language Processing (NLP), predicting linguistic structures, such as parsing and chunking, has mostly relied on manual annotations of syntactic structures. This paper introduces an unsupervised approach to chunking, a syntactic task that involves grouping words in a non-hierarchical manner. We present a two-layer Hierarchical Recurrent Neural Network (HRNN) designed to model word-to-chunk and chunk-to-sentence compositions. Our approach involves a two-stage training process: pretraining with an unsupervised parser and finetuning on downstream NLP tasks. Experiments on the CoNLL-2000 dataset reveal a notable improvement over existing unsupervised methods, enhancing phrase F1 score by up to 6 percentage points. Further, finetuning with downstream tasks results in an additional performance improvement. Interestingly, we observe that the emergence of the chunking structure is transient during the neural model's downstream-task training. This study contributes to the advancement of unsupervised syntactic structure discovery and opens avenues for further research in linguistic theory.