 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Through the Haze: An Advanced Non-Homogeneous Dehazing Method based on Fast Fourier Convolution and ConvNeXt
May 08, 2023Haze usually leads to deteriorated images with low contrast, color shift and structural distortion. We observe that many deep learning based models exhibit exceptional performance on removing homogeneous haze, but they usually fail to address the challenge of non-homogeneous dehazing. Two main factors account for this situation. Firstly, due to the intricate and non uniform distribution of dense haze, the recovery of structural and chromatic features with high fidelity is challenging, particularly in regions with heavy haze. Secondly, the existing small scale datasets for non-homogeneous dehazing are inadequate to support reliable learning of feature mappings between hazy images and their corresponding haze-free counterparts by convolutional neural network (CNN)-based models. To tackle these two challenges, we propose a novel two branch network that leverages 2D discrete wavelete transform (DWT), fast Fourier convolution (FFC) residual block and a pretrained ConvNeXt model. Specifically, in the DWT-FFC frequency branch, our model exploits DWT to capture more high-frequency features. Moreover, by taking advantage of the large receptive field provided by FFC residual blocks, our model is able to effectively explore global contextual information and produce images with better perceptual quality. In the prior knowledge branch, an ImageNet pretrained ConvNeXt as opposed to Res2Net is adopted. This enables our model to learn more supplementary information and acquire a stronger generalization ability. The feasibility and effectiveness of the proposed method is demonstrated via extensive experiments and ablation studies. The code is available at https://github.com/zhouh115/DWT-FFC.
A Data-Centric Solution to NonHomogeneous Dehazing via Vision Transformer
Apr 18, 2023



Recent years have witnessed an increased interest in image dehazing. Many deep learning methods have been proposed to tackle this challenge, and have made significant accomplishments dealing with homogeneous haze. However, these solutions cannot maintain comparable performance when they are applied to images with non-homogeneous haze, e.g., NH-HAZE23 dataset introduced by NTIRE challenges. One of the reasons for such failures is that non-homogeneous haze does not obey one of the assumptions that is required for modeling homogeneous haze. In addition, a large number of pairs of non-homogeneous hazy image and the clean counterpart is required using traditional end-to-end training approaches, while NH-HAZE23 dataset is of limited quantities. Although it is possible to augment the NH-HAZE23 dataset by leveraging other non-homogeneous dehazing datasets, we observe that it is necessary to design a proper data-preprocessing approach that reduces the distribution gaps between the target dataset and the augmented one. This finding indeed aligns with the essence of data-centric AI. With a novel network architecture and a principled data-preprocessing approach that systematically enhances data quality, we present an innovative dehazing method. Specifically, we apply RGB-channel-wise transformations on the augmented datasets, and incorporate the state-of-the-art transformers as the backbone in the two-branch framework. We conduct extensive experiments and ablation study to demonstrate the effectiveness of our proposed method.
M22: A Communication-Efficient Algorithm for Federated Learning Inspired by Rate-Distortion
Jan 23, 2023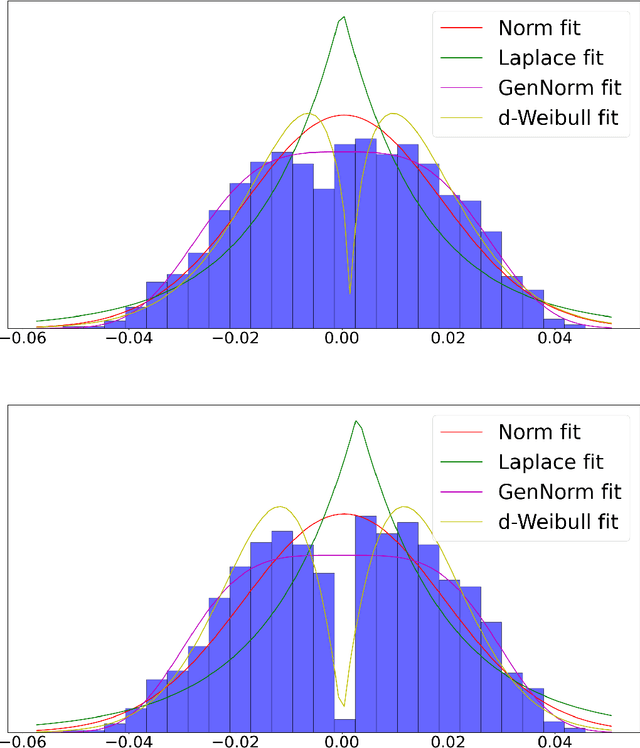
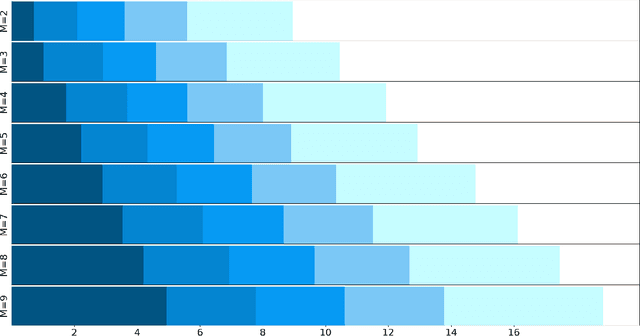
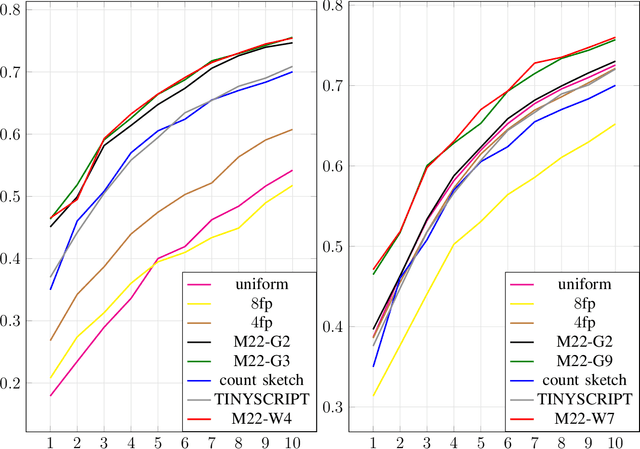
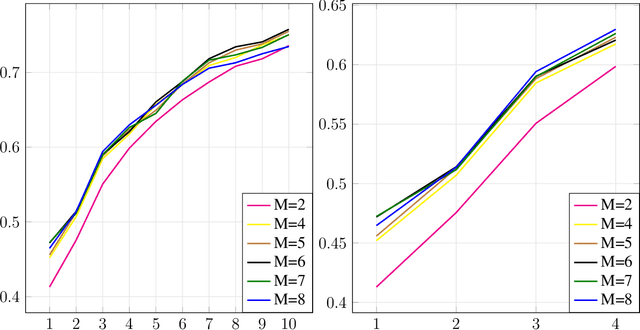
In federated learning (FL), the communication constraint between the remote learners and the Parameter Server (PS) is a crucial bottleneck. For this reason, model updates must be compressed so as to minimize the loss in accuracy resulting from the communication constraint. This paper proposes ``\emph{${\bf M}$-magnitude weighted $L_{\bf 2}$ distortion + $\bf 2$ degrees of freedom''} (M22) algorithm, a rate-distortion inspired approach to gradient compression for federated training of deep neural networks (DNNs). In particular, we propose a family of distortion measures between the original gradient and the reconstruction we referred to as ``$M$-magnitude weighted $L_2$'' distortion, and we assume that gradient updates follow an i.i.d. distribution -- generalized normal or Weibull, which have two degrees of freedom. In both the distortion measure and the gradient, there is one free parameter for each that can be fitted as a function of the iteration number. Given a choice of gradient distribution and distortion measure, we design the quantizer minimizing the expected distortion in gradient reconstruction. To measure the gradient compression performance under a communication constraint, we define the \emph{per-bit accuracy} as the optimal improvement in accuracy that one bit of communication brings to the centralized model over the training period. Using this performance measure, we systematically benchmark the choice of gradient distribution and distortion measure. We provide substantial insights on the role of these choices and argue that significant performance improvements can be attained using such a rate-distortion inspired compressor.